标簽(空格分隔): Spark
[toc]
intro
dataset和operation
Spark對資料集合的基本抽象叫做Dataset。Dataset可以從檔案直接建立,也可以從其他dataset經過transform變換而來。具體變換操作比如:
textFile.map(line => line.split(" ").size).reduce((a, b) => if (a > b) a else b) 這個transform會将資料映射為數字并計算最大值。這裡有map操作,有reduce操作,每個操作後都會轉換為一個新的Dataset。而這就是Spark支援的MapReduce模型的data flow。
cache
Spark也支援把資料集拉倒cluster-wide下的記憶體cache中進行緩存。這對于資料重複讀取非常有幫助,當疊代過程中有熱點資料時可以進行資料集緩存。
運作程式的簡單例子
/* SimpleApp.scala */
import org.apache.spark.sql.SparkSession
object SimpleApp {
def main(args: Array[String]) {
val logFile = "YOUR_SPARK_HOME/README.md" // Should be some file on your system
val spark = SparkSession.builder.appName("Simple Application").getOrCreate()
val logData = spark.read.textFile(logFile).cache()
val numAs = logData.filter(line => line.contains("a")).count()
val numBs = logData.filter(line => line.contains("b")).count()
println(s"Lines with a: $numAs, Lines with b: $numBs")
spark.stop()
}
} RDD
Spark程式包含了一個驅動程式來運作使用者的main函數,并在叢集中執行各種并行操作。Spark的主要抽象概念叫做RDD(resilient distributed dataset),就是彈性分布式資料集——一組分布在叢集中不同節點上的可以被并行操作的元素的集合。RDD可以通過一個HDFS的檔案系統建立檔案得到,也可以通過在驅動程式裡利用已有的Scala集合并轉換得到。一般使用者會請求Spark将RDD在存儲在記憶體中,進而可以在并行操作中重複利用。當然,RDD提供當執行節點出錯後的自動回複能力。
再一個對Spark的抽象就是并行操作中共享變量。預設情況下,當Spark在不同節點上以一組task并行運作一個函數時,它會将這個函數用到的變量傳遞給每個task。有時候一個變量需要被跨任務共享、在任務和驅動程式間共享。Spark支援兩種共享變量類型:廣播變量,在所有節點的記憶體中緩存一個值;accumulators累加器,意味着這些變量是可加的,比如counter和sum等。
準備
Spark程式準備運作需要建立基礎的SparkContext對象,一個JVM裡隻允許有一個active的SparkContext對象,是以如果已經存在,需要stop()掉。準備工作的代碼如下:
val conf = new SparkConf().setAppName(appName).setMaster(master)
new SparkContext(conf) 其中appName是用來UI展示的,而master是一個cluster的url。
并行集合
并行集合是通過在驅動程式中調用SparkContext的parallelize方法來建構的。比如如下代碼:
val data = Array(1, 2, 3, 4, 5)
val distData = sc.parallelize(data) 會構造一個并行集合1-5.
