我們知道,HDFS 被設計成存儲大規模的資料集,我們可以在 HDFS 上存儲 TB 甚至 PB 級别的海量資料。而這些資料的中繼資料(比如檔案由哪些塊組成、這些塊分别存儲在哪些節點上)全部都是由 NameNode 節點維護,為了達到高效的通路, NameNode 在啟動的時候會将這些中繼資料全部加載到記憶體中。而 HDFS 中的每一個檔案、目錄以及檔案塊,在 NameNode 記憶體都會有記錄,每一條資訊大約占用150位元組的記憶體空間。由此可見,HDFS 上存在大量的小檔案(這裡說的小檔案是指檔案大小要比一個 HDFS 塊大小(在 Hadoop1.x 的時候預設塊大小64M,可以通過 dfs.blocksize 來設定;但是到了 Hadoop 2.x 的時候預設塊大小為128MB了,可以通過 dfs.block.size 設定) 小得多的檔案。)至少會産生以下幾個負面影響:
- 大量小檔案的存在勢必占用大量的 NameNode 記憶體,進而影響 HDFS 的橫向擴充能力。
- 另一方面,如果我們使用 MapReduce 任務來處理這些小檔案,因為每個 Map 會處理一個 HDFS 塊;這會導緻程式啟動大量的 Map 來處理這些小檔案,雖然這些小檔案總的大小并非很大,卻占用了叢集的大量資源!
以上兩個負面影響都不是我們想看見的。那麼這麼多的小檔案一般在什麼情況下産生?我在這裡歸納為以下幾種情況:
- 實時流處理:比如我們使用 Spark Streaming 從外部資料源接收資料,然後經過 ETL 處理之後存儲到 HDFS 中。這種情況下在每個 Job 中會産生大量的小檔案。
- MapReduce 産生:我們使用 Hive 查詢一張含有海量資料的表,然後存儲在另外一張表中,而這個查詢隻有簡單的過濾條件(比如 select * from iteblog where from = 'hadoop'),這種情況隻會啟動大量的 Map 來處理,這種情況可能會産生大量的小檔案。也可能 Reduce 設定不合理,産生大量的小檔案,
- 資料本身的特點:比如我們在 HDFS 上存儲大量的圖檔、短視訊、短音頻等檔案,由于這些檔案的特點,而且數量衆多,也可能給 HDFS 大量災難。
那麼針對這些小檔案,現有哪幾種解決方案呢?
現有小檔案解決方案
在本部落格的《Hadoop小檔案優化》文章中,翻譯了 Cloudera 官方技術部落格的《The Small Files Problem》文章,裡面提供了兩種 HDFS 小檔案的解決方案。
HAR files
Hadoop Archives (HAR files)是在 Hadoop 0.18.0 版本中引入的,它的出現就是為了緩解大量小檔案消耗 NameNode 記憶體的問題。HAR 檔案是通過在 HDFS 上建構一個階層化的檔案系統來工作。一個 HAR 檔案是通過 hadoop 的 archive 指令來建立,而這個指令實 際上也是運作了一個 MapReduce 任務來将小檔案打包成 HAR 檔案。對用戶端來說,使用 HAR 檔案沒有任何影響。所有的原始檔案都可見并且可通路的(通過 har://URL)。但在 HDFS 端它内部的檔案數減少了。架構如下:
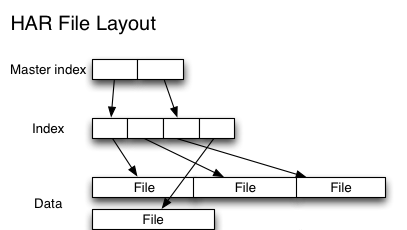
從上面實作圖我們可以看出,Hadoop 在進行最終檔案的讀取時,需要先通路索引資料,是以在效率上會比直接讀取 HDFS 檔案慢一些。
Sequence Files
第二種解決小檔案的方法是使用 SequenceFile。這種方法使用小檔案名作為 key,并且檔案内容作為 value,實踐中這種方式非常管用。如下圖所示:

和 HAR 不同的是,這種方式還支援壓縮。該方案對于小檔案的存取都比較自由,不限制使用者和檔案的多少,但是 SequenceFile 檔案不能追加寫入,适用于一次性寫入大量小檔案的操作。
HBase
除了上面的方法,其實我們還可以将小檔案存儲到類似于 HBase 的 KV 資料庫裡面,也可以将 Key 設定為小檔案的檔案名,Value 設定為小檔案的内容,相比使用 SequenceFile 存儲小檔案,使用 HBase 的時候我們可以對檔案進行修改,甚至能拿到所有的曆史修改版本。
從 HDFS 底層解決小檔案問題
以上三種方法雖然能夠解決小檔案的問題,但是這些方法都有局限:HAR Files 和 Sequence Files 一旦建立,之後都不支援修改,是以這是對讀場景很友好的;而使用 HBase 需要引入外部系統,維護成本很高。最後,這些方法都沒有從根本上解決。那麼能不能從 HDFS 底層解決這個問題呢?也就是對使用方來說,我們不需要考慮寫的檔案大小。目前 Hadoop 社群确實有很多相應的讨論和方案設想。下面将簡要進行描述。
HDFS-8998
我們都知道,一個檔案在 HDFS 上對應一個或多個 Block,每個 Block 在 NameNode (INode 和 BlocksMap)中都存在一定的中繼資料,而且這些資料需要占用 NameNode 一定記憶體。是以說,如果 HDFS 中存在大量的小檔案,因為這些小檔案都是小于一個 Block 大小,是以這些檔案占用了一個 Block;這樣,海量的小檔案占用了海量的 Block 。那我們能不能把這些小 Block 合并成一個大 Block?這正是 HDFS-8998 的思想。其核心實作如下:
- 使用者可以在 HDFS 上指定一個區域,用于存放小檔案,這個區域稱為小檔案區域(Small file zone);
- NameNode 将儲存固定大小的 block 清單,清單的大小是可以配置的,比如我們配置成 M;
- 當用戶端1第一次向 NameNode 發出寫時,NameNode 将為用戶端1建立第一個 blockid,并鎖定此塊;隻有在關閉 OutputStream 的時候才釋放這個鎖;
- 當用戶端2向 NameNode 發出寫時,NameNode 将嘗試為其配置設定未鎖定的塊(unlocked block),如果沒有未鎖定的塊,并且現有的塊數小于之前配置的大小(M),這時候 NameNode 則為用戶端2建立新的 blockid 并鎖定該塊。
- 其餘的用戶端操作和這個類似;
- 用戶端寫資料的操作都是将資料追加到擷取到的塊上;
- 如果某個塊被寫滿,也會配置設定新的一個塊給用戶端,然後寫滿的塊将從 M 個候選塊清單中移除,表示此塊将不再接受寫處理。
- 當 M 個塊中沒有未鎖住的塊并且 NameNode 無法再申請新塊的時候,則目前用戶端必須等待其它用戶端操作完畢,并釋放塊。
從上圖可以看出,每個 block 同時隻能由一個用戶端處理,但是當這個用戶端寫完,并釋放相關鎖之後,還能由其他用戶端複用!直到這個 block 達到 HDFS 配置的快大小(比如 128MB)。
從上面的闡述可以看出,一個 block 将包含多個檔案,那麼我們需要引入額外的服務來維護各個檔案在 block 中的偏移量。其餘的讀寫删操作如下:
- 讀取:關于這些檔案的讀取,其實和讀取正常的 HDFS 檔案類似。
- 删除:因為現在一個 block 包含不止一個檔案,是以删除操作不能直接删除一個 block。現在的删除操作是:從 NameNode 中的 BlocksMap 删除 INode;然後當這個塊中被删除的資料達到一定的門檻值(這個門檻值是可以配置的) ,對應的塊對象會被重寫。
- append 和 truncate:對小檔案的 truncate 和 append 是不支援的,因為這些操作代價非常高。
HDFS-8286
HDFS-8998 的設計目标是直接從底層的 block 做一些修改,進而減少檔案中繼資料的條數,以此來減少 NN 的記憶體消耗。而 HDFS-8286 的目标是直接從解決 NN 管理的中繼資料入手,将 NN 管理的中繼資料從儲存在記憶體轉向到儲存在第三方 KV 存儲系統中,以此減緩 NN 的記憶體使用。更進一步的講,這種方法同時也提高了 Hadoop 叢集的擴充性。
現在的 HDFS 是以層次結構的形式來管理檔案和目錄的,所有的檔案和目錄都表示為 inode 對象。為了實作層次結構,一個目錄需要包含對其所有子檔案的引用。而 HDFS-8286 的方案采用 KV 的形式來存儲中繼資料。下面我們來看看它是怎麼實作的,我們先來了解下兩條 kv 對應的規則:
- 每個 INode 對象都有對應的 inode id
- key 為 将直接映射到 foo 對象的 inode id,而且 foo 對象的父對象的 inode id 為 pid
根據這兩條規則,現在我們想基于 KV 中繼資料結構擷取 /foo/bar 路徑,解析過程如下圖所示:
- 首先,root 的 inode id 為1,那麼系統會将 foo 對象和其父對象的 inode id 進行組合,并得到一個 key <1,foo>;
- 第二步,系統根據上面得到的 key <1,foo>,從 KV 存儲裡面拿到 foo 對象的 inode id。從上圖可以看出, foo 對象對應的 inode id 為2,對應上圖的步驟 i;
- 第三步和第二步類似,系統需要拿到 bar 對象的 inode id,同樣也是構造一個k key,得到 <2,bar>,最後從 KV 存儲裡面拿到 bar 對象的 inode id,這裡為 3,對應上圖的步驟 ii;
- 最後,系統直接根據 inode id 為 3,從 KV 存儲裡面拿到對應的 bar 的内容,對應圖中的步驟 iii。
這個過程可以看到需要從 KV 存儲裡面進行多次檢索,并進行解析,可能會在這裡面出現一些性能問題。
Hadoop Ozone
Ozone 是 Hortonworks 基于 HDFS 實作的一個對象存儲服務,旨在基于 HDFS 的 DataNode 存儲,支援更大規模的資料對象存儲,支援各種對象大小并且擁有 HDFS 的可靠性,一緻性和可用性,對應的 issue 請參見 HDFS-7240。目前這個項目已經成為 Apache Hadoop 的子項目,參見 ozone。Ozone 的一大目标就是擴充 HDFS,使其支援數十億個對象的存儲。關于 Ozone 的使用文檔可以參見 Apache Hadoop Ozone。
總結
社群關于 HDFS 的擴充性問題基本上都是通過解決 NameNode 中繼資料的存儲問題,将中繼資料由原來的單節點存儲擴充到多個;甚至直接使用外部的 KV 系統來存儲一部分中繼資料或全部的中繼資料。相信不久的将來,使用 HDFS 存儲小檔案已經不是什麼問題了。
本文轉載自:
https://blog.csdn.net/b6ecl1k7BS8O/article/details/83005862