背景
Join是一個非常耗費資源耗費時間的操作,特别是資料量很大的情況下。一般流程上會涉及底層表的掃描/shuffle/Join等過程, 如果我們能夠盡可能的在靠近源頭上減少參與計算的資料,一方面可以提高查詢性能,另一方面也可以減少資源的消耗(網絡/IO/CPU等),在同樣的資源的情況下可以支撐更多的查詢。
目前在SparkSQL中有Filter下推優化,包括兩個次元:
生成Filter
SparkSQL會從使用者的SQL語句中擷取到Filter
- 直接顯示擷取
生成Filter(a=1) on Aselect * from A where a=1 - 隐式推斷
推斷出Filter(b=1) on Bselect * from A, B where A.a = B.b and A.a=1
Filter優化
利用生成的Filter算子可以優化,比如:
- 将Filter盡量下推到靠近DataSource端
- 如果Filter中的列是分區列,可以提前對DataSource進行分區裁剪,隻掃描需要的分區資料
Runtime Filter
是針對Equi-Join場景提出的一種新的生成Filter的方式,通過動态擷取Filter内容來做相關優化。
Runtime Filter原理
優化對象
Equi Join, 形如
select x,y from A join B on A.a = B.b 其中A是一個小表(如維表),B是一個大表(如事實表)
備注: A/B也可以是一個簡單的子查詢
優化思路
如上述小表A和大表B進行Join,Join條件為A.a=B.b,實際Join過程中需要對大表進行全表掃描才能完成Join操作,極端情況下如A.a僅僅隻有一條記錄,也需要對B表全表掃描,影響性能。
如果在B表掃描之前,能擷取A表的a的相關資訊(如所有的a值,或者a的min/max/Bloomfilter等統計資訊),并在實際執行Join之前将這些資訊對B表的資料進行過濾,而不是全表掃描,可以大大提高性能。
兩種場景
根據大表B參與join的key(b)的屬性,可以分别采集小表A參與join的key(a)的資訊:
b是分區列
如上b為大表B的一個分區列,則可以提前收集
A.a列的所有值
,然後利用A.a的值對B表的b列進行分區裁剪
b不是分區列
不能做分區裁剪,隻能在實際資料掃描的過程中進行過濾。可以提前收集
A.a列的min/max/Bloomfilter的統計資訊
,然後利用這些統計資訊對B表進行資料過濾,這個過濾又可以分成兩種粒度:
-
可下推到存儲層,減少資料掃描
如底層檔案格式是Parquet/ORC, 可以将相關過濾謂詞(min/max等)下推到存儲層面,進而減少實際掃描的資料。
-
掃描後資料過濾
不能下推到存儲層的,可以在資料被掃描後做條件過濾,減少後續參與計算的資料量(如shuffle/join等)
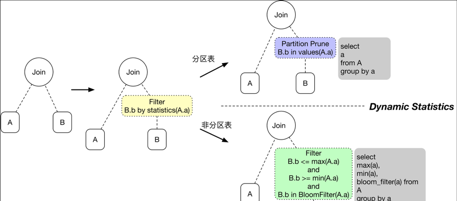
Runtime Filter實作
Runtime Filter的實作主要在Catalyst中,分為4個步驟:
謂詞合成
在使用者SQL生成的邏輯執行計劃樹(logical plan)中,尋找滿足條件的Equi-Join節點,然後根據上面的思路,在Join的大表B側插入一個新的Filter節點,如
Filter(In(b, Seq(DynamicValue(a, A))), B)
謂詞下推
上面生成的新的Filter會經過PushDownPredicate的Rule,盡量下推靠近DataSource附近
實體執行計劃生成
該階段會将上面下推的
Filter(In(b, Seq(DynamicValue(a, A))), B)
轉換成實體節點(FilterExec),根據上面兩種場景會生成兩種不同的FilterExec
- b是分區列,采集的是a列的所有值,如:
case class DynamicPartitionPruneFilterExec( child: SparkPlan, collectors: Seq[(Expression, SparkPlan)]) extends DynamicFilterUnaryExecNode with CodegenSupport with PredicateHelper
其中colletors就是用于采集資訊的SparkPlan,因為要跑一個SQL來采集a列的所有值(
select a from A group by a
);
因為有可能會有多個分區列,是以這個地方是一個Seq.
-
b是非分區列
b是非分區列,采集的是a列的min/max/bloomfilter統計資訊,如
case class DynamicMinMaxFilterExec( child: SparkPlan, collectors: Seq[(Expression, SparkPlan)]) extends DynamicFilterUnaryExecNode with CodegenSupport with PredicateHelper
同理上面collectors也是使用者采集資訊的SparkPlan,如
select min(a),max(a) from A
執行
在實體執行計劃實際執行的過程中,會在DynamicPartitionPruneFilterExec/DynamicMinMaxFilterExec實體算子内先執行collectors擷取到a列的相關資訊,然後對底層B的執行計劃進行改寫,比如利用采集到的資訊做分區裁剪/資料過濾等。
Runtime Filter性能測試
以TPC-DS 10TB的Query54為例:
Runtime Filter 關閉

Runtime Filter 打開
經過DynamicPartitionPruneFilter對catalog_sales的分區進行了裁剪,實際對表的掃描從14,327,953,968減少到136,107,053,然後經過min/max的過濾繼續減少到135,564,763;另外Runtime Filter減少了大表的掃描,shuffle的資料量以及參加Join的資料量,是以對整個叢集IO/網絡/CPU有比較大的節省
總結
針對Equi-Join的場景,可以額外的采集小表側的資訊,然後在Join之前對大表進行分區裁剪或者掃描後過濾,進而提高查詢性能,減少資源消耗。