并行集合一個最重要的參數就是将dataset切成幾個partition。Spark在每個partition上會啟動一個task運作。比較典型的情況會為叢集的每個CPU選擇2-4個分區數量。一般Spark會根據叢集的情況自動設計分區數量。當然也可以手動set這個參數,比如
sc.parallelize(data, 10)
。
外部dataset
Spark支援從任意Hadoop支援的檔案系統加載外部Dataset,包括本地檔案系統、HDFS、Cassandra、Hbase、Amazon S3等。Spark支援文本檔案、SequenceFile和任意Hadoop InputFormat。
比如如下代碼:
val distFile = sc.textFile("data.txt") 需要注意的幾點:
- 如果加載本地檔案系統,檔案必須可以被所有的worker節點加載,是以需要網絡共享副本到每個worker。
- 所有的Spark的基于檔案的input方法,都支援在目錄、壓縮檔案甚至wildcard的方式,比如,可以使用
textFile("/my/directory")
textFile("/my/directory/*.txt")
textFile("/my/directory/*.gz")
- textFile方法也可以支援第二個參數來控制檔案的分區數。預設Spark為HDFS檔案的每個block建構一個分區(一個block預設是128MB大小),但也可以修改這個大小。注意不可以少于block個數個partition。
Spark的scala api也支援其他資料格式:
-
SparkContext.wholeTextFiles
textFile
wholeTextFiles
- 對于SequenceFile,使用
SparkContext’s sequenceFile[K, V]
Writable
IntWritable
Text
sequenceFile[Int, String]
- 對于其他的Hadoop InputFormats,你可以使用
SparkContext.hadoopRDD
SparkContext.newAPIHadoopRDD
-
RDD.saveAsObjectFile
SparkContext.objectFile
RDD操作
RDD支援兩種操作類型:transformation變換,即将一個已有的Dataset變換為一個新的dataset,也包含通過對一個dataset進行一系列計算傳回一個值給驅動程式。比如,map就是一個将一個dataset的元素通過一個函數變換為一個新的RDD的一種變換操作。另一操作就是reduce,它是将一個RDD的元素通過一個函數聚合成一個值給驅動程式。
Spark裡所有的變換都是lazy的,也就是說他們不是馬上計算出結果。它隻是會記住對基礎dataset進行的所有變換操作。變換操作隻有在一個動作需要結果傳回給驅動程式時才會計算。這種設計使Spark運作的更加高效。比如,我們可以實作一個通過map建立dataset再用于reduce進而傳回給driver,而不是一個大的dataset。
預設情況下,每個變換過的RDD可以在每次運作一個動作時被重新計算。然而也可以使用
persist
或者
cache
方法來持久化到記憶體,這樣Spark可以将結果緩存到cluster以便下次查詢時獲得更快的速度。Spark也支援将結果RDD持久化到磁盤,或者複制到多個節點。
基礎
看一個代碼片段就明白
val lines = sc.textFile("data.txt")
val lineLengths = lines.map(s => s.length)
val totalLength = lineLengths.reduce((a, b) => a + b) 首先定義了一個外部檔案為一個RDD,這時lines不是記憶體中的資料,隻是一個指針指向檔案。然後經過一個map操作變換為一個新RDD——lineLengths。同理lineLengths也不是馬上計算的,也是lazy的。直到最後reduce觸發動作,Spark開始将計算分為多個task來運作在獨立的機器上,每個機器單獨計算配置設定的map部分資料和本地reduce,最終将結果傳回driver程式。
其中lineLengths要想複用,可以
lineLengths.persist()
來進行記憶體持久化,這個操作是在reduce前就會觸發執行的。
給Spark傳遞函數
Spark的API嚴重依賴通過驅動程式将函數傳遞下去以便運作在叢集中。有兩種推薦的做法:
- 匿名函數文法,可以作為代碼片段。
- 全局單例對象的static方法。比如可以定義一個object叫MyFunctions,然後傳遞
MyFunctions.func1
object MyFunctions {
def func1(s: String): String = { ... }
}
myRdd.map(MyFunctions.func1) 也可以在類内部傳遞函數引用,比如:
class MyClass {
def func1(s: String): String = { ... }
def doStuff(rdd: RDD[String]): RDD[String] = { rdd.map(func1) }
} 這樣如果有新的類執行個體産生,就要傳遞全部的object到叢集中,類似的做法如下:
class MyClass {
val field = "Hello"
def doStuff(rdd: RDD[String]): RDD[String] = { rdd.map(x => field + x) }
} 最簡單的方法是把field拷貝到一個本地變量,而不是做對象傳遞,如下:
def doStuff(rdd: RDD[String]): RDD[String] = {
val field_ = this.field
rdd.map(x => field_ + x)
} 了解閉包
關于Spark最難了解的事情之一就是了解在叢集中跨機器執行一段代碼時其中變量和方法的scope和生命周期。RDD操作從其scope外部修改變量就是一個讓人困惑的例子。下面舉個例子:
var counter = 0
var rdd = sc.parallelize(data)
// Wrong: Don't do this!!
