1.概述
TimescaleDB是
Timescale Inc.(成立于2015年)開發的一款号稱相容全SQL的 時序資料庫 。它的本質是一個基于 PostgreSQL(以下簡稱 PG )的擴充( Extension ),主打的賣點如下:
- 全SQL支援
- 背靠PostgreSQL的高可靠性
- 時序資料的高寫入性能
下文将對TimescaleDB這個産品進行解讀。如無特殊說明,這裡所說的TimescaleDB均是指
Github上開源的單機版TimescleDB的v1.1版本。
https://www.atatech.org/articles/131405#1 2.資料模型
由于TimescaleDB的根基還是PG,是以它的資料模型與NoSQL的時序資料庫(如我們的阿裡時序時空TSDB,InfluxDB等)截然不同。
在NoSQL的時序資料庫中,資料模型通常如下所示,即一條資料中既包括了時間戳以及采集的資料,還包括裝置的中繼資料(通常以 Tagset 展現)。資料模型如下所示:
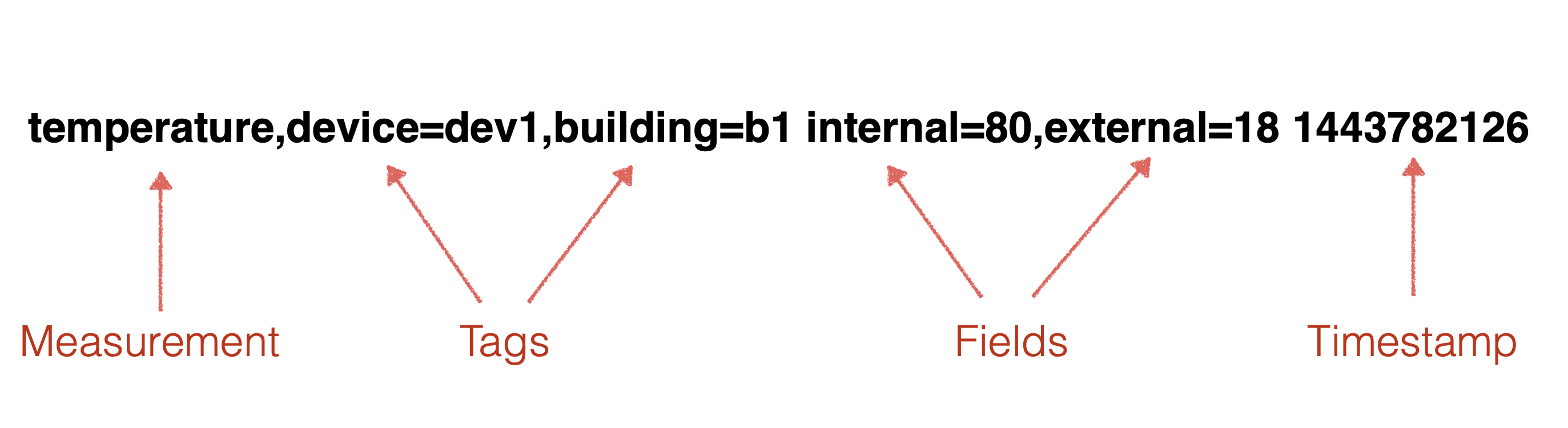
但是在TimescaleDB中,資料模型必須以一個二維表的形式呈現,這就需要使用者結合自己使用時序資料的業務場景,自行設計定義二維表。
在TimescaleDB的官方文檔中,對于如何設計時序資料的資料表,給出了兩個範式:
- Narrow Table
- Wide Table
所謂的 Narrow Table 就是将metric分開記錄,一行記錄隻包含一個 metricValue - timestamp 。舉例如下:
| metric名 | 屬性1 | 屬性2 | 屬性3 | 時間戳 | |
|---|---|---|---|---|---|
| free_mem | 裝置1屬性1值 | 裝置1屬性2值 | 裝置3屬性3值 | xxxxxxx | timestamp1 |
| 裝置2屬性1值 | 裝置2屬性2值 | 裝置2屬性3值 | |||
| 裝置3屬性1值 | 裝置3屬性2值 | ||||
| temperature | △△△△△△△ | ||||
而所謂的 Wide Table 就是以時間戳為軸線,将同一裝置的多個metric記錄在同一行,至于裝置一些屬性(中繼資料)則隻是作為記錄的輔助資料,甚至可直接記錄在别的表(之後需要時通過 JOIN 語句進行查詢)
| metric名1 | metric名2 | metric名3 | ||||
|---|---|---|---|---|---|---|
| 裝置1屬性3值 | metric值1 | metric值2 | metric值3 | |||
| timestamp2 |
基本上可以認為: Narrow Table 對應的就是 單值模型 ,而Wide Table對應的就是 多值模型
由于采用的是傳統資料庫的關系表的模型,是以TimescaleDB的metric值必然是強類型的,它的類型可以是PostgreSQL中的 數值類型 , 字元串類型 等。
https://www.atatech.org/articles/131405#2 3.TimescaleDB的特性
TimescaleDB在PostgreSQL的基礎之上做了一系列擴充,主要涵蓋以下方面:
- 時序資料表的透明自動分區特性
- 提供了若幹面向時序資料應用場景的特殊SQL接口
- 針對時序資料的寫入和查詢對PostgreSQL的 Planner 進行擴充
- 面向時序資料表的定制化并行查詢
其中 3 和 4 都是在PostgreSQL的現有機制上進行的面向時序資料場景的微創新。是以下文将主要對上述的 1 和 2 稍加展開說明
https://www.atatech.org/articles/131405#3 透明自動分區特性
