導讀:在沒有核心系統源碼的情況下,修改源碼列印耗時的方法無法使用,通過tcpdump、wireshark、gdb、010 editor、火焰圖、ida、資料庫抓sql耗時語句、oracle ash報告、loadrunner等工具找到了伺服器tps上不去、C程式程序随機挂掉的問題,并順利解決,收獲頗多。
背景
公司最近新上線一個系統,主要架構如下:
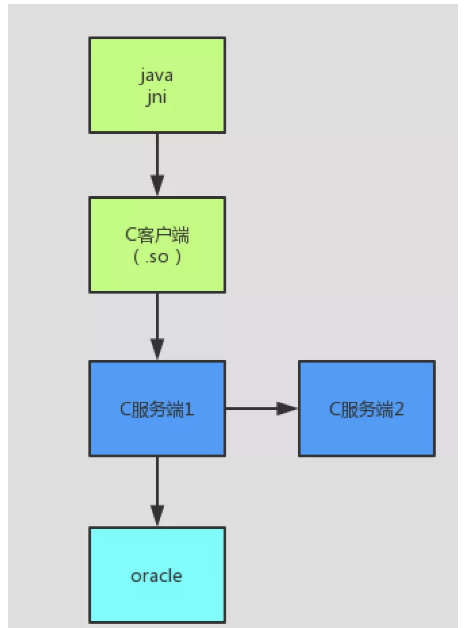
測試環境系統部署後,出現了兩個問題:
1.loadrunner壓測tps上不去,壓測java接口tps 單機隻能到100多tps就上不去了,耗時從單次通路的100ms上升到110并發時的1s左右。
- 壓測期間C伺服器1 經常不定時挂掉。
因為某些原因,該項目C相關程式沒有源碼,隻有安裝部署檔案,為了解決上述兩個問題,我們幾個同僚和重慶同僚一塊參與問題排查和解決。因為沒有源碼,中間經曆了層層波折,經過一個月努力,終于解決了上述兩個問題,整個排查過程學到了很多知識。
用到的分析工具
1.tcpdump,
2.wireshark,
3.gdb,
4.010 editor,
5.火焰圖,
6.ida,
7.資料庫抓sql耗時語句,
8.oracle ash報告,
9.loadrunner
幾句話總結
1.C程式用戶端socket長連接配接調用C服務端存在性能瓶頸,通過tcpdump,wireshark 二進制分析出傳輸協定後改用java調用C服務端,單機tps提升1倍,性能提升3倍
2.資料庫語句存在for update 語句導緻并發上不去,經過分析從業務上采用sequence 替換for update語句,并通過010 editor直接修改二進制 修改for update 語句相關邏輯為sequence ,系統具備了擴容伺服器tps也能同步提升的能力
3.資料庫insert語句并發情況下存在瓶頸,擴大oracle redo log日志大小解決,繼續提升tps40%。
4.程式程序随機挂掉,通過gdb分析core dump檔案,定位到在并發情況下程式中使用的gethostbyname有問題,采用臨時方法解決。
分析過程
1.第一次瓶頸定位
剛開始排查問題時,loadrunner壓測java接口,并發使用者從0逐漸增加到110個的情況下,tps到100左右就不再提升,響應耗時從100ms增大到1s。此時我們的分析重點是誰是目前的主要瓶頸
再看一遍架構圖, 圖中5個節點都有可能是瓶頸點,資料庫此時我們通過資料庫dba管理權限抓取耗時sql,沒抓取到,先排除資料庫問題,java的我們列印分步耗時日志,定位到jni調用 c用戶端耗時占比最大。這時瓶頸點初步定位到C用戶端,C服務端1,C服務端2 這三個節點。
因為沒有源碼,我們采用tcpdump抓包分析,在C伺服器1上
tcpdump -i eth0 -s 0 -w aa.txt host java用戶端ip 抓出的包用wireshark分析

通過追蹤流-TCP流 分析服務端耗時并沒有變的太大,因為C用戶端和C服務端是長連接配接,多個請求可能會共用一個連接配接,是以此時分析出的資料可能會不太準,是以我們采用loadrunner壓測,其它條件不變,一台C伺服器1和兩台C伺服器1分别檢視耗時變化,
其它條件不變,一台java伺服器和兩台java伺服器分别檢視耗時變化.
