背景
一般來說,除了由于secondary延遲可能造成查詢secondary節點資料不準以外,關于count的準确性問題,在MongoDB4.0官方文檔中有這麼一段話
On a sharded cluster, db.collection.count() without a query predicate can result in an inaccurate count iforphaned documents exist or if a chunk migration is in progress.
To avoid these situations, on a sharded cluster, use the db.collection.aggregate() method
而MongoDB3.6官方文檔卻是這麼描述的
On a sharded cluster, db.collection.count() can result in an inaccurate count if orphaned documents exist or if a chunk migration is in progress.
也就是說,MongoDB4.0分片叢集模式下,針對不帶謂詞條件的全表count操作的傳回結果是不準确的,主要包括以下兩種場景。在MongoDB4.0以前的版本,即使不帶謂詞條件,在以下兩種場景下count值也不準。
1 存在孤立文檔
2 mongo分片叢集内部正在進行move chunk操作
本文主要針對這兩種場景,分析count不準的原因和規避措施
orphaned documents導緻count不準
孤立文檔定義和産生原因
孤立文檔是由于move chunk期間程序異常關閉造成的遷移失敗或清理遷移後的源端chunk失敗造成的,使得這部分記錄在源端和目标端都存在,而在mongo分片叢集的定義中,一個文檔必須且隻能屬于一個chunk和shard。
顯而易見,孤立文檔可能導緻count不準,如果孤立文檔量太大,還會造成占用額外的磁盤存儲資源。
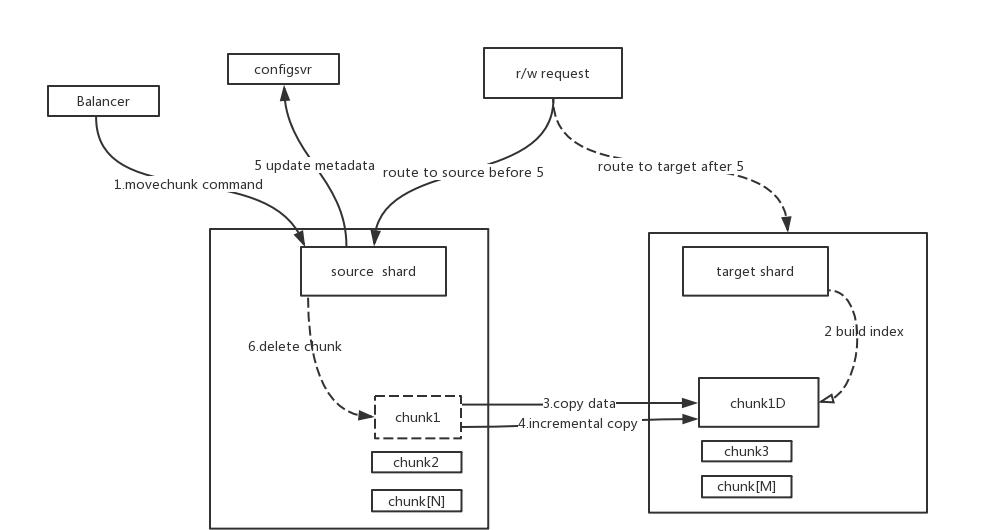
一般來說,movechunk操作大概有以下步驟
- 負載均衡器向源端分片發送movechunk指令
- 源端分片開始在内部遷移資料塊,在整個遷移期間,源端接收所有的通路請求,包括讀和寫
- 在目标端分片建立對應的索引
- 目标端分片開始接收從源端copy過來的chunk中的資料
- 當目标端接收完該chunk的最後一條文檔後,目标端分片開啟一個同步程序來接收chunk遷移期間在源端産生的增量資料
- 當所有增量資料也同步完成後,源端分片開始連接配接config資料庫修改中繼資料,也就是修改該chunk的所屬分片
- 修改好config中繼資料後,源端分片開始删除之前遷移的chunk資料
MongoDB·最佳實踐·count不準原因分析背景orphaned documents導緻count不準孤立文檔定義和産生原因現象模拟和描述規避和消除orphaned documents方法move chunk期間count不準現象描述原因分析改進措施和規避方法
mongodb在設計實作上,真正從源端向目标端copy資料的過程是串行的,也就是隻能逐個chunk遷移,但是出于遷移效率上的考慮,最後一步的清理源端分片殘留資料的操作是異步的,也就說當修改完config中繼資料後,馬上可以進入下一個chunk的遷移,并不需要等待源端分片清理完成。
清理源端分片舊chunk資料的操作放在一個隊列中,在某些場景下它可能由于清理緩慢造成堆積,如果這時primary節點crash,就會産生孤立文檔。
現象模拟和描述
從chunk遷移過程可以看出,假如遷移過程失敗,我們尚不得知它是否會清理目标端資料,理論上也會造成目标分片上的孤立文檔,不過由于movechunk串行處理,即使有,最多也就一個chunk塊有問題;但如果最後一步的清理源端舊chunk資料失敗,則必然會在源端造成孤立文檔,而且最差的情況下可能會産生大量chunk的孤立文檔。
是以要模拟出孤立文檔很簡單,隻需要在大量movechunk期間強制殺掉主節點mongod程序即可,比如在已有一個shard的情況下,添加另外一個shard到分片叢集中,這時必然會涉及到大量的movechunk操作,本文就是采用這種方式。
//添加sharding前,确認sh.isBalancerRunning()為false,因為movechunk期間count本來也不準
mongos> db.user.count({_id:{$gte:0}})
43937296
mongos> db.user.count()
43937296
//添加分片過程中kill -9 mongod程序,重新拉起各個分片,
mongos> db.user.count({_id:{$gte:0}})
43937296
mongos> db.user.count()
51028273
