how to use
cassandra是一個無主架構,多個node可以并行寫,但并發場景下對于先讀後寫的操作,資料會有正确性問題。從cassandra2 開始提供輕量級事務支援,用于cas更新。使用示例:
cqlsh> UPDATE cycling.cyclist_name
SET firstname = ‘Roxane’
WHERE id = 4647f6d3-7bd2-4085-8d6c-1229351b5498
IF firstname = ‘Roxxane’; 這其實是一個标準的compare and swap 示例。接下來我們深入看看cassandra是如何實作的,其實我們可以發現,其實它既沒有事務,也不輕量級。
理論基礎
cassandra輕量級事務是通過basic-paxos協定實作的,提供線性化一緻性保證,具體的理論基礎可以參考
paxos made simple。建議讀者先深入了解該論文。
論文講述得出一個值,主要有兩個階段prepair+accept,大體流程見下圖:
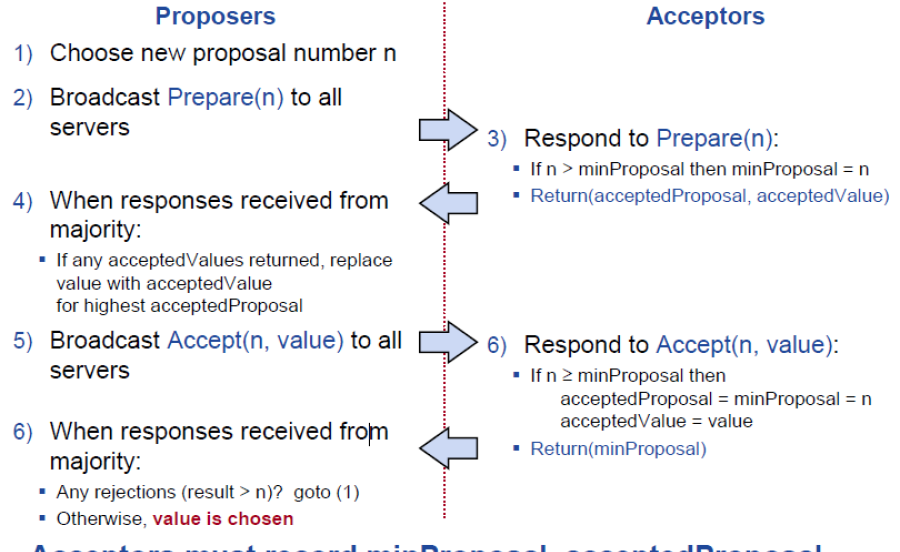
Cassandra LightWeight Transaction paxos實作在原來的二階段perpair, propose/accept上增加了commit階段,論文中對于如何 Learning a Chosen Value的描述,工程化實作不太靠譜,常見的做法如下:
一個提案是否被chosen,acceptor是不知道的,隻有proposer知道是否滿足多數派,如果滿足了,增加commit階段,在該階段,把已經chosen的提案提告知learner,learner更新自身狀态機。
cassandra 實作
工程實作跟理論還是有些gap的,basic paxos最大的問題是隻是用來表決出一個值,但cassandra cas需要持續寫入多輪(論文中instance)值,cassandra是在prepare階段,發現上一輪已經正常commit了,即可開始下一輪,提議新的值。
cassandra使用basic paxos本質上為所有的cas請求申請槽位(slot),保證所有請求線性一緻性,不會出現replica A執行了op1->op2,而replica B執行了op2->op1這種不一緻的結果。
變量介紹
-
ballot: 提案号,proposer保證線性單調增長,在c*裡面使用時間戳表示。
每個node(acceptor)都有如下三個本地變量:
- in_progress_ballot: prepair 階段proposer提案号,acceptor 發現隻要比自己本地的大,會promise然後更新該本地變量,簡稱為promised ballot,代碼中使用in_progress_ballot儲存
- proposal_ballot: propose階段,proposer提案号,如果比acceptor已經promise的ballot(上述in_progress_ballot)大的話,acceptor會accept該提案,并把提案中的value持久化。
- most_recent_commit_at: proposer提案被多數派acceptor接受後,該value被chosen,proposer向learner發送commit消息,commit消息無論如何都會被接受,持久化到磁盤上,most_recent_commit_at是這個決議commit時間。有時簡稱為commit ballot
實作流程

共四個階段
- Prepare/Promise
- 産生一個ballot,向replica 發送prepare請求,replica答應不會接受舊的ballot更新,并且告知最後accept 提案及最近commit提案。
- 如果最後accept提案比最近commit提案新,說明該accept提案還沒有走完整個流程,也許後端節點故障導緻的。coordinate重新發起propose+commit請求,跳至步驟3,4,結束上輪未完提案後,可開始本輪自己的新提案
- 如果最近commit提案都比accept提案新, 說明沒有還處于流程中的提案,可直接開始本輪自己的新提案。
- Read/Results
- 從replica讀取資料,一緻性級别為Quorum或者Local_Quorum
- 讀取完判斷是否滿足condition條件,将上述cql更新變成mutation, 作為提案的值,進入下面的propose/accept階段。
- Propose/Accept
- 向所有replica發送propose 提案,proposal_ballot必須比replica本地in_progress_ballot高,高的話,給cordinate回複
- ack,并持久化在system.paxos表,否則說明replica本地in_progress_ballot更高,代表其他cordinate發送了更新的prepare提案,給目前cordinate回複reject ack。
-
Commit/Acknowledge
如果多數派replica接受了這個提案,我們進入commit,像learner(cassandra中的replica)發起commit請求
- cordinate向所有replica發送一條commit消息,消息包含ballot&value
-
因為前面2步的關系,這一定是最高的可見的commit ballot,後續新的paxos階段promise響應也會回複此新值。
commit階段首先相應的表(columnFamily)會apply 這條mutation,然後做清理, 會将proposal_ballot,及proposal value置空,辨別本輪paxos正常結束。
詳細代碼請閱讀StorageProxy.cas()
LightWeight Transaction 問題
輕量級事務是比較費的,由上面的流程可以看出,正常流程需要4次 RTT,如果發生“活鎖”沖突,多個cordinator同時改同一partitionKey,propose 提案會不斷被reject,c* 的解決辦法是随機睡眠一段時間重試,但帶來的問題是線程并發度越高,競争越激烈,寫失敗機率越大,分位延時越大。下圖99分位寫延時能到200ms以上,社群也是不太建議大面積廣泛使用cas。
摘自:
https://www.slideshare.net/DataStax/light-weight-transactions-under-stress-christopher-batey-the-last-pickle-cassandra-summit-2016但作為資料庫,read-before-write是業務系統非常常見的需求,cassandra隻能原子寫,給我們使用帶來很多不便。對于cas性能短闆,那麼如何改進呢?業界常見的有這麼些做法
- leader模式:如raft,multi-paxos,先選出唯一主,不會有提案的contention,每個寫請求都是phase2 accept請求,commit可以異步,這樣大大降低了4輪的rpc,可縮減到一跳rpc
- leaderless模式,改進的paxos,如epaxos,無主跟cassandra相性更相容,社群後續改進思路就是講basic-paxos實作改為epaxos,下面我們将花些時間了解一下epaxos
社群改進方向及進展
CASSANDRA-6246, 社群打算使用epaxos做cas優化,将在4.x合入,但該ISSUE已經open了數年,預期進展不會太過樂觀,讀者了解epaxos原理後,可自行實作改進。
epaxos論文:
Egalitarian PaxosEpaxos介紹
EPaxos用到的幾個概念
在描述前,先描述幾個概念。
在EPaxos中,每一個command γ都附帶attribute,其中包括deps和seq。deps記錄了跟γ沖突的command的instance id,γ依賴這些instance id對應的command。deps中維護的依賴關系就是定序用的關系,γ要排在deps中 的command後面。seq是一個序列号,用來在execution階段打破循環依賴。
接收client請求的副本稱之為這個command γ的command leader,記作Lγ。每個副本都會持久化記錄到cmds中,通過Q.i這種instance id來索引并讀寫。
協定分成兩個部分,首先是正常處理用戶端請求的處理過程,這個過程包括三個階段:(1) Phase1 Establish ordering constraints (2) Paxos-Accept Phase (3) Commit Phase。其中一個指令可能走Phase1 + Paxos-Accept Phase + Commit Phase,或者Phase 1 + Commit Phase,前者稱之為slow path,後者稱之為fast path。
需要提前指明的是,優化EPaxos采用的是thrifty模式,fast quorum是 F'=F+⌊(F+1)/2⌋,其中F為系統容忍的少數派,command leader向 F' 個副本發送pre-accept請求,而不是向 2F+1 個副本發送請求等待 F'個回應。
