1. 前言
Schedulerx2.0提供了map模型,通過一個map方法就能将海量資料分布式到多台機器上分布式執行,随着業務方的深入使用,又提出了更多的需求,比如:
- 監聽所有子任務完成的事件
- 處理所有子任務傳回的訂單号
- 彙總結果進行工作流資料傳輸
2. 簡介
MapReduce模型是Map模型的擴充,廢棄了postProcess方法,新增reduce接口,需要實作MapReduceJobProcessor。
MapReduce模型隻有一個reduce,所有子任務完成後會執行reduce方法,可以在reduce方法中傳回該任務執行個體的執行結果,作為工作流的上下遊資料傳遞。如果有子任務失敗,reduce不會執行。
MapReduce模型,還能處理所有子任務的結果。子任務通過return ProcessResult(true, result)傳回結果(比如傳回訂單号),reduce的時候,可以通過context拿到所有子任務的結果,進行相應的處理,不需要業務方自己做存儲。注意:所有子任務結果會緩存在master節點,對記憶體有壓力,建議子任務個數和result不要太大。
3. 接口
- public ProcessResult process(JobContext context) throws Exception; (必選)
- public ProcessResult map(List<? extends Object> taskList, String taskName); (必選)
- public ProcessResult reduce(JobContext context); (必選)
- public void kill(JobContext context); (可選)
4. 執行方式
和map模型一樣,MapReduce模型,也支援如下執行方式:
- 并行計算:支援子任務300以下,有子任務清單。
- 記憶體網格:基于記憶體計算,子任務5W以下,速度快。
- 網格計算:基于檔案計算,子任務100W以下。
5. 原理
Schedulerx2.0中,MapReduce模型隻有一個reduce,所有子任務完成後會執行reduce方法,原理如下圖所示:
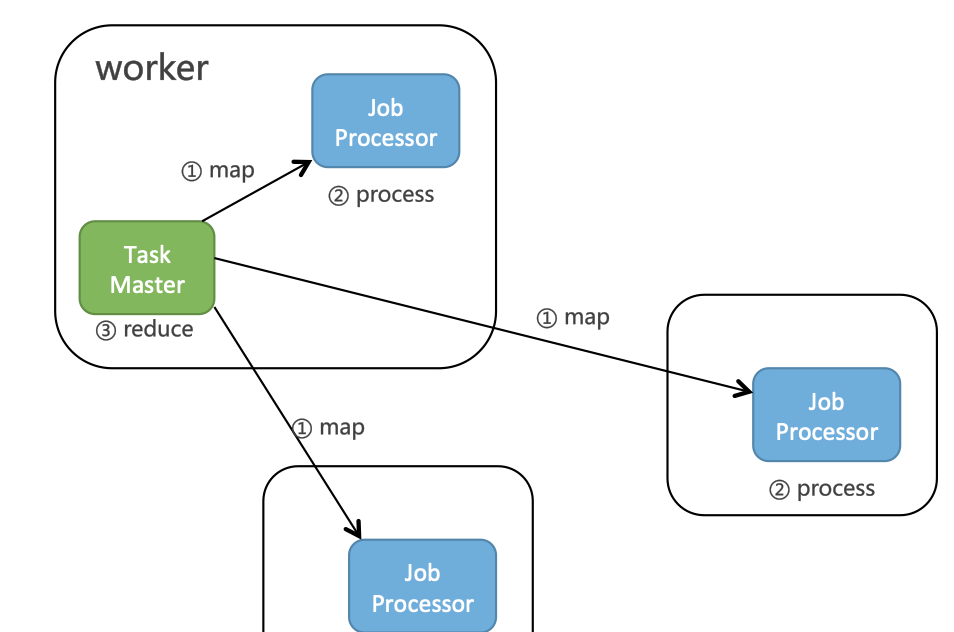
可以在reduce方法中傳回該任務執行個體的執行結果,作為工作流的上下遊資料傳遞。
Reduce方法也會通過ProcessResult傳回任務狀态,隻有所有子任務和reduce都傳回true,才算這次執行個體成功。
6. 最佳實踐
6.1 通過mapreduce進行工作流上下遊傳遞
下面我舉個例子,比如一個工作流JobA->JobB->JobC。JobA和JobC是java任務單機執行,JobB是網格計算MapReduce任務。代碼如下:
public class TestJobA extends JavaProcessor {
@Override
public ProcessResult process(JobContext context) throws Exception {
System.out.println("hello JobA");
return new ProcessResult(true, String.valueOf(10));
}
} public class TestJobB extends MapReduceJobProcessor {
@Override
public ProcessResult process(JobContext context) {
String executorName = context.getTaskName();
if (isRootTask(context)) {
System.out.println("start root task");
String upstreamData = context.getUpstreamData().get(0).getData();
int dispatchNum = Integer.valueOf(upstreamData);
List<String> msgList = Lists.newArrayList();
for (int i = 0; i <= dispatchNum; i++) {
msgList.add("msg_" + i);
}
return map(msgList, "Level1Dispatch");
} else if (executorName.equals("Level1Dispatch")) {
String executor = (String)context.getTask();
System.out.println(executor);
return new ProcessResult(true);
}
return new ProcessResult(false);
}
public ProcessResult reduce(JobContext context) throws Exception {
return new ProcessResult(true, "520");
}
} public class TestJobC extends JavaProcessor {
@Override
public ProcessResult process(JobContext context) throws Exception {
System.out.println("hello JobC");
String upstreamData = context.getUpstreamData().get(0).getData();
System.out.print(upstreamData);
return new ProcessResult(true);
}
} 執行結果如下:

jobA輸出了10,jobB産生了0~10個msg并通過reduce輸出520,jobC列印520。
6.2 Mapreduce處理所有子任務結果,由reduce彙總
@Component
public class TestMapReduceJobProcessor extends MapReduceJobProcessor {
@Override
public ProcessResult process(JobContext context) throws Exception {
String taskName = context.getTaskName();
int dispatchNum = 10;
if (context.getJobParameters() != null) {
dispatchNum = Integer.valueOf(context.getJobParameters());
}
if (isRootTask(context)) {
System.out.println("start root task");
List<String> msgList = Lists.newArrayList();
for (int i = 0; i <= dispatchNum; i++) {
msgList.add("msg_" + i);
}
return map(msgList, "Level1Dispatch");
} else if (taskName.equals("Level1Dispatch")) {
String task = (String)context.getTask();
Thread.sleep(2000);
return new ProcessResult(true, task);
}
return new ProcessResult(false);
}
@Override
public ProcessResult reduce(JobContext context) throws Exception {
for (Entry<Long, String> result : context.getTaskResults().entrySet()) {
System.out.println("taskId:" + result.getKey() + ", result:" + result.getValue());
}
return new ProcessResult(true, "TestMapReduceJobProcessor.reduce");
}
} reduce執行結果如下:
taskId:0, result:
taskId:1, result:msg_0
taskId:2, result:msg_1
taskId:3, result:msg_2
taskId:4, result:msg_3
taskId:5, result:msg_4
taskId:6, result:msg_5
taskId:7, result:msg_6
taskId:8, result:msg_7
taskId:9, result:msg_8
taskId:10, result:msg_9
taskId:11, result:msg_10 taskId=0表示的是根節點,一般不會傳回結果,不需要管。