事務概念
資料庫操作的最小工作單元,是作為單個邏輯工作單元執行的一系列操作,經典的事務場景是轉賬,A(id為3)給B(id為1)轉賬:
update user_account set balance = balance - 1000 where user_id = 3;
update user_account set balance = balance + 1000 where user_id = 1; 這兩個sql要保證必須同時成功或同時失敗,否則資料将出現不一緻的情況。
mysql中的事務
檢視mysql事務開啟狀态:
show variables like 'autocommit' 預設是ON。
mysql中開啟事務
會話級别
set session autocommit = on/off; 這個是對目前會話設定自動送出,對其他會話不起作用,如果設定為off,這時候執行完sql後,目前會話都要手動加上commit才能送出事務。
手動開啟
手動執行sql:
開啟事務:begin / start transaction;
送出或復原事務:commit / rollback JDBC程式設計中:
connection.setAutoCommit(boolean);
connection.commit(); Spring事務AOP程式設計:
expression=execution(com.faith.dao.*.*(..)) mysql中預設是自動送出事務的。也就是在你執行sql語句的時候,它會自動在你sql前邊加上begin或start transaction;在後邊自動加上commit;進而事務就會自動送出。
當手動使用begin或start transaction時,mysql就會取消自動加事務,例如:
begin;
update user set name="faith" where id=1; 執行後,資料庫id為1的記錄并不會改變,因為這時候mysql不會自動送出,當手動執行commit之後才會進行送出。
而因為mysql自動送出事務,是以如下兩個sql實際上是在兩個事務中的:
update user_account set balance = balance - 1000 where userID = 3;
update user_account set balance = balance +1000 where userID = 1; 那麼為了保證原子性,我們需要做如下操作:
begin;
update user_account set balance = balance - 1000 where userID = 3;
update user_account set balance = balance +1000 where userID = 1;
commit; 這樣就把這兩個sql放到一個事務中去了。
在jdbc中将兩個sql放到一個事務中,如下:
connection.setAutoCommit(boolean);
update user_account set balance = balance - 1000 where userID = 3;
update user_account set balance = balance +1000 where userID = 1;
connection.commit(); Spring事務AOP程式設計,實際上也是做了手動開啟操作:
expression=execution(com.faith.dao.*.*(..)) 這裡設定了一個切面,基于這個切面的所有方法都會被攔截,這些方法配置事務的傳播性質,攔截之後,spring會在方法之前加一個切面,設定會話手動送出,例如:
connection.setAutoCommit(boolean); 然後在方法之後加一個切面,設定會話送出,例如:
connection.commit(); 當catch到異常的時候,就執行
connection.rollback(); 事務的特性
原子性(Atomicity)
事務是最小的工作單元,事務中的sql要麼一起送出成功,要麼全部失敗復原。
一緻性(Consistency)
事務中操作的資料及狀态改變是一緻的,更新的資料必須完全符合預設的規則,不會因為事務或系統等原因導緻狀态的不一緻。
隔離性(Isolation)
一個事務所操作的資料在送出之前,對其他事務的可見性設定。如果事務并發且互相不隔離,會導緻髒讀、不可重複讀、幻讀等系列問題。
持久性(Durability)
事務所做的修改會永久儲存,不會因為系統意外導緻資料的丢失。
原子性和一緻性是兩個不同的概念。對于原子性來說,如下的兩條語句:
update user_account set balance = balance - 1000 where userID = 3;
update user_account set balance = balance +10000 where userID = 1; 隻要同時執行成功或失敗就是符合原子性的。
而對于一緻性來說是不成立的,因為實際給1轉賬1000,但是1的賬戶上多了10000,不符合轉賬的規則,導緻了資料的不一緻性。
事務的隔離級别
SQL92 ANSI/ISO标準
http://www.contrib.andrew.cmu.edu/~shadow/sql/sql1992.txt
Read Uncommitted(讀未送出)
--未解決任何并發問題,可以讀到其他事務未送出的資料,會導緻髒讀(dirty read)。
Read Committed(讀已送出)
--解決髒讀問題,一個事務開始之後,隻能看到己送出的事務所做的修改,但是未解決不可重複讀(nonrepeatable read)。