在時序資料的應用場景下,其記錄數往往是非常龐大的,很容易就達到 數以billion計 。而對于PG來說,由于大量的還是使用B+tree索引,是以當資料量到達一定量級後其寫入性能就會出現明顯的下降(這通常是由于索引本身變得非常龐大且複雜)。這樣的性能下降對于時序資料的應用場景而言是不能忍受的,而TimescaleDB最核心的 自動分區 特性需要解決就是這個問題。這個特性希望達到的目标如下:
- 随着資料寫入的不斷增加,将時序資料表的資料分區存放,保證每一個分區的索引維持在一個較小規模,進而維持住寫入性能
- 基于時序資料的查詢場景,自動分區時以時序資料的時間戳為分區鍵,進而確定查詢時可以快速定位到所需的資料分區,保證查詢性能
- 分區過程對使用者透明,進而達到Auto-Scalability的效果
TimescaleDB對于自動分區的實作,主要是基于PG的
表繼承機制進行的實作。TimescaleDB的自動分區機制概要可參見下圖:

在這個機制下, 使用者建立了一張普通的時序表後,通過TimescaleDB的接口進行了hyper table注冊後,後續的資料寫入和查詢操作事實上就由TimescaleDB接手了。上圖中,使用者建立的原始表一般被稱為“主表”(main table), 而由TimescaleDB建立出的隐藏的子表一般被稱為“chunk”
需要注意的是,chunk是伴随着資料寫入而自動建立的,每次建立新的chunk時會計算這個chunk預計覆寫的時間戳範圍(預設是 一周 )。且為了考慮到不同應用場景下,時序資料寫入速度及密度都不相同,對于建立新分區時,新分區的時間戳範圍會經過一個自适應算法進行計算,以便逐漸計算出某個應用場景下最适合的時間戳範圍。與PG 10.0
自适應算法的詳細實作位于TimescaleDB的
chunk_adaptive.c
的
ts_calculate_chunk_interval()
,其基本思路就是基于曆史chunk的 時間戳填充因子 以及 檔案尺寸填充因子 進行合理推算下一個chunk應該按什麼時間戳範圍來進行界定。
借助 透明化自動分區 的特性,根據官方的測試結果,在同樣的資料量級下,TimescaleDB的寫入性能與PG的 傳統單表 寫入場景相比,即使随着數量級的不斷增大,性能也能維持在一個比較穩定的狀态。
注: 上述Benchmark測試結果摘自
Timescale官網https://www.atatech.org/articles/131405#4 面向時序場景的定制功能
TimescaleDB的對外接口就是SQL,它100%地繼承了PG所支援的全部SQL特性。除此之外,面向時序資料庫的使用場景,它也定制了一些接口供使用者在應用中使用,而這些接口都是通過 SQL函數(标準名稱為
User-defined Function)予以呈現的。以下列舉了一些這類接口的例子:
-
time_bucket()
函數
該函數用于 降采樣 查詢時使用,通過該函數指定一個時間間隔,進而将時序資料按指定的間隔降采樣,并輔以所需的聚合函數進而實作降采樣查詢。一個示例語句如下:
将資料點按5分鐘為機關做降采樣求均值SELECT time_bucket('5 minutes', time) AS five_min, avg(cpu) FROM metrics GROUP BY five_min ORDER BY five_min DESC LIMIT 10; -
新增的聚合函數
為了提供對時序資料進行多樣性地分析查詢,TimescaleDB提供了下述新的聚合函數。
-
first()
-
last()
-
histogram()
-
-
drop_chunks()
drop_chunks()
drop_chunks()
conditions
