letter_recog.cpp的整體認識查閱RTrees、Boost、ANN_MLP、KNearest、NormalBayesClassifier、SVM,大寫英文字母識别,三目運算符的妙用(OpenCV案例源碼letter_recog.cpp解讀)
letter-recognition.data,20000*17,前16000行用于訓練,後4000行測試。
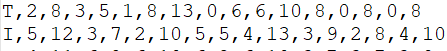
1、read_num_class_data()函數,把資料的第一列儲存到标簽集_responses,之後的16列儲存到特征集_data。
用到了兩個函數,說明如下:
fgets(str,n,fp);
從fp指向的檔案中擷取n-1個字元,并在最後加一個'\0'字元,共n個字元,放到字元數組str中。
如果在讀完n-1個字元之前就遇到了換行符或eof,讀入結束。
fgets函數傳回值為str的首位址。
float a;
int b;
sscanf(ptr, "%f%n", &a, ,&b);//ptr指向的内容中擷取浮點型格式的資料儲存到a中(%f的作用),此%n所在位置(在目前浮點型之後1位)之前的字元個數儲存到b中(%n的作用)
// 把既有标簽又有特征的集合,拆分為标簽集_responses、特征集_data,var_count是特征數(_data的列數)
static bool read_num_class_data(const string& filename, int var_count,Mat* _data, Mat* _responses)
{
const int M = 1024;//每行最多讀取1024個字元,超過filename中每行字元數即可
char buf[M + 2];//buf的第一個元素用于存放标簽,+2防止溢出
Mat el_ptr(1, var_count, CV_32F);//用于存放特征集
vector<int> responses;//用于存放标簽,push_back buf的第一個元素
_data->release(); //釋放該指向中所存儲的内容,不是銷毀
_responses->release();
FILE* f = fopen(filename.c_str(), "rt");//r隻讀,t文本檔案(可省略,預設t)
if (!f)
{
cout << "Could not read the database " << filename << endl;
return false;
}
for (;;)
{
char* ptr;
if (!fgets(buf, M, f) )//此處每次讀一行,因為每行不夠1024個字元,遇到換行符停止讀取。
break;//直到最後一行
responses.push_back((int)buf[0]);//每行第1個元素放入responses中(标簽)
ptr = buf + 2;//ptr指向第一個逗号之後的資料,即第一個樣本的第一個特征值
for (int i = 0; i < var_count; i++)//周遊一行中的每個元素
{
int n = 0;
sscanf(ptr, "%f%n", &el_ptr.at<float>(i), &n);//把一行中的浮點數存放到el_ptr一維行向量中
ptr += n + 1;//跳過逗号
}
_data->push_back(el_ptr);//存到特征集_data,_data指向一片Mat空間
}
fclose(f);
Mat(responses).copyTo(*_responses);//儲存到_responses指向的Mat空間
cout << "The database " << filename << " is loaded.\n";
return true;
} 2、prepare_train_data()函數,從特征集data中選取前80%行,所有列作為訓練集。下文中有int ntrain_samples = (int)(nsamples_all*0.8);
//特征集data中選取前80%行,所有列作為訓練集。下文中有int ntrain_samples = (int)(nsamples_all*0.8);
static Ptr<TrainData> prepare_train_data(const Mat& data, const Mat& responses, int ntrain_samples)
{
Mat sample_idx = Mat::zeros(1, data.rows, CV_8U);
Mat train_samples = sample_idx.colRange(0, ntrain_samples);//80%的樣本
train_samples.setTo(Scalar::all(1));//操作train_samples就是操作sample_idx,淺拷貝。sample_idx中前80%變為1
return TrainData::create(data, ROW_SAMPLE, responses,noArray(), sample_idx);//所有特征(列)參與訓練,前80%樣本(行)參與訓練
} 3、訓練終止條件
inline TermCriteria TC(int iters, double eps)
{
return TermCriteria(TermCriteria::MAX_ITER + (eps > 0 ? TermCriteria::EPS : 0), iters, eps);
} 4、test_and_save_classifier()函數,測試并儲存分類模型,算出訓練、測試的準确率
static void test_and_save_classifier(const Ptr<StatModel>& model,const Mat& data, const Mat& responses,int ntrain_samples, int rdelta,const string& filename_to_save)
{
int i, nsamples_all = data.rows;
double train_hr = 0, test_hr = 0;
for (i = 0; i < nsamples_all; i++)
{
Mat sample = data.row(i);
float r = model->predict(sample);//所有樣本,逐行預測,傳回預測結果,65~90
//除MLP,其他算法rdelta=0,預測結果r-對應标簽responses如果為0則預測正确,下方的統計數+1
r = std::abs(r + rdelta - responses.at<int>(i)) <= FLT_EPSILON ? 1.f : 0.f;//FLT_EPSILON非常小的正數
if (i < ntrain_samples)//ntrain_samples是0.8*總樣本,即80%用于訓練
train_hr += r;//統計訓練正确的個數
else
test_hr += r;//統計測試正确的個數
}
//計算準确率
test_hr /= nsamples_all - ntrain_samples;
train_hr = ntrain_samples > 0 ? train_hr / ntrain_samples : 1.;//保證分母不為0
