摘要:在中國HBase技術社群第十屆meetup--HBase生态實踐 (杭州站)上,阿裡雲技術專家郭澤晖為大家介紹了雲HBase之時序引擎OpenTSDB的介紹及壓縮優化,向大家展示了使用OpenTSDB所遇到的一些問題及優化方案,并對雲OpenTSDB的集中使用模式進行了相應的介紹。
本文根據演講視訊以及PPT整理而成。
本文将主要圍繞以下四個方面進行分享:
- OpenTSDB的介紹
- OpenTSDB的常見問題
- OpenTSDB的壓縮優化
- 雲OpenTSDB的使用模式
本文首先會對OpenTSDB簡單介紹,以及使用OpenTSDB時所遇到的常見問題,之後則會重點介紹相對于社群版的OpenTSDB所做的相應改進,最後介紹雲OpenTSDB的幾種使用模式。
一、OpenTSDB的介紹
OpenTSDB是一款基于HBase建構的時序資料庫,時序資料具有以下特點:
(1)資料為數值類型,常用于監控。
(2)資料通常按照時間順序抵達。
(3)資料基本不會被更新。
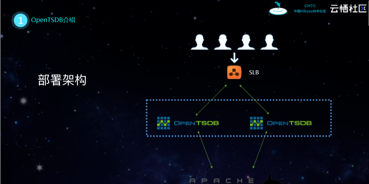
(4)寫入較多,讀入較少。目前使用者在阿裡雲上部署時序資料庫所選擇的架構通常為對SLB進行挂載後,對一定數量的OpenTSDB進行部署,最後底層與HBase相關聯。
OpenTSDB對時序資料具有如下定義,首先在資料存儲過程中會建立Metric,可以了解為一個監控的group,并用Tags對資料進行進一步的辨別,Metric+Tags的組合代表一個具體的時間線,每一條時間線上會存儲多個資料點,其中資料點是一個包含時間和值的二進制組,每一條時間線會不斷的産生相關資料并進行寫入。對于時間精度,OpenTSDB支援秒級和毫秒級的時間精度,在寫入的資料中如果資料點的時間戳為10位,則時間精度為秒,如果寫入的時間戳為13位,則時間精度為毫秒。接下來簡單介紹一下OpenTSDB的存儲結構,以寫metric=host.cpu, timestamp=1552643656, tags={region:HangZhou,host:30,43,111,255}, value=100為例,這條資料到達HBase存儲層後經過了如下轉換,其中存儲資料metric=host.cpu時,将其映射成唯一UID進行存儲。為了減少存儲空間,每條時間線每一小時存儲一行。是以對于timestamp=1552643656,會将資料轉換成小時的起始整秒,同樣,對于tags的資訊,也會映射成唯一UID進行存儲。至此整個RowKey部分便存儲完成,對于Column部分,将會記錄和這個小時起始時間的偏移量,以及value的值。

下面對RowKey和Column的資料格式進行更為詳細的介紹,實際上,為了避免同一個Metric擁有很多條時間線導緻的寫入熱點問題,在Metric前面會有加鹽的一位資料salt,來打散同一Metric下不同時間線的熱點。同時Metric和Tag的預設長度為3個位元組,即最多隻能配置設定16777216個UID,為了防止UID超量的問題,可以通過修改相應的參數(tsd.storage.uid.width.metric, tsd.storage.uid.width.tagk, tsd.storage.uid.width.tagv)來進行調整,但需要注意的是,一旦叢集已經寫入資料後參數便無法再次進行修改。對于Column部分的資料格式來說,秒級和毫秒級的資料格式是有差異的,毫秒級的資料需要更多的空間來進行存儲,
二、OpenTSDB的常見問題
接下來介紹OpenTSDB的常見問題,在上文提到,為了避免同一個Metric擁有很多條時間線導緻的寫入熱點問題,會通過對資料加鹽一位來将熱點打散,但打散後會将Metric分到多個buckets中,此時在進行查詢時,有多少個buckets便會并發多少個查詢請求到HBase中,此時便有了寫入熱點與并發查詢的權衡問題,過多的并發度很容易将HBase打爆,是以需要考慮實際的HBase的業務規模來進行參數的設定。同樣需要注意的一點,該項設定寫入資料後,也無法進行修改。
第二個問題是Tags的笛卡兒積影響查詢效率,假設一個監控機器CPU情況的mertric=host.cpu有三個tag,分别是機房區域region,主機名host,cpu單核編号core。這三個tag的數量分别為10,100,8。那麼該mertric會包含101008=8000條時間線,假使現在需要查詢某一條時間線上的資料,也需要通路8000條時間線上的資料才能得到所需要的結果,其根本原因在于tag是沒有索引的,目前常見的解決辦法主要有兩種,一種是将tag提至RowKey前,來進行索引的建立,另一種是在RowKey中拼接tag的部分資訊來減少笛卡兒積。OpenTSDB還有一些其他的查詢問題,比如資料不是流式處理,資料點要全部放入到TSDB記憶體後才會開始進行聚合處理,容易OOM;一個大的查詢隻會配置設定給一台TSDB上進行處理,不能分布式處理;即使隻查詢15分鐘的資料,也需要周遊一小時的資料等。
第三個問題便是OpenTSDB的壓縮問題,即整點壓縮對HBase産生流量沖擊。為了節省存儲空間,OpenTSDB會将離散的KV合成為一個大的KV,來減少重複字段,是以在整點時間便會有讀取-壓縮-重寫-删除一系列的操作産生,這些操作會對HBase發起大量的IO請求,導緻長時間的數倍流量波峰,很容易将HBase打爆。是以需要更高的機器規模來抵抗波峰。
三、OpenTSDB的壓縮優化
事實上,如果能夠消除流量波峰,可以極大的降低營運成本,提高系統的穩定性。傳統資料壓縮的步驟是先從HBase中讀取上一個小時寫入的所有資料,然後在OpenTSDB中壓縮這些讀出的資料,并将壓縮好的資料寫入HBase中,最後将舊的資料從HBase中删除,可以看出壓縮資料中存在了大量的OpenTSDB對于HBase的IO請求。為了解決這一問題,需要對OpenTSDB的壓縮進行優化,具體的實作思路是将OpenTSDB的壓縮過程下沉到底層HBase中,因為HBaes自身壓縮資料時便會對資料進行讀寫,在此時對資料進行處理,複用HBase壓縮過程的流量,在合并HFile的時候将KV按照OpenTSDB的資料格式進行合并,便可以避免OpenTSDB對HBase發起大量的IO請求,進而避免了流量波峰。
四、雲OpenTSDB的使用模式
最後介紹一下雲OpenTSDB的幾種使用模式,一種是獨享模式,即完全獨立部署的時序資料庫,适合時序業務較重,需要分離部署的情況。
另一種是共享模式,可以複用已經購買的雲HBase,适合時序業務較小,或者使用HBase雲資源較小的情況,可以在一定程度上節約成本。