在并行計算領域最著名的就是MPI模型,MPI是一種消息傳遞程式設計模型,在大規模科學計算領域已經成功應用了數年,而MapReduce則是一種近幾年出現的相對較新的并行程式設計技術,但是MapReduce計算模型也是建立在數學和計算機科學基礎上的,實踐已經證明這種并行程式設計模型具有簡單、高效的特點,最為重要的兩個概念就是Map和Reduce.最基本的處理思想就是“分而治之,然後歸約”。Hadoop會将一個大任務分解為可以同時執行的多個小任務,進而達到并行計算的目的。舉個簡單的例子,對于一個大型任務,單機處理需要1024分鐘,而分解為1024個子任務并行執行就可在1分鐘完成處理。在對處理的資料集的要求上,相比于傳統關系資料庫的結構化資料,MapReduce模型的Hadoop架構适合半結構化或非結構化的資料。
Hadoop通過自動分割将要執行的問題(程式)、拆解成Map(映射)和Reduce(化簡)的方式,其分解過程的實質是将問題分為幾個部分,劃分為可以應用于程式的資料,再将資料分解,然後對分解的資料進行并行操作,在自動分割後通過Map程式将資料映射成不相關的區塊,配置設定(排程)給大星的i十算機進行處理以達到分散運算的效果,再通過Reduce程式将結果彙總整合,輸出開發者需要的結果。
Hadoop向使用者提供了一個規範化的MapReduce程式設計接口,使用者隻需要編寫Map和Reduce函數,這兩個函數都是運作在鍵-值對基礎上的,資料的切分,節點之間的通信協調等全部由Hadoop架構木身來負責。一般一個使用者作業送出到Hadoop叢集後會根據輸入資料的大小并行啟動多個Map程序及多個Reduce程序(也可以是0個或者1個)來執行.MapReduce也具有彈性适應性,小資料和大資料僅僅通過調整節點就可以處理,而不需要使用者修改程式MapReduce模型處理流程如下圖所示。
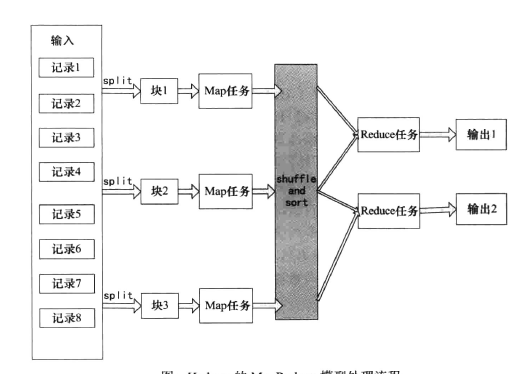
上圖就是MapReduce的資料處理流程圖,在Map之前會對輸入的資料有split的過程,預設split就是寫人資料時的邏輯塊,每一個塊對應一個split,一個split就對應一個Map程序,正是split保證了任務的并行效率。在Map之後還會有shuffe和sort的過程.shuffle簡單描述就是一個Map的輸出應該映射到哪個Reduce作為輸入,sort就是指在Map運作完輸出後會根據輸出的鍵進行排序。這兩個處理步驟對于提高Reduce的效率及減小資料傳輸的壓力有很大的幫助。
從本質上講MapReduce借鑒了函數式程式設計語言的設計思想,其軟體實作是指定一個Map函數,把鍵值對(key/value)映射成新的鍵值對(key/value),形成一系列中間結果形式的鍵值對(key/value ),然後把它們傳給Reduce(歸約)函數,把具有相同中間形式key的value合并在一起。Map和Reduce。函數具有一定的關聯性。其算法描述為:
Map(k, v) ->list(k1,v1)
Reduce(k1,list(v1)) ->list (v1)
在Map過程中将資料并行,即把資料用映射函數規則分開,而Reduce則把分開的資料用歸約函數規則合在一起,即Map是個分的過程,Reduce則對應着合。
本文轉自大資料躺過的坑部落格園部落格,原文連結:http://www.cnblogs.com/zlslch/p/5080590.html,如需轉載請自行聯系原作者
![【MySQL資料庫】資料庫索引事務1.索引2.事務[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)