rdd.foreach(x => counter += x)
println("Counter value: " + counter) 這裡RDD做了一個sum操作。這個代碼會根據是否在同一個JVM中運作而導緻行為不同。比如在local模式和cluster模式下,表現就不一樣。
這段代碼的行為是未定義的,可能會根據實際情況表現出不同的行為。為了執行這個作業,Spark會将RDD處理操作劃分為若幹個task,每個task被一個executor執行。執行前,Spark先計算task的閉包,閉包就是那些在操作計算RDD時對executor可見的變量和方法。這個閉包會被序列化并發送給每個執行器。
閉包裡的變量是多份拷貝,此例中的counter就是一個在foreach中的引用,而不是driver節點的counter。driver節點記憶體中是會有個counter,但不再是被執行器可見的counter。執行器隻會看到傳遞給它的序列化的閉包中的counter的拷貝副本。這樣,這段代碼執行後counter還是0,因為每個執行器執行的counter都是自己閉包中的變量副本。
在local模式下,在某種環境下,foreach函數會确實的在driver所在的同一個JVM中執行,引用的就将是同一個counter,那麼這時結果是正确的。
為了確定這種場景下的代碼行為是well-defined,Spark提供了Accumulator。累加器在Spark中可以用來提供一種安全更新變量機制,當執行計算被劃分到叢集中的多個工作節點時就會有用。
通常,閉包像一個本地方法或者循環體,不應該被用來改變一些全局狀态值。Spark沒有明确定義或者說能保證在閉包外引入對象的可變性。有時候local模式下使用沒問題,二同樣的代碼在分布式模式下可能就出問題。盡量使用Accumulator來做全局聚合。
還有一個值得提一下的就是Spark的列印方法,預設的print會發生在executor端而不是在driver程式中,這導緻無法看到過程。通過
collect
方法可以将RDD彙總到driver所在的機器上,通過
rdd.collect().foreach(println)
方法。但是這會導緻driver迅速耗盡記憶體,因為所有的rdd都會彙總過來。正确的姿勢應該是取樣輸出,使用
take
方法,通過
rdd.take(100).foreach(println)
來抽樣部分資料。
KV對怎麼操作
盡管大多數的Spark RDD操作可以支援任意類型的對象,但是一種特殊操作隻對key-value對生效。最典型的就是分布式的"shuffle"操作,比如根據一個key來grouping或者aggreating。
在Scala裡,這些操作由
Tuple2
對象來提供(預設内置的tuple,一般是
(a,b)
這樣的形式)。KV對操作由
PairRDDFunctions
類來提供,它會自動包裝一組RDD tuple。比如下面的代碼:
val lines = sc.textFile("data.txt")
val pairs = lines.map(s => (s, 1))
val counts = pairs.reduceByKey((a, b) => a + b) 這個代碼片段會記錄每行記錄和出現次數為一個kv對,然後根據行作為key來reduce計算不同行的出現次數。後續可以再通過類似
counts.sortByKey()
來按行字典序排序這些kv對,再通過
counts.collect()
來彙總結果到driver程式。
Transformation
Spark支援的Transformation有如下的清單:
Action
| reduce | Aggregate the elements of the dataset using a function func (which takes two arguments and returns one). The function should be commutative and associative so that it can be computed correctly in parallel. |
| collect () | Return all the elements of the dataset as an array at the driver program. This is usually useful after a filter or other operation that returns a sufficiently small subset of the data. |
