本篇接上一篇内容《HanLP-基于HMM-Viterbi的人名識别原理介紹》介紹一下層疊隐馬的原理。
首先說一下上一篇介紹的人名識别效果對比:
-
隻有Jieba識别出的人名
準确率極低,基本為地名或複雜地名組成部分或複雜機構名組成部分。舉例如下:
[1] 戰亂的阿富汗地區,qiang zhi可随意買賣,AK47價格約500人民币
“阿富汗”被識别為人名。
[2] 安慶到桂林自駕遊如何規劃?
“桂林”被識别為人名。
[3] 2018天津市和平分局招聘社群戒毒、社群康複從業人員成績查詢入口
“康複”被識别為人名。
-
隻有HanLP識别出的人名
除了特别常用姓氏的名字識别正确,其他的都識别錯誤。舉例如下:
[1] 納溪區副區長李明帶隊到“花田酒地”景區檢查節前安全工作
“花田酒”被被識别為人名。
[2] 秀英“線上線下”齊發力 助力貧困戶“微互動”拓寬農産品銷路
“齊發力”被識别為人名。
[3] 緊急通知:秦報融媒粉團祖山一日遊日報名費大調整!
“秦報”被識别為人名。
- HanLP與Jieba都識别出的人名
-
非常用姓氏識别出的人名基本錯誤。
[1] 房産高管薪酬大起底 萬科郁亮年薪1189.9萬僅排第二
[2] 生生不息 南通支雲釋出汶川地震十周年海報呼籲賽前默哀
[3] 為什麼伊郎不能有he wu qi,而美國有he wu qi?
-
名字本身構成詞時基本錯誤。
[1] 周口一村莊楊絮着火,對付楊絮用啥方法好呢?
[2] 上聯: 三國魏蜀吳,如何對下聯?
[3] 上聯:燈火輝煌萬家樂。求下聯?
如何解決這些badcase呢,要看你的時間了,如果時間充裕的話,可以調整發射機率檔案也就是nr.txt檔案。如果時間不充裕的話,比如我現在的情況,那就隻保留常用姓氏,以及特别需要關注的人名了。
上一篇的内容先說到這裡,介紹本篇的主題”基于層疊隐馬的命名實體識别”我這裡主要閱讀的是這篇文章《基于層疊隐馬爾可夫模型的中文命名實體識别》。層疊就是将模型級聯起來的意思,是以系統的結構如下圖所示:
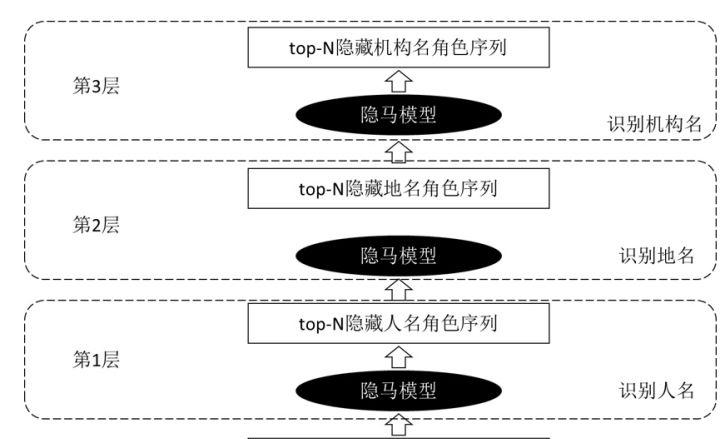
如圖所示,層疊隐馬就是訓練三個隐馬模型,每個模型标注一種實體,三個模型采用級聯形式連接配接。
不同的實體有不同的角色标注,實際就是特征,這些特征需要有語言學的知識,實際上就是你的閱讀量,通過你大量閱讀總結經驗,比如姓氏可以作為名字的一個特征(張、王、李、趙),常用地名的字尾可以作為一個特征(省、市、區、縣),機構名表處所的尾字可以作為一個特征(局、處、所、院)。這裡地名的角色标注簡表如下所示:
