愛寫bug(ID:iCodeBugs)
前言:
圍觀幾個知乎話題:
(
https://www.zhihu.com/question/328457531):
https://www.zhihu.com/question/328457531 https://www.zhihu.com/question/297715922):https://www.zhihu.com/question/297715922 https://www.zhihu.com/question/313825759):https://www.zhihu.com/question/313825759點開一個問題看一下答主的回答.
點開一個話題,進入開發者工具,重新整理頁面,在xhr欄目下,會發現很多請求,左上角過濾一下,隻有以
answers?
開頭的才是回答内容,分析一下請求頭:
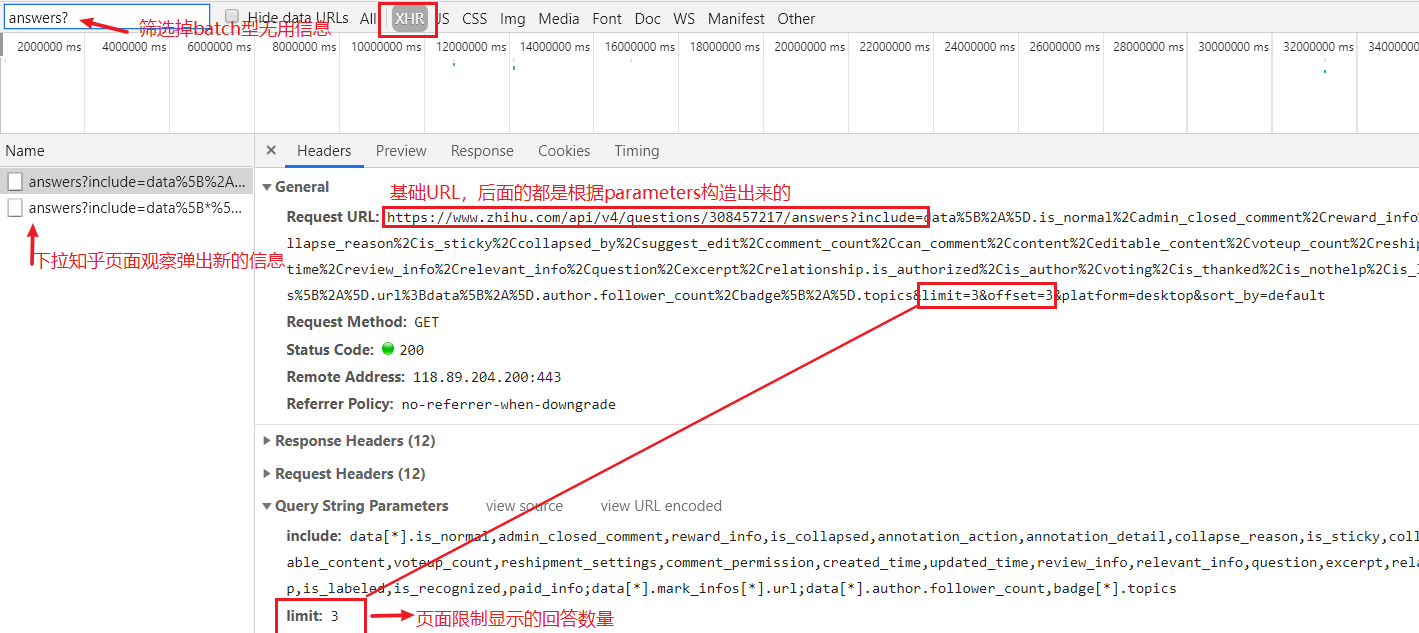
知乎的請求結構出奇的簡單,很意外。關鍵資訊已在圖檔标明。基礎URL是:
https://www.zhihu.com/api/v4/questions/313825759/answers?include=
後面全都是根據
Query String Parameters
構造出來的。
然後我們分析一下答主的回答内容:
這裡回答内容有可能是引用其他話題
擁有一雙大長腿是怎樣的體驗?
的圖檔,也就是說,我們隻要再把這個引用的話題位址擷取下來,再根據新擷取的位址構造請求URL, 得到該話題的請求位址,這樣就可以順着一條回答把所有引用的相似問題其他答主的圖檔全部下載下傳下來。。。
點選引用的其他話題,切換知乎話題
擁有一雙大長腿是怎樣的體驗?