| count | Return the number of elements in the dataset. |
| first | Return the first element of the dataset (similar to take(1)). |
| take (n) | Return an array with the first n elements of the dataset. |
| takeSample (withReplacement, num, [seed]) | Return an array with a random sample of num elements of the dataset, with or without replacement, optionally pre-specifying a random number generator seed. |
| takeOrdered (n, [ordering]) | Return the first n elements of the RDD using either their natural order or a custom comparator. |
| saveAsTextFile (path) | Write the elements of the dataset as a text file (or set of text files) in a given directory in the local filesystem, HDFS or any other Hadoop-supported file system. Spark will call toString on each element to convert it to a line of text in the file. |
| saveAsSequenceFile (path) (Java and Scala) | Write the elements of the dataset as a Hadoop SequenceFile in a given path in the local filesystem, HDFS or any other Hadoop-supported file system. This is available on RDDs of key-value pairs that implement Hadoop's Writable interface. In Scala, it is also available on types that are implicitly convertible to Writable (Spark includes conversions for basic types like Int, Double, String, etc). |
| saveAsObjectFile | Write the elements of the dataset in a simple format using Java serialization, which can then be loaded using |
| countByKey | Only available on RDDs of type (K, V). Returns a hashmap of (K, Int) pairs with the count of each key. |
| foreach | Run a function func on each element of the dataset. This is usually done for side effects such as updating an Accumulator or interacting with external storage systems. Note : modifying variables other than Accumulators outside of the |
Spark RDD API也暴露了一些動作方法的異步化版本,比如
foreachAsync
就是針對
foreach
的異步版,它可以快速傳回一個FutureAction給調用者而不是阻塞在計算中。
Shuffle操作
Spark中一些特定操作會觸發一個shuffle事件。Spark利用shuffle機制來進行資料的重新分布,進而使跨分區資料重新來分組組織。一般在跨executors和機器中拷貝資料使得shuffle操作是一個複雜又耗費的操作。