協定詳細介紹
恢複階段Explicit Prepare
副本Q懷疑L失效,嘗試去恢複L.i這個instance。
- 遞增ballot number:設Q知道的最大proposal id是epoch.b.Q,則使用新的proposal id epoch.(b+1).Q
- 向所有副本(包括自己)發送Prepare(epoch.(b+1).Q),等待至少多數派的回應。
- 假設所有回應中最大ballot number的是ballotmax,定義R是所有回應中ballot number等于ballotmax的響應的集合。
- 如果R沒有關于這個instance id的任何資訊,那麼推出恢複階段,副本Q對L.i執行個體嘗試去commit no-op。
- 如果R中包含了至少一條(γ,seqγ,depsγ,committed),則對L.i執行個體(γ,seqγ,depsγ)執行Commit Phase。
- 如果R中包含了至少一條(γ,seqγ,depsγ,accept),則對L.i執行個體(γ,seqγ,depsγ)執行Paxos-Accept Phase。
- 如果至少(F+1)/2個副本回應了pre-accept,并且它們回應的seqγ,depsγ都與L.i的epoch.0.b那輪PreAccept請求中記錄相同,那麼就進入TryPreAccept階段,否則就回到slow path重新來一遍commit。
TryPreAccept階段
副本Q發送TryPreAccept(L.i,γ,depsγ,seqγ)給中未回應過pre-accept response的副本。
- 副本R收到TryPreAccept(L.i,γ,depsγ,seqγ)之後,如果R現在記錄了command δ,同時滿足如下三個條件:
- γ~δ
- γ∉depsδ
-
δ∉depsγ 或者 δ∈depsγandseqδ≤seqγ
就回應NACK,并帶上沖突command的一些資訊(包括δ的instance id、command leader、instance的狀态如pre-accepted/accepted/committed),否則就回應ACK。
- 副本Q在收到TryPreAccept的響應之後,順序進行如下的條件判斷:
- 如果pre-accepted的副本數目已經大于等于F+1,則Q退出恢複過程,開始對L.i執行個體γ,depsγ,seqγ 執行Paxos-Accept階段。
- 如果某個TryPreAccept NACK中回報了存在一個已經committed的沖突command,則退出恢複階段,從頭開始slow path來在L.i執行個體上重新嘗試送出γ。
- 如果某個TryPreAccept NACK中回報了一個執行個體δ,其中δ∉depsγ并且Lγ∈γ,則退出恢複階段,從頭開始slow path來在L.i執行個體上重新嘗試送出γ。
- 如果存在command γ0,Q是先嘗試恢複γ0,但因為發現可能需要先恢複跟γ0沖突的γ。在這種情況下,如果發現γ0的command leader是γ的fast quorum中的一個,那麼就退出γ的恢複,從頭開始slow path來重新送出γ。
- 如果前面的條件都不滿足,Q就推遲defer γ的恢複,先恢複與γ沖突的某個command。
## 優點
-
leaderless,負載更均衡,對于raft,multi-paxos存在leader的bottleneck,epaxos不存在這個問題
無主模式還有一個非常大的優點,延時更穩定,集中式主模式往往因為主當機,從需要搶主,重新提供服務,導緻延時陡增,像epaxos,每輪消息任何副本都可以當主,挂了一台無所謂,延時穩定,更适合線上服務。
-
延時優化,無沖突情況下,能優化目前cas實作 4輪rpc至2輪rpc,preAcept+commit,commit還可以異步發送,不同步等ack。
就算較之于論文basic-paxos(3輪rpc)也是路徑較優,當然略遜于raft/multi-paxos,畢竟一輪rpc。
- 缺點:epaxos比paxos複雜多了,不過好在于作者提供了go實作的原型,見代碼庫 https://github.com/efficient/epaxos ,
- 延時肯定是比multi-paxos強主模式差的
性能
參考論文第12頁,需要指出的是epaxos延時跟multi-paxos對比,作者盡挑對自己有利的說,需要明确指出同機房下epaxos延時比paxos差的,比如在CA地域。