Repeatable Read (可重複讀)
--解決不可重複讀問題,在同一個事務中多次讀取同樣的資料結果是一樣的,這種隔離級别未定義解決幻讀的問題。
Serializable(串行化)
--解決所有問題,最高的隔離級别,通過強制事務的串行執行。 innodb對隔離級别的支援
| 隔離級别 | 髒讀 | 不可重複讀 | 幻讀 |
|---|---|---|---|
| 讀未送出 | 可能 | ||
| 讀已送出 | 不可能 | ||
| 可重複讀 | ==不可能== | ||
| 串行化 |
在92标準中,可重複讀級别可以不解決幻讀問題,但是innodb存儲引擎的可重複讀解決了幻讀問題。
鎖
鎖用來管理不同僚務對共享資源的并發通路。
表鎖與行鎖:
鎖定粒度:表鎖 > 行鎖
表鎖直接鎖定表,行鎖隻鎖定一行。
加鎖效率:表鎖 > 行鎖
直接對表加鎖塊,而行鎖需要在表中找到指定的行記錄。
沖突機率:表鎖 > 行鎖,表鎖鎖定的記錄更多,更容易産生沖突。
并發性能:表鎖 < 行鎖 InnoDB存儲引擎隻有行鎖,沒有表鎖,但它也能實作表鎖的效果,因為它的表鎖是把表中所有的行都鎖一遍,就成了表鎖。這個隻是實作了表鎖的效果,但是和真正的表鎖效率相比要低下很多。
innodb的鎖類型
InnoDB預設select語句不加任何鎖類型,但是delete、update、insert 預設會加上X鎖。
innodb共有八種鎖:
共享鎖(行鎖):Shared Locks
排它鎖(行鎖):Exclusive Locks
意向鎖共享鎖(表鎖):Intention Shared Locks
意向鎖排它鎖(表鎖):Intention Exclusive Locks
自增鎖:AUTO-INC Locks
關于行鎖的鎖:
記錄鎖 Record Locks
間隙鎖 Gap Locks
臨鍵鎖 Next-key Locks 共享鎖
又稱為讀鎖,簡稱S鎖,多個事務對于同一資料可以共享一把共享鎖,持有共享鎖的事務都能通路到資料,但是隻能讀不能修改。
共享鎖示例:
begin;
select * from user WHERE id=1 LOCK IN SHARE MODE; 不執行commit操作,這時候在另一個視窗執行:
select * from user WHERE id=1;
update user set name='2' where id=1; select操作可以查到資料,但是update會被阻塞,直到最開始申請到共享鎖的事務執行commit或rollback來釋放享鎖,之後update才會繼續執行。
排他鎖
又稱為寫鎖,簡稱X鎖,排他鎖不能與其他鎖并存,如一個事務擷取了某條記錄的排他鎖,其他事務就不能再擷取該行的鎖(共享鎖、排他鎖),即不能讀不能寫,隻有持有排他鎖的事務才可以對記錄進行讀取和修改(其他事務要讀取資料可來自于快照)。
排它鎖示例:
begin;
update user set name='2' where id=1; select * from user WHERE id=1 LOCK IN SHARE MODE;
update user set name='3' where id=1; 這兩條操作都會被阻塞,直至持有排它鎖的事務commit或rollback之後才能繼續執行。
意向共享鎖(IS)
表示事務準備給資料行加入共享鎖,即一個資料行加共享鎖前必須先取得該表的IS鎖,意向共享鎖之間是可以互相相容的。
意向排它鎖(IX)
表示事務準備給資料行加入排他鎖,即一個資料行加排他鎖前必須先取得該表的IX鎖,意向排它鎖之間也是可以互相相容的。
意向鎖(IS 、IX)是InnoDB在資料操作之前自動加的,不需要使用者幹預,我們編碼時不需要對意向鎖進行特殊處理。
意向鎖是表級鎖,之間是互相相容的,也就是說多個持有鎖的線程,可以同時持有意向鎖。比如update id=1,update id=2,他們可以同時持有意向鎖。
意向鎖存在的意義:
隻有當事務想去進行鎖表時,意向鎖才會發揮作用,事務會先判斷意向鎖是否存在,如果存在,說明此時肯定有行鎖存在,這時候不能進行表鎖,則可快速傳回該表不能啟用表鎖,省略了進入底層掃描全表的資料。
自增鎖
針對自增列自增長的一個特殊的表級别鎖,可以使用如下語句檢視自增鎖的模式:
show variables like 'innodb_autoinc_lock_mode'; 此參數可取的值有三個:0、1、2,預設取值1。
取值0:傳統方式,串行自增,并且是連續的。這種模式下需要語句執行完成才釋放自增鎖,是以性能最低。例如:1、2、3、4、5、6,沒有人為删除情況下,表中id字段一定是連續的。
取值1:連續方式,自增的,并且是連續的。當語句申請到自增鎖就釋放自增鎖,自增鎖就可以給其它語句使用,性能會好很多。但因為不會等待語句事務執行完畢就釋放了自增鎖,可能該事務復原了,是以id可能會出現斷續的情況,例如:1、2、6,8,10
2:交錯方式,多語句插入資料時,有可能自增的序列号和執行先後順不一緻,并且中間可能有斷裂。一次配置設定一批自增值,然後下個語句就再進行配置設定一批自增值,阻塞很小,性能很高。例如:1、2、3、6、5。
設定為2時,需要确認表是否需要連續的自增值,如果需要,就不要使用這個值。
臨鍵鎖(Next-key locks)
當sql執行按照索引進行檢索,查詢條件為範圍查找(between and、<、>等)并且有資料命中,則此時SQL語句加上的鎖為Next-key locks,鎖住索引範圍為記錄的本區間 + 本區間下一個區間(左開右閉)。
mysql會對記錄自動劃分出區間,如下:
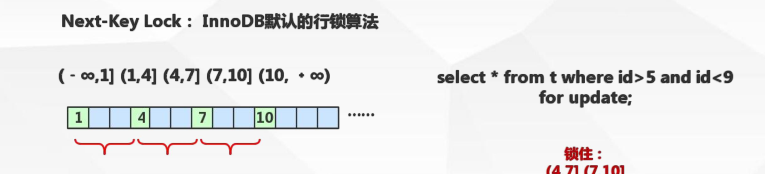