。
同樣看一下該話題的
Query String Parameters
隻有 limit 、offset兩個屬性會變,而limit 為限制當頁顯示的回答數量,offset 為偏移量,就是本頁從第幾條回答開始顯示,其他屬性全是相同的(知乎頁面限制顯示回答數最大20)。這意味着不管知乎哪個問題都可由該問題的位址以相同的方法構造請求URL:
param = {
'include': '',#太長了,不展示了
'limit': '20', # 限制當頁顯示的回答數,知乎最大20
'offset': offset, # 偏移量
'platform': 'desktop',
'sort_by': 'default',
}
base_URL = 'https://www.zhihu.com/api/v4/questions/297715922/answers?include=' # 基礎 url 用來構造請求url
url = base_URL + urllib.parse.urlencode(param) # 構造請求位址 再點選 preview 看傳回的 json 格式的資訊:

有個totals,是該話題下總回答數,可以根據這個計算多少次可以周遊全部回答,考慮到後面回答内容品質就跟不上了,我們隻擷取前800條回答。
展開一條回答:
所有的資訊包括答主資訊和回答的資訊都在了,content内容就是回答内容,複制下來,格式化發現這是css渲染的内容,也能了解,知乎回答必須要用富文本方式編輯,傳回的内容必然是這種格式。看一下回答内容:
這個層次很明了,a 節點的 href 屬性就是引用的相關問題的位址。figure 節點 下 noscript 節點下 img節點的 src 屬性就是圖檔位址。用 pyquery 解析:
for answer in json['data']:
answer_info = {}
# 擷取作者資訊
author_info = answer['author']
author = {}
author['follower_count'] = author_info['follower_count'] # 作者被關注數量
author['headline'] = author_info['headline'] # 個性簽名
author['name'] = author_info['name'] # 昵稱
author['index_url'] = author_info['url'] # 首頁位址
# 擷取回答資訊
voteup_count = answer['voteup_count'] # 贊同數
comment_count = answer['comment_count'] # 評論數
# 解析回答内容
content = pq(answer['content']) # content 内容為 xml 格式的網頁,用pyquery解析
imgs_url = []
imgs = content('figure noscript img').items()
for img_url in imgs:
imgs_url.append(img_url.attr('src')) # 擷取每個圖檔位址
# 擷取回答内容引用的其他相似問題
question_info = content('a').items()
......太多不全部展示了,有興趣可以看一下文末完整源代碼 飲水思源儲存檔案以答主昵稱命名,以示尊敬:
def save_to_img(imgs_url, author_name, base_path):
path = base_path + author_name
if not os.path.exists(path): # 判斷路徑檔案夾是否已存在
os.mkdir(path)
for url in imgs_url:
try:
response = requests.get(url)
if response.status_code == 200:
img_path = '{0}/{1}.{2}'.format(path,
md5(response.content).hexdigest(), 'jpg') # 以圖檔的md5字元串命名防止重複圖檔
if not os.path.exists(img_path):
with open(img_path, 'wb') as jpg:
jpg.write(response.content)
else:
print('圖檔已存在,跳過該圖檔')
except requests.ConnectionError:
print('圖檔連結失效,下載下傳失敗,跳過該圖檔')
print('已儲存答主:' + author_name + ' 回答内容的所有圖檔') 以圖檔内容的 md5 編碼命名可以防止重複圖檔,如果圖檔被其他人下載下傳之後加水印再上傳,圖檔内容是不同的,是以可能有重複照片。
如果有需要可以把這些資料存到資料庫,這裡我以mongoDB為例:
#存儲在mongoDB
client = MongoClient(host='localhost')
print(client)
db = client['zhihu']
collection = db['zhihu']
def save_to_mongodb(answer_info):
if collection.insert(answer_info):
print('已存儲一條回答到MongoDB') 圖中存儲了答主引用的其他話題标題及位址,可以把這個位址傳回去循環擷取,直到所有類似話題圖檔全部下載下傳。
結語:
大家可根據情況加些判斷函數,例如圖檔中間大概位置的像素點是否相同,來真正的把重複圖檔去掉。加些人體身材特征值對比,去掉男士的圖檔和表情圖。這個太慢了,有時間的朋友自行發揮
源碼位址:
https://github.com/zhangzhe532/icodebugs/tree/master/DataAnalysis/zhihu_get_pic