文章首發于我的個人部落格,到個人部落格體驗更佳閱讀哦
https://www.itqiankun.com/article/1565747019
寫到這裡,分布式Id算是寫到最後一篇了,在這一篇裡,我會講到目前網上最适合分布式Id的方法,什麼方法呢,請您往下看:
介紹Snowflake算法
SnowFlake算法是國際大公司Twitter的采用的一種生成分布式自增id的政策,這個算法産生的分布式id是足夠我們我們中小公司在日常裡面的使用了。我也是比較推薦這一種算法産生的分布式id的。
算法snowflake的生成的分布式id結構組成部分
算法snowflake生成id的結果是一個64bit大小的整數,它的結構如下圖,
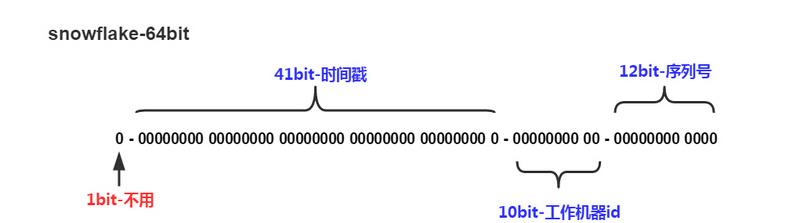
這裡我麼來講一下這個結構:首先因為window是64位的,然後整數的時候第一位必須是0,是以最大的數值就是63位的111111111111111111111111111111111111111111111111111111111111111,然後呢Snowflake算法分出來41位作為毫秒值,然後10位作為redis節點的數量,然後12位做成redis節點在每一毫秒的自增序列值
41位的二進制11111111111111111111111111111111111111111轉換成10進制的毫秒就是2199023255551,然後我們把 2199023255551轉換成時間就是2039-09-07,也就是說可以用20年的(這裡在網上會有很多說是可以使用69年的,他們說69年的也對,因為1970年+69年的結果就是2039年,但是如果從今年2019年來說,也就隻能用20年了)
然後10位作為節點,是以最多就是12位的1111111111,也就是最多可以支援1023個節點,
然後10位表示每一個節點自增序列值,這裡最多就是10位的111111111111,也就是說每一個節點可以每一毫秒可以最多生成4059個不重複id值
由于在Java中64bit的整數是long類型,是以在Java中SnowFlake算法生成的id就是long來存儲的。
Java實作Snowflake算法的源碼
Snowflake算法的源碼如下所示(這個是我從網上找到的),這裡我進行了測試了一波,結果如下所示
package com.hello;
import java.text.SimpleDateFormat;
import java.util.Date;
public class Test {
/**
* 開始時間截 (1970-01-01)
*/
private final long twepoch = 0L;
/**
* 機器id所占的位數
*/
private final long workerIdBits = 5L;
/**
* 資料辨別id所占的位數
*/
private final long datacenterIdBits = 5L;
/**
* 支援的最大機器id,結果是31 (這個移位算法可以很快的計算出幾位二進制數所能表示的最大十進制數)
*/
private final long maxWorkerId = -1L ^ (-1L << workerIdBits);
/**
* 支援的最大資料辨別id,結果是31
*/
private final long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);
/**
* 序列在id中占的位數
*/
private final long sequenceBits = 12L;
/**
* 機器ID向左移12位
*/
private final long workerIdShift = sequenceBits;
/**
* 資料辨別id向左移17位(12+5)
*/
private final long datacenterIdShift = sequenceBits + workerIdBits;
/**
* 時間截向左移22位(5+5+12)
*/
private final long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;
/**
* 生成序列的掩碼,這裡為4095 (0b111111111111=0xfff=4095)
*/
private final long sequenceMask = -1L ^ (-1L << sequenceBits);
/**
* 工作機器ID(0~31)
*/
private long workerId;
/**
* 資料中心ID(0~31)
*/
private long datacenterId;
/**
* 毫秒内序列(0~4095)
*/
private long sequence = 0L;
/**
* 上次生成ID的時間截
*/
private long lastTimestamp = -1L;
public Test(long workerId, long datacenterId) {
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0", maxWorkerId));
}
if (datacenterId > maxDatacenterId || datacenterId < 0) {
throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0", maxDatacenterId));
}
this.workerId = workerId;
this.datacenterId = datacenterId;
}
/**
* 獲得下一個ID (該方法是線程安全的)
*
* @return SnowflakeId
*/
public synchronized long nextId() {
long timestamp = timeGen();
//如果目前時間小于上一次ID生成的時間戳,說明系統時鐘回退過這個時候應當抛出異常
if (timestamp < lastTimestamp) {
throw new RuntimeException(
String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));
}
//如果是同一時間生成的,則進行毫秒内序列
if (lastTimestamp == timestamp) {
sequence = (sequence + 1) & sequenceMask;
//毫秒内序列溢出
if (sequence == 0) {
//阻塞到下一個毫秒,獲得新的時間戳
timestamp = tilNextMillis(lastTimestamp);
}
}
//時間戳改變,毫秒内序列重置
else {
sequence = 0L;
}
//上次生成ID的時間截
lastTimestamp = timestamp;
//移位并通過或運算拼到一起組成64位的ID
return ((timestamp - twepoch) << timestampLeftShift) //
| (datacenterId << datacenterIdShift) //
| (workerId << workerIdShift) //
| sequence;
}
/**
* 阻塞到下一個毫秒,直到獲得新的時間戳
*
* @param lastTimestamp 上次生成ID的時間截
* @return 目前時間戳
*/
protected long tilNextMillis(long lastTimestamp) {
long timestamp = timeGen();
while (timestamp <= lastTimestamp) {
timestamp = timeGen();
}
return timestamp;
}
/**
* 傳回以毫秒為機關的目前時間
*
* @return 目前時間(毫秒)
*/
protected long timeGen() {
return System.currentTimeMillis();
}
public static void parseId(long id) {
long miliSecond = id >>> 22;
long shardId = (id & (0xFFF << 10)) >> 10;
System.err.println("分布式id-"+id+"生成的時間是:"+new SimpleDateFormat("yyyy-MM-dd").format(new Date(miliSecond)));
}
public static void main(String[] args) {
Test idWorker = new Test(0, 0);
for (int i = 0; i < 10; i++) {
long id = idWorker.nextId();
System.out.println(id);
parseId(id);
}
}
} 執行結果如下所示,此時我們可以看到,不僅可以可以把分布式id給建立處理,而且可以把這個建立的時間也列印出來,此時就可以滿足我們的分布式id的建立了
6566884785623400448
分布式id-6566884785623400448生成的時間是:2019-08-13
6566884785812144128
分布式id-6566884785812144128生成的時間是:2019-08-13
6566884785812144129
分布式id-6566884785812144129生成的時間是:2019-08-13
6566884785812144130
分布式id-6566884785812144130生成的時間是:2019-08-13
6566884785812144131
分布式id-6566884785812144131生成的時間是:2019-08-13
6566884785812144132
分布式id-6566884785812144132生成的時間是:2019-08-13
6566884785816338432
分布式id-6566884785816338432生成的時間是:2019-08-13
6566884785816338433
分布式id-6566884785816338433生成的時間是:2019-08-13
6566884785816338434
分布式id-6566884785816338434生成的時間是:2019-08-13
6566884785816338435
分布式id-6566884785816338435生成的時間是:2019-08-13 縮小版Snowflake算法生成分布式id
因為Snowflake算法的極限是每毫秒的每一個節點生成4059個id值,也就是說每毫秒的極限是生成023*4059=4 152 357個id值,這樣生成id值的速度對于twitter公司來說是很符合标準的(畢竟人家公司大嘛),但是對于咱們中小公司來說是不需要的,是以我們可以根據Snowflake算法來修改一下分布式id的建立,讓每秒建立的id少一些,但是把可以使用的時間擴大一些
這裡我看廖雪峰老師的文章之後,采用了53位作為分布式id值的位數,因為如果後端和前端的JavaScript打交道的話,由于JavaScript支援的最大整型就是53位,超過這個位數,JavaScript将丢失精度。是以,使用53位整數可以直接由JavaScript讀取,而超過53位時,就必須轉換成字元串才能保證JavaScript處理正确,是以我們的分布式id就用53位來生成
這53位裡面,第一位還是0,然後剩下的52位,33位作為秒數,4位作為節點數,15位作為每一個節點在每一秒的生成序列值
33位的二進制111111111111111111111111111111111轉換成10進制的秒就是8589934591,然後我們把 8589934591轉換成時間就是2242-03-16,也就是說可以用220年的,足夠我們的使用了
然後4位節點,是以最多就是4位的1111,也就是最多可以支援15個節點,
然後15位表示每一個節點每一秒自增序列值,這裡最多就是10位的11111111111111111,也就是說每一個節點可以每一秒可以最多生成131071個不重複id值
這樣算起來,就是說每一秒每一個節點生成131071個不重複的節點,是以極限就是每秒生成15*131071=1 966 065個分布式id,夠我們在開發裡面的日常使用了
是以代碼就可以變成下面這樣,這裡主要講一下下面的nextId()方法,
首先藍色代碼是擷取目前秒,然後進行校驗,就是把目前時間和上一個時間戳進行比較,如果目前時間比上一個時間戳要小,那就說明系統時鐘回退,是以此時應該抛出異常
然後是下面的紅色代碼,首先如果是同一秒生成的,那麼就把這一秒的生成序列id值一直增加,一直增加到131071個,如果在增加,那麼下面的紅色代碼裡面的sequence = (sequence + 1) & sequenceMask;的值就會是0,那麼就會執行紅色代碼裡面的tilNextMillis()方法進行阻塞,直到擷取到下一秒繼續執行
然後下面的綠色代碼表示每一秒過去之後,都要把這個生成序列的id值都變成0,這樣在新的一秒裡面就可以在繼續生成1到131071個分布式id值了
然後下面的黃色代碼就是把咱們的秒,節點值,節點每秒生成序列id值加起來組成一個分布式id傳回
package com.hello;
import java.text.SimpleDateFormat;
import java.util.Date;
public class Test {
/**
* 開始時間截 (1970-01-01)
*/
private final long twepoch = 0L;
/**
* 機器id,範圍是1到15
*/
private final long workerId;
/**
* 機器id所占的位數,占4位
*/
private final long workerIdBits = 4L;
/**
* 支援的最大機器id,結果是15