首先了解一下為什麼要shuffle,我們可以通過一個
reduceByKey
操作來看下。該操作會産生一個新RDD,其中所有具有相同key的值都會被合并在一個tuple裡。顯然很有挑戰的一點就是不是所有資料會布置在一個分區中或者一台機器上,但是reduce計算确需要所有的資料一起參與。這就帶來跨機器跨分區問題。
在Spark中,資料一般不會跨分區分布。在計算過程中,一個task運作在一個分區上,是以為了組織
reduceByKey
操作執行需要的全部的資料,Spark需要進行一個all-to-all的操作。它必須從所有分區中讀出資料并且找到所有key的所有value,然後為每個key把跨分區的值彙聚在一起并計算該key的對應reduce值。整個這個過程就叫做shuffle。
shuffle帶來的新分區裡的資料和分區的順序是重要的,但是分區内元素的順序則不重要。如果需要元素資料也有序,那麼可以這麼做:
-
mapPartitions
.sorted
-
repartitionAndSortWithinPartitions
-
sortBy
會進行shuffle的操作包括:
repartition
,
coalesce
,還有ByKey類型的操作比如
groupByKey
reduceByKey
,還有
join
類型的操作比如
cogroup
join
shuffle是一個很昂貴的操作,因為它會帶來磁盤I/O、資料序列化和網絡I/O。為了組織shuffle過程中的資料,Spark會産生一系列task——map任務來組織資料和一系列reduce任務來聚合它們。這個命名和MapReduce相同但是與Spark内部的map和reduce操作不同。
在計算過程内部,單個map任務的結果存儲在記憶體中,直到超過容量。然後會按照目标分區來排序,并寫入單個檔案中。在reduce端,任務會讀取相關聯的排好序的block。
特定的shuffle操作可能會消耗大量的堆記憶體,因為它們完全在利用記憶體中的資料結構來組織其記錄和進行轉換。特殊情況是
reduceByKey
aggregateByKey
操作會在map端建立這些結構,而其他的
ByKey
操作都在reduce端産生。當資料超過記憶體限制時,Spark會将這些表轉到磁盤,這會加重磁盤I/O并且帶來大量的GC。
shuffle同時也會産出大量的中間磁盤檔案。在Spark1.3中,這些檔案會一直保留直到RDD不再需要才gc。這樣做是為了在重新計算依賴關系時不需要重新建立shuffle檔案。如果應用保持這些RDD的引用,那麼GC将不會頻繁發生,可能會在很長一段時間後進行。這意味着長時間運作的Spark作業可能會占用非常多的磁盤空間。臨時存儲目錄通過
spark.local.dir
配置項在配置Spark context時候設定。
shuffle行為可以通過很多配置項來調整。具體參考後續關于Spark配置項的文章。
RDD持久化
Spark中最重要的一項能力就是跨操作在記憶體中持久化dataset。當一個RDD被持久化後,每個節點存儲它在記憶體中計算的任何分區,并在該dataset的其他操作中重用它們。這使得很多後置的操作可以更快。caching是疊代算法和快速互動中的一個特别關鍵的工具。
可以通過使用
persist()
cache()
方法來持久化RDD。在第一次操作時儲存記錄在節點的記憶體中。Spark的cache是具備容錯性的,如果RDD的任何分區丢失,它都會通過原來建立它的操作重新計算得到。
每個持久化的RDD可以以不同的存儲等級來儲存,比如,持久資料集到磁盤,以Java序列化方式持久資料集到記憶體,并複制到多個節點。這些等級通過傳遞一個
StorageLevel
對象給
persist()
方法來實作。
cache()
方法是使用預設存儲等級的一個快捷方式——預設的等級是
StorageLevel.MEMORY_ONLY
,這種方式會在記憶體中存儲反序列化對象。完整的存儲等級如下:
| Storage Level | |
|---|---|
| MEMORY_ONLY | Store RDD as deserialized Java objects in the JVM. If the RDD does not fit in memory, some partitions will not be cached and will be recomputed on the fly each time they're needed. This is the default level. |