最終定位到是C用戶端的問題。(ps:在wireshark的分析資料時還跟秦迪大師弄明白了tcp延遲确認)
2.改造C用戶端
C用戶端和C服務端是通過長連接配接通信的,直接改造C代碼難度較大,所有我們準備把C替換成java,這就需要分析C之間通信傳參時候用的什麼協定,然後根據這個協定用java重寫。我們根據之前的經驗推測出了編碼協定,用wireshark分析二進制确認确實是這種編碼。
我們根據這種協定編碼采用java重寫後,同樣在110并發使用者情況下,tps提升到了210(提升兩倍),耗時降到了330ms(是原來的三分之一)
3.第二次瓶頸定位。
經過第二步優化後tps提升了兩倍,但是此時擴容tomcat,擴容C伺服器,tps就維持在210左右,不會變高了。是以我們繼續進行定位新的瓶頸點。此時找dba要到一個實時檢視oracle 耗時sql的語句
select
(select b.SQL_TEXT from v$sqlarea b where b.SQL_ID=a.SQL_ID ) sqltxt,
(select c.SQL_FULLTEXT from v$sqlarea c where c.SQL_ID=a.SQL_ID ) sqlfulltxt,
a.username, a.LAST_CALL_ET,a.MACHINE ,a.command, a.EVENT, a.SQL_ID ,a.SID,a.SERIAL#,
'alter system kill session ''' || a.SID ||','||a.SERIAL# ||''';' as killstment
from v$session a
where a.STATUS = 'ACTIVE'
and a.USERNAME not in ('SYS', 'SYSTEM')
order by
a.LAST_CALL_ET desc ,a.username,a.MACHINE ,a.command, a.EVENT, a.SQL_ID ,a.SID; 發現有個for update的sql 并發量大的時候部分請求 LAST_CALL_ET列的值能達到6秒,for update導緻了所有請求被串行執行,影響了并發能力。我們經過分析業務邏輯後,用sequence暫時替換 for update 語句,但是我們沒有源碼,沒法修改,後來又通過010 editor 直接修改二進制檔案,通過010 editor 查詢找到了 for update 語句,順利替換。
替換後,4台C伺服器tps達到了580,提升了2.7倍(580/210),系統初步具備了橫向擴充能力
4.第三次瓶頸定位。
經過上一步改造,4台C伺服器時系統的tps提升了2.7倍,但是并沒有提升到4倍(210*4=840),沒有線性提升,說明還是有别的瓶頸,又通過dba上邊給的sql發現insert 語句偶爾耗時也很長,在1s左右,EVENT等待事件是IO事件,DBA同僚給修改了redo log file 大小(這個是測試環境Oracle,之前沒有優化),從預設的50M,修改為1G, tps 提升到了640 (還沒提升到4倍,也就是說還有瓶頸,可能還是資料庫,但因為資料庫暫時沒辦法抓取到毫秒級的耗時sql,沒再繼續追查)
經過這幾次性能提升,加上我們測試伺服器配置都不高,如果線上伺服器性能預估能達到1000tps,基本滿足眼前需求,是以就沒再繼續進行性能優化。
5.程式程序随機挂掉問題。
壓測過程中,C伺服器程序經常随機挂掉,通過tail -f /var/log/messages 發現生成了core dump 檔案,但是又被系統自動删除了。董建查到了開啟core dupm檔案的方法,如下:
a、ulimit -c
檢視是否為0,如果為0,表示coredump檔案設定為0,需要修改為不限制
ulimit -c unlimited b、修改/etc/abrt/abrt-action-save-package-data.conf
ProcessUnpackaged = yes 修改後程序又崩潰時core dump 檔案生成了,進入core dump 目錄進行調試
gdb 腳本路徑 coredump
bt 顯示堆棧資訊
繼續執行如下指令
f 0
set print pretty on
info local //顯示目前函數中的局部變量資訊。 通過p指令檢視裡邊變量的值
發現變量thishost->h_addr_list的值為null
我們分析可能是并發請求時有方法不是線程安全的導緻這個值為null,進而引起了程序crash,繼續調試。
在gdb中 set logging on 把調試資訊輸出到檔案
thread apply all bt 輸出所有的線程資訊。
退出gdb
grep --color -i clientconnect -C5 gdb.txt 确實有兩個線程并發在通路
通過ida工具反編譯so,最終定位到以下語句在并發時有問題,thishost中的變量可能會被另一個線程在一瞬間初始化為null。
thishost = gethostbyname((const char *)hostname);
ip = inet_ntoa(*(struct in_addr *)*thishost->h_addr_list); 根據我們的項目特點,因為我們沒有遠端調用,C服務端1和C服務端2都部署在了同一台伺服器上,是以我們通過修改二進制把位址暫時寫死成了127.0.0.1,把ip = inet_ntoa((struct in_addr )*thishost->h_addr_list);修改成了空指令,重新部署後沒再出現系統崩潰的問題。
作者簡介:楊振-宜信工程師,前微網誌feed組工程師,對源碼學習感興趣;董建-宜信工程師,前微網誌工程師,關注大資料和高可用技術
原文釋出于 高可用架構
來源:宜信技術學院