*/
private final long maxWorkerId = ~(-1L << workerIdBits);
/**
* 生成序列占的位數
*/
private final long sequenceBits = 15L;
/**
* 機器ID向左移15位
*/
private final long workerIdShift = sequenceBits;
/**
* 生成序列的掩碼,這裡為最大是32767 (1111111111111=32767)
*/
private final long sequenceMask = ~(-1L << sequenceBits);
/**
* 時間截向左移19位(4+15)
*/
private final long timestampLeftShift = 19L;
/**
* 秒内序列(0~32767)
*/
private long sequence = 0L;
/**
* 上次生成ID的時間截
*/
private long lastTimestamp = -1L;
public Test(long workerId) {
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0", maxWorkerId));
}
this.workerId = workerId;
}
/**
* 獲得下一個ID (該方法是線程安全的)
*
* @return SnowflakeId
*/
public synchronized long nextId() {
//藍色代碼注釋開始
long timestamp = timeGen();
//如果目前時間小于上一次ID生成的時間戳,說明系統時鐘回退過這個時候應當抛出異常
if (timestamp < lastTimestamp) {
throw new RuntimeException(
String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));
}
//藍色代碼注釋結束
//紅色代碼注釋開始
//如果是同一時間生成的,則進行秒内序列
if (lastTimestamp == timestamp) {
sequence = (sequence + 1) & sequenceMask;
//秒内序列溢出
if (sequence == 0) {
//阻塞到下一個秒,獲得新的秒值
timestamp = tilNextMillis(lastTimestamp);
}
//時間戳改變,秒内序列重置
}
//紅色代碼注釋結束
//綠色代碼注釋開始
else {
sequence = 0L;
}
//綠色代碼注釋結束
//上次生成ID的時間截
lastTimestamp = timestamp;
//黃色代碼注釋開始
//移位并通過或運算拼到一起組成53 位的ID
return ((timestamp - twepoch) << timestampLeftShift)
| (workerId << workerIdShift)
| sequence;
//黃色代碼注釋結束
}
/**
* 阻塞到下一個秒,直到獲得新的時間戳
*
* @param lastTimestamp 上次生成ID的時間截
* @return 目前時間戳
*/
protected long tilNextMillis(long lastTimestamp) {
long timestamp = timeGen();
while (timestamp <= lastTimestamp) {
timestamp = timeGen();
}
return timestamp;
}
/**
* 傳回以秒為機關的目前時間
*
* @return 目前時間(秒)
*/
protected long timeGen() {
return System.currentTimeMillis()/1000L;
}
public static void parseId(long id) {
long second = id >>> 19;
System.err.println("分布式id-"+id+"生成的時間是:"+new SimpleDateFormat("yyyy-MM-dd").format(new Date(second*1000)));
}
public static void main(String[] args) {
Test idWorker = new Test(0);
for (int i = 0; i < 10; i++) {
long id = idWorker.nextId();
System.out.println(id);
parseId(id);
}
}
} 此時結果如下所示,都是ok的,؏؏ᖗ乛◡乛ᖘ؏؏
820870564020224
分布式id-820870564020224生成的時間是:2019-08-13
820870564020225
分布式id-820870564020225生成的時間是:2019-08-13
820870564020226
分布式id-820870564020226生成的時間是:2019-08-13
820870564020227
分布式id-820870564020227生成的時間是:2019-08-13
820870564020228
分布式id-820870564020228生成的時間是:2019-08-13
820870564020229
分布式id-820870564020229生成的時間是:2019-08-13
820870564020230
分布式id-820870564020230生成的時間是:2019-08-13
820870564020231
分布式id-820870564020231生成的時間是:2019-08-13
820870564020232
分布式id-820870564020232生成的時間是:2019-08-13
820870564020233
分布式id-820870564020233生成的時間是:2019-08-13 雪法算法Snowflake适合做分布式ID嗎
根據一系列的分布式id講解,雪法算法Snowflake是目前網上最适合做分布式Id的了,大家如果想用的話,可以根據我上面的縮小版的Snowflake算法來作為我們開發中的使用。؏؏ᖗ乛◡乛ᖘ؏؏
其他分布式ID系列快捷鍵:
分布式ID系列(1)——為什麼需要分布式ID以及分布式ID的業務需求 分布式ID系列(2)——UUID适合做分布式ID嗎 分布式ID系列(3)——資料庫自增ID機制适合做分布式ID嗎 分布式ID系列(4)——Redis叢集實作的分布式ID适合做分布式ID嗎 分布式ID系列(5)——Twitter的雪法算法Snowflake适合做分布式ID嗎 原文連結大佬連結
![GitHub連夜封殺!這份阿裡 10W 字内部 Java 字面試手冊到底有多強?[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)