| MEMORY_AND_DISK | Store RDD as deserialized Java objects in the JVM. If the RDD does not fit in memory, store the partitions that don't fit on disk, and read them from there when they're needed. |
| MEMORY_ONLY_SER | Store RDD as serialized Java objects (one byte array per partition). This is generally more space-efficient than deserialized objects, especially when using a fast serializer , but more CPU-intensive to read. |
| MEMORY_AND_DISK_SER | Similar to MEMORY_ONLY_SER, but spill partitions that don't fit in memory to disk instead of recomputing them on the fly each time they're needed. |
| DISK_ONLY | Store the RDD partitions only on disk. |
| MEMORY_ONLY_2, MEMORY_AND_DISK_2, etc. | Same as the levels above, but replicate each partition on two cluster nodes. |
| OFF_HEAP (experimental) | Similar to MEMORY_ONLY_SER, but store the data in off-heap memory . This requires off-heap memory to be enabled. |
具體使用時如何選擇呢?Spark的存儲等級是為了提供多種在記憶體和CPU使用率中的trade-off政策的。官方有如下的推薦:
- 如果RDD大小适中,那就用預設級别。這是CPU使用率最高的選擇。
- 如果RDD大小不合适,先嘗試用
MEMORY_ONLY_SER
- 别輕易spill到磁盤除非dataset的計算非常昂貴或者dataset包含了非常巨大的資料量。這樣重新計算分區可能和從磁盤讀取速度一樣快。
- 在期望快速回複資料錯誤時使用帶副本的存儲等級。所有的存儲等級都提供丢失資料的重新計算這樣的容錯能力,隻不過帶副本的模式可以允許在丢失資料時繼續進行RDD計算而不是等待對一個丢失分區的重新計算。
Spark會自動監視每個節點上的緩存使用情況,并以最近最少使用(LRU)的方式删除舊資料分區。如果您想手動删除RDD而不是等待它退出緩存,請使用
RDD.unpersist()
方法。
共享變量
通常,當在遠端叢集節點上執行傳遞給Spark操作(例如map或reduce)的函數時,它将在函數中使用的所有變量的單獨副本上工作。 這些變量将複制到每台機器,并且遠端機器上的變量的更新不會傳播回驅動程式。 對跨任務的通用的讀寫共享變量的支援是效率低下的。 但是,Spark确實為兩種常見的使用模式提供了兩種有限類型的共享變量:廣播變量和累加器。
廣播變量
廣播變量允許程式員在每台機器上保留一個隻讀變量,而不是随任務一起發送它的副本。 例如,它們可為每個節點以有效的方式提供一個海量輸入資料集的副本。 Spark還嘗試使用有效的廣播算法來分發廣播變量,以降低通信成本。
Spark動作由分布式“shuffle”操作分隔為一組stage執行。 Spark在每個階段中自動廣播任務所需的公共資料。 以這種方式廣播的資料以序列化形式緩存并在運作每個任務之前反序列化。 這意味着顯式建立廣播變量僅在跨多個階段的任務需要相同資料或以反序列化形式緩存資料很重要時才有用。
通過調用
SparkContext.broadcast(v)
從變量v建立廣播變量。 廣播變量是v的包裝器,可以通過調用value方法通路其值。 下面的代碼顯示了這個:
scala> val broadcastVar = sc.broadcast(Array(1, 2, 3))
broadcastVar: org.apache.spark.broadcast.Broadcast[Array[Int]] = Broadcast(0)
scala> broadcastVar.value