mongos> db.user.aggregate([{ $count:"myCount"}])
{ "myCount" : 43937296 } 從上面可以看到,隻有不帶謂詞條件的全表count才會存在結果不準的現象,因為在這種情況下,count結果值直接從表和chunk的中繼資料資訊擷取,在分布叢集模式下就是挨個去各個分片的chunk擷取該表存取的count值,然後做一個累加傳回,由于孤立文檔的存在就造成傳回結果大于準确結果。上個案例中一個産生了7090977個孤立文檔。
規避和消除orphaned documents方法
從一方面說,減少孤立文檔産生的數量,預設情況下,清理源端分片資料是異步調用的,但也可以通過指令設定成同步調用,也就是設定以後假如primary節點crash,最多隻有一個chunk可能産生孤立,但并不推薦,意義也不大。設定方法為
use config
db.settings.update( { "_id" : "balancer" },{ $set : { "_waitForDelete" : true } },{ upsert : true }) 從另一個方面考慮,假如産生了孤立文檔,mongodb提供了清理分片上所有孤立文檔的方法,在每一個sharding節點上執行,方法如下
var nextKey = { };
var result;
while ( nextKey != null ) {
result = db.adminCommand( { cleanupOrphaned: "test.user", startingFromKey: nextKey } );
if (result.ok != 1)
print("Unable to complete at this time: failure or timeout.")
printjson(result);
nextKey = result.stoppedAtKey;
} move chunk期間count不準
現象描述
通過mongod日志或者sh.isBalancerRunning()指令可以确認,該表處于move chunk階段;
為了友善觀察,我們将_waitForDelete設定為1,即遷移chunk完成後立即删除源端分片資料再進入下一次地chunk遷移,可以觀察到count結果值首先有一個快速的增長過程,然後是一個相對緩慢的減少過程;
每個chunk遷移循環上述過程,直到sh.isBalancerRunning()為OFF後,穩定在一個準确值。
原因分析
- 在move chunk過程中,如果move chunk沒有完成,這時資料在源端和目标端分片上都存在
- 這時在這個分片上執行無謂詞條件的count時,源端和目标端上未遷移完成的chunk的資料都納入了統計,是以會看到結果值會有一個上升
- 當copy data結束并修改中繼資料後,在源分片上開始清理資料,是以到了這個階段,count值會逐漸減少
- count值減少的過程相對比較緩慢,應該是由于清理源端分片資料花的時間要比copy資料更長
在move chunk過程中,如果是非count操作,普通的query肯定無法容忍這種錯誤的,因為根據之前的遷移過程分析,在movechunk的copy data期間,源端接收所有的通路請求;在修改中繼資料後,delete源端資料期間,目标端接受所有的通路請求。也就是說,普通的query會去判斷查詢需要的chunk确實屬于且隻屬于一個shard,完全遵循config server中的中繼資料,是以它的查詢結果是準确的。
如果是MongoDB4.0以前的版本,count操作即使帶了謂詞條件結果值也會不準。這是因為在4.0版本以前帶謂詞條件的count操作原理和普通的query不同,它并不會去檢查周遊到的chunk确實隻屬于一個shard,而4.0以後的版本,其原理就和普通query一樣了,杜絕了結果值不準的情況。
從設計哲學上分析,既然4.0版本也沒有保證不帶謂詞條件的count準确性,可以認為是一種性能與效率上的折衷,因為在這種count場景下,大部分業務并不需要非常精準的count結果,而更強調"fast count"理念,即不用周遊資料,直接從中繼資料層面傳回結果值;當然你需要準确的count值,也完全可以用aggregate方法代替,是以不能認為這是一個bug,如果說有待優化的點,可能隻是兩種count方法在指令展示上不夠相容,容易引起誤解。
改進措施和規避方法
1 同時追求效率和準确性,可以設定負載均衡視窗,在視窗以外禁止move chunk
2 強調資料準确性的場景,使用db.collection.aggregate()方法代替count
3 針對帶謂詞條件的count操作,将mongo版本更新到4.0以上
4 針對出現大量孤立文檔的情況,做孤立文檔清理
![【MySQL資料庫】資料庫索引事務1.索引2.事務[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)