printf("Recognition rate: train = %.1f%%, test = %.1f%%\n", train_hr*100., test_hr*100.);
//儲存模型,xml格式
if (!filename_to_save.empty())
{
model->save(filename_to_save);
}
} 5、load_classifier()函數,模闆類,提示資訊,xml模型檔案載入是否成功
template<typename T>
static Ptr<T> load_classifier(const string& filename_to_load)
{
// load classifier from the specified file
Ptr<T> model = StatModel::load<T>(filename_to_load);
if (model.empty())
cout << "Could not read the classifier " << filename_to_load << endl;
else
cout << "The classifier " << filename_to_load << " is loaded.\n";
return model;
} #include<opencv2\opencv.hpp>
#include <iostream>
using namespace std;
using namespace cv;
using namespace cv::ml;
// 把既有标簽又有特征的集合,拆分為标簽集_responses、特征集_data,var_count是特征數(_data的列數)
static bool read_num_class_data(const string& filename, int var_count, Mat* _data, Mat* _responses)
{
const int M = 1024;//每行最多讀取1024個字元,超過filename中每行字元數即可
char buf[M + 2];//buf的第一個元素用于存放标簽,+2防止溢出
Mat el_ptr(1, var_count, CV_32F);//用于存放特征集
vector<int> responses;//用于存放标簽,push_back buf的第一個元素
_data->release(); //釋放該指向中所存儲的内容,不是銷毀
_responses->release();
FILE* f = fopen(filename.c_str(), "rt");//r隻讀,t文本檔案(可省略,預設t)
if (!f)
{
cout << "Could not read the database " << filename << endl;
return false;
}
for (;;)
{
char* ptr;
if (!fgets(buf, M, f))//此處每次讀一行,因為每行不夠1024個字元,遇到換行符停止讀取。
break;//直到最後一行
responses.push_back((int)buf[0]);//每行第1個元素放入responses中(标簽)
ptr = buf + 2;//ptr指向第一個逗号之後的資料,即第一個樣本的第一個特征值
for (int i = 0; i < var_count; i++)//周遊一行中的每個元素
{
int n = 0;
sscanf(ptr, "%f%n", &el_ptr.at<float>(i), &n);//把一行中的浮點數存放到el_ptr一維行向量中
ptr += n + 1;//跳過逗号
}
_data->push_back(el_ptr);//存到特征集_data,_data指向一片Mat空間
}
fclose(f);
Mat(responses).copyTo(*_responses);//儲存到_responses指向的Mat空間
cout << "The database " << filename << " is loaded.\n";
return true;
}
//特征集data中選取前80%行,所有列作為訓練集。下文中有int ntrain_samples = (int)(nsamples_all*0.8);
static Ptr<TrainData> prepare_train_data(const Mat& data, const Mat& responses, int ntrain_samples)
{
Mat sample_idx = Mat::zeros(1, data.rows, CV_8U);
Mat train_samples = sample_idx.colRange(0, ntrain_samples);//80%的樣本
train_samples.setTo(Scalar::all(1));//操作train_samples就是操作sample_idx,淺拷貝。sample_idx中前80%變為1
return TrainData::create(data, ROW_SAMPLE, responses, noArray(), sample_idx);//所有特征(列)參與訓練,前80%樣本(行)參與訓練
}
inline TermCriteria TC(int iters, double eps)
{
return TermCriteria(TermCriteria::MAX_ITER + (eps > 0 ? TermCriteria::EPS : 0), iters, eps);
}
//測試并儲存分類模型,算出訓練、測試的準确率
static void test_and_save_classifier(const Ptr<StatModel>& model, const Mat& data, const Mat& responses, int ntrain_samples, int rdelta, const string& filename_to_save)
{
int i, nsamples_all = data.rows;
double train_hr = 0, test_hr = 0;
for (i = 0; i < nsamples_all; i++)
{
Mat sample = data.row(i);
float r = model->predict(sample);//所有樣本,逐行預測,傳回預測結果,65~90
//除MLP,其他算法rdelta=0,預測結果r-對應标簽responses如果為0則預測正确,下方的統計數+1
r = std::abs(r + rdelta - responses.at<int>(i)) <= FLT_EPSILON ? 1.f : 0.f;//FLT_EPSILON非常小的正數
if (i < ntrain_samples)//ntrain_samples是0.8*總樣本,即80%用于訓練
train_hr += r;//統計訓練正确的個數
else
test_hr += r;//統計測試正确的個數
}
//計算準确率
test_hr /= nsamples_all - ntrain_samples;
