一、業務背景
業務上需要通過對二級類目的聚合,輸出每個類目下排名30天銷量排名TOP100的商品資訊。抽象到SQL層面就是:通過對X字段的分組,擷取每個分組前N條資料。
二、原始方案
說實話,這個方法有些low,但起碼能實作功能。使用存儲過程,思路如下:
1.建立一張臨時表先放着:create temp_top_by_catename2
2.查詢所有的二級類目: select distict cate_level2_name from xxx where ds=max_pt('xxx')
3.将cate_level2_name存儲在變量數組中catename[];
4.遊标周遊catename[];select * from xxx as a where a.cate_level2_name=catename order by sales_count_30 desc limit 100
将每個二級類目的查詢結果insert到temp_top_by_catename2表
方案缺點:
(1)時間成本太高,因為有多少個catename分組,就要查詢N次表,更改插入N次表。跑了30小時才插了<100個類目分組
(2)另外表基數量很大,每次查詢計劃的cost值很高。
(3)如果SQL有中斷,資料的完整性很難保證
三、優化方案
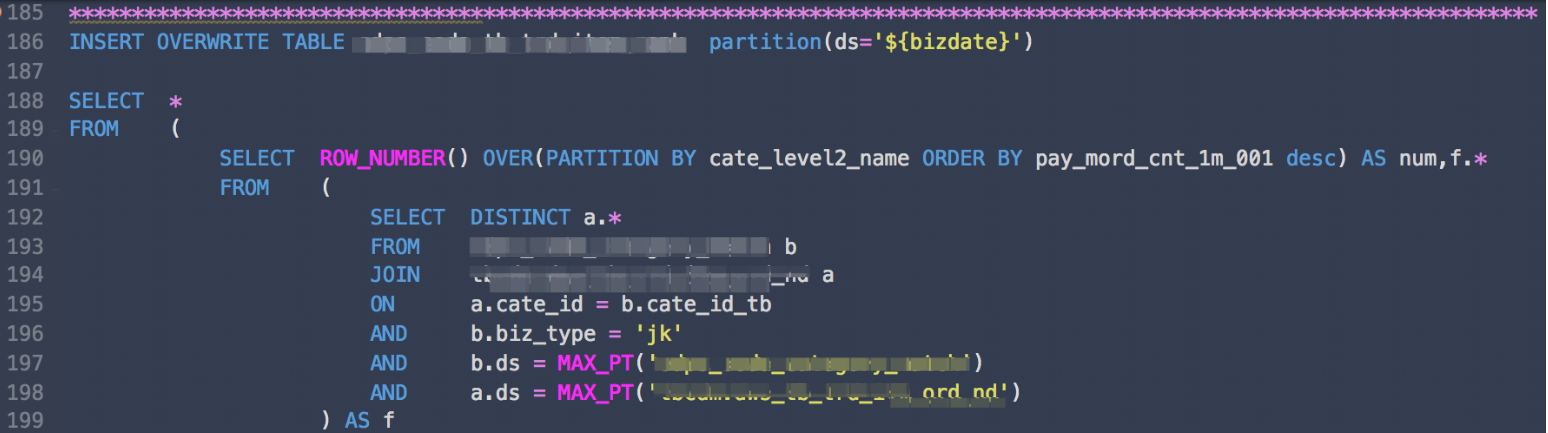
基于上述方案的種種不爽,問自己一個問題,能否一條語句可以解決Group+Order+topN輸出?于是開始了度娘之旅,但都是些嵌套+子查詢的方式曲線救國,并達不到想要的效果。在試,從ODPS的函數着手,翻了一遍返現隻有一個神奇API貌似像,名字給出:“row_num”.先普及下這個函數的定義:
文法:row_number() over (partition by 分組字段 order by 排序字段 desc ) as topNum
拆解:
(1)partition by :按照某一字段進行分組
(2)order by:分組之後按照該字段進行升序或降序排列
(3)topNum:自定義的名字,就是後面我們要用到的TOPN,同步資料時可設定成變量,動态調整
四、源碼
五、性能結果

自此 over,知識有限,大家如有更好的方案歡迎私聊。