SELECT drop_chunks(older_than => interval '3 months', newer_than => interval '4 months', table_name => 'conditions');
除此之外,TimescaleDB定制的一些接口基本都是友善資料庫管理者對中繼資料進行管理的相關接口,在此就不贅述。包括以上接口在内的定義和示例可參見
官方的API文檔https://www.atatech.org/articles/131405#5 4.TimescaleDB的存儲機制
TimescaleDB對PG的存儲引擎未做任何變更,是以其索引資料和表資料的存儲都是沿用的PG的存儲。而且,TimescaleDB給chunk上索引時,都是使用的預設的B+tree索引,是以每一個chunk中資料的存儲機制可以參見下圖:
關于這套存儲機制本身不用過多解釋,畢竟TimescaleDB對其沒有改動。不過考慮到時序資料庫的使用場景,可以發現TimescaleDB的Chunk采用這套機制是比較合适的:
- PG存儲的特征是 隻增不改 ,即無論是資料的插入還是變更。展現在Heap Tuple中都是Tuple的Append操作。是以這個存儲引擎在用于OLTP場景下的普通資料表時,會存在 表膨脹 問題;而在時序資料的應用場景中,時序資料正常情況下不會被更新或删除,是以可以避免表膨脹問題(當然,由于時序資料本身寫入量很大,是以也可以認為海量資料被寫入的情況下單表實際上仍然出現了膨脹,但這不是此處讨論的問題)
- 在原生的PG中,為了解決表膨脹問題,是以PG記憶體在 AUTOVACUUM 機制,即自動清理表中因更新/删除操作而産生的“Dead Tuple”,但是這将會引入一個新的問題,即AUTOVACUUM執行時會對表加共享鎖進而對寫入性能的影響。但是在時序資料的應用場景中,由于沒有更新/删除的場景,也就不會存在“Dead Tuple“,是以這樣的Chunk表就不會成為AUTOVACUUM的對象,是以INSERT性能便不會受到來自這方面的影響。
至于對海量資料插入後表和索引增大的問題,這正好通過上述的 自動分區 特性進行了規避。
此外,由于TimescaleDB完全基于PG的存儲引擎,對于 WAL 也未做任何修改。是以TimescaleDB的高可用叢集方案也可基于PG的流複制技術進行搭建。
TimescaleDB官方也介紹了一些基于開源元件的HA方案https://www.atatech.org/articles/131405#6 5.小結
綜上所述,由于TimescaleDB完全基于PostgreSQL建構而成,是以它具有若幹與生俱來的 優勢 :
- 100%繼承PostgreSQL的生态。且由于完整支援SQL,對于未接觸過時序資料的初學者反而更有吸引力
- 由于PostgreSQL的品質值得信賴,是以TimescaleDB在品質和穩定性上擁有品牌優勢
- 強ACID支援
當然,它的 短闆 也是顯而易見的
- 由于隻是PostgreSQL的一個Extension,是以它不能從核心/存儲層面針對時序資料庫的使用場景進行極緻優化。
- 目前的産品架構來看仍然是一個單機庫,不能發揮分布式技術的優勢。而且資料雖然自動分區,但是由于時間戳決定分區,是以很容易形成I/O熱點。
- 在功能層面,面向時序資料庫場景的特性還比較有限。目前更像是一個 傳統OLTP資料庫 + 部分時序特性 。
不管怎樣,TimescaleDB也算是面向時序資料庫從另一個角度發起的嘗試。在目前時序資料庫仍然處于新興事物的階段,它未來的發展方向也是值得我們關注并借鑒的。
阿裡雲時序時空資料庫TSDB 1元購!立即體驗:
https://promotion.aliyun.com/ntms/act/tsdbtry.html?spm=5176.149792.775960.1.dd9e34e2zgsuEM&wh_ttid=pc