train_hr = ntrain_samples > 0 ? train_hr / ntrain_samples : 1.;//保證分母不為0
printf("Recognition rate: train = %.1f%%, test = %.1f%%\n", train_hr*100., test_hr*100.);
//儲存模型,xml格式
if (!filename_to_save.empty())
{
model->save(filename_to_save);
}
}
//模闆類,提示資訊,xml模型檔案載入是否成功
template<typename T>
static Ptr<T> load_classifier(const string& filename_to_load)
{
// load classifier from the specified file
Ptr<T> model = StatModel::load<T>(filename_to_load);
if (model.empty())
cout << "Could not read the classifier " << filename_to_load << endl;
else
cout << "The classifier " << filename_to_load << " is loaded.\n";
return model;
}
//************************************以下為具體的模型***************************************************************//
static bool build_rtrees_classifier(const string& data_filename, const string& filename_to_save, const string& filename_to_load)
{
Mat data;
Mat responses;
bool ok = read_num_class_data(data_filename, 16, &data, &responses);//拆分總集為特征集(16個特征)、标簽集
if (!ok)
return ok;
Ptr<RTrees> model;
int nsamples_all = data.rows;
int ntrain_samples = (int)(nsamples_all*0.8);
// Create or load Random Trees classifier
if (!filename_to_load.empty())
{
model = load_classifier<RTrees>(filename_to_load);
if (model.empty())
return false;
ntrain_samples = 0;
}
else
{
// create classifier by using <data> and <responses>
cout << "Training the classifier ...\n";
// Params( int maxDepth, int minSampleCount,
// double regressionAccuracy, bool useSurrogates,
// int maxCategories, const Mat& priors,
// bool calcVarImportance, int nactiveVars,
// TermCriteria termCrit );
Ptr<TrainData> tdata = prepare_train_data(data, responses, ntrain_samples);
model = RTrees::create();
model->setMaxDepth(10);
model->setMinSampleCount(10);
model->setRegressionAccuracy(0);
model->setUseSurrogates(false);
model->setMaxCategories(15);
model->setPriors(Mat());
model->setCalculateVarImportance(true);
model->setActiveVarCount(4);
model->setTermCriteria(TC(100, 0.01f));
model->train(tdata);
cout << endl;
}
test_and_save_classifier(model, data, responses, ntrain_samples, 0, filename_to_save);
cout << "Number of trees: " << model->getRoots().size() << endl;//樹的個數
//輸出每個特征的重要性,越大表明此特征越重要
Mat var_importance = model->getVarImportance();
cout << var_importance << endl;
return true;
}
static bool build_boost_classifier(const string& data_filename, const string& filename_to_save, const string& filename_to_load)
{
const int class_count = 26;
Mat data;
Mat responses;
Mat weak_responses;
bool ok = read_num_class_data(data_filename, 16, &data, &responses);
if (!ok)
return ok;
int i, j, k;
Ptr<Boost> model;
int nsamples_all = data.rows;
int ntrain_samples = (int)(nsamples_all*0.5);
int var_count = data.cols;
// Create or load Boosted Tree classifier
if (!filename_to_load.empty())
{
model = load_classifier<Boost>(filename_to_load);
if (model.empty())
return false;
ntrain_samples = 0;
}
else
{
// !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
//
// As currently boosted tree classifier in MLL can only be trained
// for 2-class problems, we transform the training database by
// "unrolling" each training sample as many times as the number of
// classes (26) that we have.