res0: Array[Int] = Array(1, 2, 3) 建立廣播變量後,應該在群集上運作的任何函數中使用它而不是值v,這樣v不會多次傳送到節點。 另外,在廣播之後不應修改對象v,以便確定所有節點獲得廣播變量的相同值(例如,如果稍後将變量發送到新節點)。
累加器
累加器是通過關聯和交換操作僅僅可以被“增加”的變量,是以可以有效地在并行中支援。 它們可用于實作計數器(如MapReduce)或求和。 Spark本身支援數值類型的累加器,程式員可以添加對新類型的支援。
作為使用者,您可以建立命名或未命名的累加器。 如下圖所示,命名累加器(在此執行個體計數器中)将顯示在Web UI中,用于修改該累加器的階段。 Spark在“任務”表中顯示任務修改的每個累加器的值。
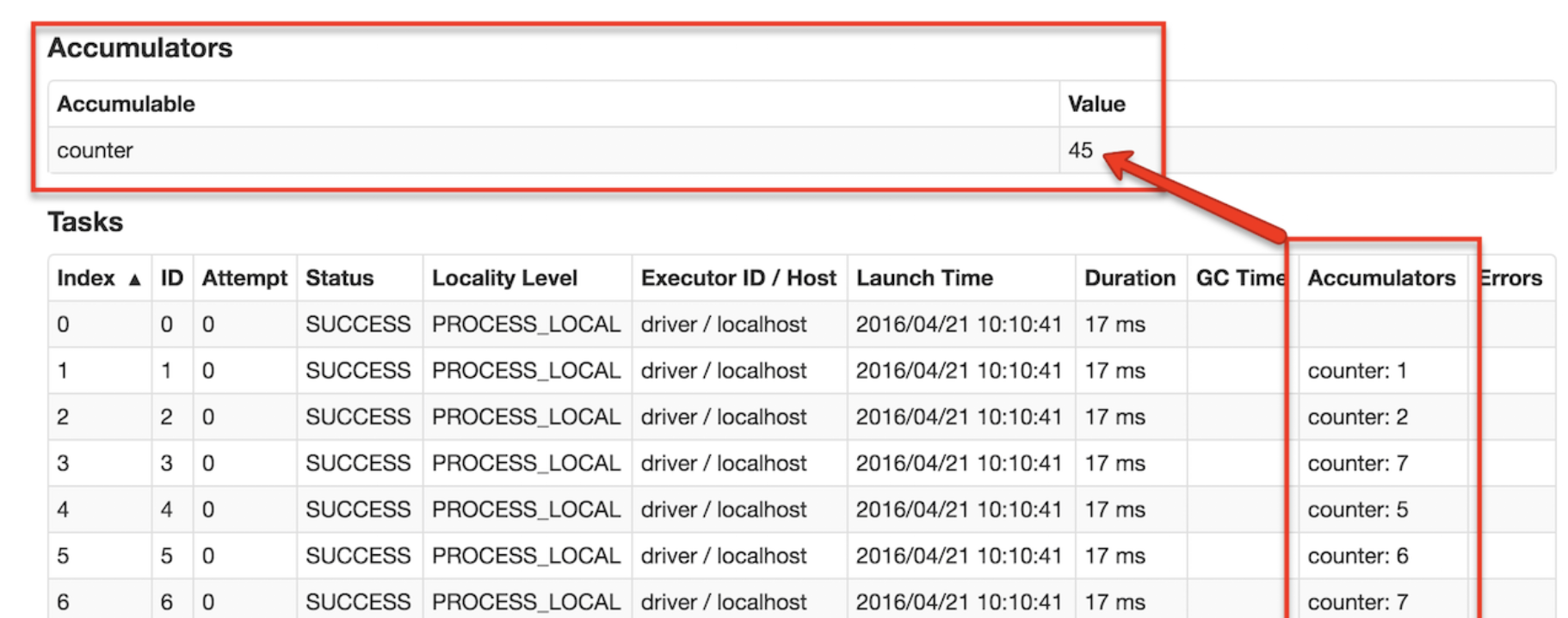
可以通過調用
SparkContext.longAccumulator()
或
SparkContext.doubleAccumulator()
來建立數字累加器,以分别累積Long或Double類型的值。 然後,可以使用add方法将在群集上運作的任務添加到其中。 但是,他們無法讀讀到它的值。隻有driver程式可以使用其value方法讀取累加器的值。
下面的代碼展示了使用累加器進行累加數組元素并擷取值的例子:
scala> val accum = sc.longAccumulator("My Accumulator")
accum: org.apache.spark.util.LongAccumulator = LongAccumulator(id: 0, name: Some(My Accumulator), value: 0)
scala> sc.parallelize(Array(1, 2, 3, 4)).foreach(x => accum.add(x))
...
10/09/29 18:41:08 INFO SparkContext: Tasks finished in 0.317106 s
scala> accum.value
res2: Long = 10 雖然此代碼使用了對Long類型累加器的内置支援,但程式員也可以通過繼承AccumulatorV2來建立自己的類型。 AccumulatorV2抽象類有幾個方法,必須覆寫:
reset
用于将累加器重置為零,
add
用于向累加器添加另一個值,
merge
用于合并另一個相同類型的累加器到這個。 其他必須覆寫的方法包含在API文檔中。例如,假設我們有一個表示數學向量的MyVector類,我們可以寫:
class VectorAccumulatorV2 extends AccumulatorV2[MyVector, MyVector] {
private val myVector: MyVector = MyVector.createZeroVector
def reset(): Unit = {
myVector.reset()
}
def add(v: MyVector): Unit = {
myVector.add(v)
}
...
}
// Then, create an Accumulator of this type:
val myVectorAcc = new VectorAccumulatorV2
// Then, register it into spark context:
sc.register(myVectorAcc, "MyVectorAcc1") 請注意,當程式員定義自己的AccumulatorV2類型時,結果類型可能與添加的元素類型不同。
對于僅在操作内執行的累加器更新,Spark保證每個任務對累加器的更新僅應用一次,即重新啟動的任務不會更新該值。 在轉換中,使用者應該知道,如果重新執行任務或作業階段,則可以多次執行每個任務的更新。
累加器不會改變Spark的延遲評估模型。 如果在RDD上的操作中更新它們,則隻有在RDD作為操作的一部分計算時才更新它們的值。 是以,在像
map()
這樣的惰性轉換中進行累加器更新時,不能保證執行累加器更新。 以下代碼片段示範了此屬性:
val accum = sc.longAccumulator
data.map { x => accum.add(x); x }
// Here, accum is still 0 because no actions have caused the map operation to be computed. ![Java String.format方法的簡單使用[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)