如果為1,2,4,7,10,區間則為(-&,1],(1,2],(2,4],(4,7],(7,10],(10,+&)。劃分區間是依據B+樹節點之間的間隙來劃分的,1和2之間沒有間隙,但是在樹中,是兩個不同的節點,它們之間是有間隙的。
update user set name=1 where id>5 and id<10 上面的sql選中的記錄是id=7,這時候鎖住的區間是(4,7],(7,10],(4,7]是本區間,而(7,10]是本區間的下一個區間。
鎖住本區間和相鄰區間就是防止幻讀,例如這裡的>5和<9條件,肯定是要鎖定(4,7],(7,10]區間才能實作的,也就是要鎖住本區間和相鄰區間。
鎖住區間是因為B+樹的特性,如果把這個例子中的id換成age就更好了解了。
因為innodb預設隔離級别是可重複讀,而前邊說了innodb的可重複讀還捎帶解決了幻讀問題,而幻讀問題就是臨鍵鎖配合mvcc一起解決的。
間隙鎖(Gap locks)
當sql執行按照索引進行檢索,查詢條件為範圍查找并且查詢的資料不存在,這時SQL語句加上的鎖即為Gap locks,鎖住索引不存在的區間(左開右開)。
隻在可重複讀隔離級别存在是因為innodb的可重複讀解決了幻讀問題。
Record locks
當sql執行按照唯一性(Primary key、Unique key)索引進行檢索,查詢條件為精準等值匹
配且查詢的資料是存在,這時SQL語句加上的鎖即為記錄鎖Record locks,這種情況隻針對唯一索引,是以對應的是const或equ_ref級别的查詢。
innodb的行鎖鎖住了哪些内容
得出結論之前先做個測試。例如user表中,id,name,age,create_time字段,id和name有索引,create_time沒有加索引。
測試1
begin;
select * from user where id=1; 不執行commit或rollback。然後在其他線程執行:
select * from user where id=1; 阻塞
select * from user where id=2; 非阻塞
select * from user where id=3; 非阻塞 測試2
begin;
select * from user where name=‘1’; select * from user where name=‘1’; 阻塞
select * from user where name=‘2’; 非阻塞
select * from user where name=‘3’; 非阻塞 測試3
begin;
select * from user where create_time=1; select * from user where create_time=1; 阻塞
select * from user where create_time=2; 阻塞
select * from user where create_time=3; 阻塞 結論:InnoDB的行鎖是通過給索引樹中的索引項加鎖來實作的,如果是聚集索引,那麼直接鎖住聚集索引的索引項,如果是非聚集索引,那麼會鎖住目前索引的索引項,以及對應的聚集索引中的索引項。
也就是說對于非聚集索引,會在兩棵索引樹中分别上鎖。隻有通過索引條件進行資料檢索,InnoDB才使用行級鎖,否則,InnoDB将使用表鎖(鎖住索引的所有記錄)。
表鎖是非常耗費性能的,是以要避免表鎖。這種特性可以給平時寫sql帶來一些啟發,例如:
delete from user where create_time;導緻表鎖
delete from user where id=1;行鎖; 寫删改的sql時候,要考慮where條件是否命中了索引,要避免表鎖出現,删一條記錄,卻導緻整張表被鎖住了,這是一件很郁悶的事。
鎖如何解決并發問題
加上X鎖可以解決髒讀。
模拟不可重複讀:
select name from user where id=1;// name='1'
update user set name='2' where id=1; // 執行成功
select name from user where id=1;// name='2' 上面兩個select的結果不同,導緻了不可重複讀。解決方法是給這兩個select加上S鎖:
select name from user where id=1 LOCK IN SHARE MODE;// name='1'
update user set name='2' where id=1; // 阻塞
select name from user where id=1 LOCK IN SHARE MODE;// name='1' 這樣在目前事務執行完畢之前,不可能被其他事務更改值,進而解決了不可重複讀的問題。
加臨鍵鎖可以解決幻讀。
死鎖
多個并發事務每個事務都持有鎖,每個事務都需要再繼續持有其他事務持有的鎖,但誰都不釋放自己手中的鎖,産生鎖的循環等待,這就形成了死鎖。
死鎖的避免
類似的業務邏輯以固定的順序通路表和行。
大事務拆小。大事務更傾向于死鎖,如果業務允許,将大事務拆小。
在同一個事務中,盡可能做到一次鎖定所需要的所有資源,減少死鎖機率。
降低隔離級别,如果業務允許,将隔離級别調低也是較好的選擇
為表添加合理的索引。可以看到如果不走索引将會為表的每一行記錄添加上鎖(或者說是表鎖),表鎖造成的鎖沖突比行鎖要嚴重的多 ![GitHub連夜封殺!這份阿裡 10W 字内部 Java 字面試手冊到底有多強?[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)