//
// !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
Mat new_data(ntrain_samples*class_count, var_count + 1, CV_32F);
Mat new_responses(ntrain_samples*class_count, 1, CV_32S);
// 1. unroll the database type mask
printf("Unrolling the database...\n");
for (i = 0; i < ntrain_samples; i++)
{
const float* data_row = data.ptr<float>(i);
for (j = 0; j < class_count; j++)
{
float* new_data_row = (float*)new_data.ptr<float>(i*class_count + j);
memcpy(new_data_row, data_row, var_count*sizeof(data_row[0]));
new_data_row[var_count] = (float)j;
new_responses.at<int>(i*class_count + j) = responses.at<int>(i) == j + 'A';
}
}
Mat var_type(1, var_count + 2, CV_8U);
var_type.setTo(Scalar::all(VAR_ORDERED));
var_type.at<uchar>(var_count) = var_type.at<uchar>(var_count + 1) = VAR_CATEGORICAL;
Ptr<TrainData> tdata = TrainData::create(new_data, ROW_SAMPLE, new_responses,
noArray(), noArray(), noArray(), var_type);
vector<double> priors(2);
priors[0] = 1;
priors[1] = 26;
cout << "Training the classifier (may take a few minutes)...\n";
model = Boost::create();
model->setBoostType(Boost::GENTLE);
model->setWeakCount(100);
model->setWeightTrimRate(0.95);
model->setMaxDepth(5);
model->setUseSurrogates(false);
model->setPriors(Mat(priors));
model->train(tdata);
cout << endl;
}
Mat temp_sample(1, var_count + 1, CV_32F);
float* tptr = temp_sample.ptr<float>();
// compute prediction error on train and test data
double train_hr = 0, test_hr = 0;
for (i = 0; i < nsamples_all; i++)
{
int best_class = 0;
double max_sum = -DBL_MAX;
const float* ptr = data.ptr<float>(i);
for (k = 0; k < var_count; k++)
tptr[k] = ptr[k];
for (j = 0; j < class_count; j++)
{
tptr[var_count] = (float)j;
float s = model->predict(temp_sample, noArray(), StatModel::RAW_OUTPUT);
if (max_sum < s)
{
max_sum = s;
best_class = j + 'A';
}
}
double r = std::abs(best_class - responses.at<int>(i)) < FLT_EPSILON ? 1 : 0;
if (i < ntrain_samples)
train_hr += r;
else
test_hr += r;
}
test_hr /= nsamples_all - ntrain_samples;
train_hr = ntrain_samples > 0 ? train_hr / ntrain_samples : 1.;
printf("Recognition rate: train = %.1f%%, test = %.1f%%\n", train_hr*100., test_hr*100.);
cout << "Number of trees: " << model->getRoots().size() << endl;
// Save classifier to file if needed
if (!filename_to_save.empty())
model->save(filename_to_save);
return true;
}
static bool build_mlp_classifier(const string& data_filename, const string& filename_to_save, const string& filename_to_load)
{
const int class_count = 26;
Mat data;
Mat responses;
bool ok = read_num_class_data(data_filename, 16, &data, &responses);
if (!ok)
return ok;
Ptr<ANN_MLP> model;
int nsamples_all = data.rows;
//int ntrain_samples = (int)(nsamples_all*0.8);
int ntrain_samples = (int)(nsamples_all*0.01);
// Create or load MLP classifier
if (!filename_to_load.empty())
{
model = load_classifier<ANN_MLP>(filename_to_load);
if (model.empty())
return false;
ntrain_samples = 0;
}
else
{
// !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
//
// MLP does not support categorical variables by explicitly.
// So, instead of the output class label, we will use
// a binary vector of <class_count> components for training and,
// therefore, MLP will give us a vector of "probabilities" at the
// prediction stage
//
// !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
Mat train_data = data.rowRange(0, ntrain_samples);
Mat train_responses = Mat::zeros(ntrain_samples, class_count, CV_32F);
// 1. unroll the responses
cout << "Unrolling the responses...\n";
for (int i = 0; i < ntrain_samples; i++)
{
int cls_label = responses.at<int>(i) -'A';//大寫英文字母用0~25辨別
train_responses.at<float>(i, cls_label) = 1.f;
}
// 2. train classifier
int layer_sz[] = { data.cols, 100, 100, class_count };
int nlayers = (int)(sizeof(layer_sz) / sizeof(layer_sz[0]));
Mat layer_sizes(1, nlayers, CV_32S, layer_sz);
#if 1
int method = ANN_MLP::BACKPROP;
double method_param = 0.001;
int max_iter = 300;
#else
int method = ANN_MLP::RPROP;
double method_param = 0.1;
int max_iter = 1000;
#endif
Ptr<TrainData> tdata = TrainData::create(train_data, ROW_SAMPLE, train_responses);
cout << "Training the classifier (may take a few minutes)...\n";
model = ANN_MLP::create();
model->setLayerSizes(layer_sizes);
model->setActivationFunction(ANN_MLP::SIGMOID_SYM, 0, 0);
model->setTermCriteria(TC(max_iter, 0));
model->setTrainMethod(method, method_param);
model->train(tdata);
cout << endl;
}
//test_and_save_classifier(model, data, responses, ntrain_samples, 'A', filename_to_save);
test_and_save_classifier(model, data, responses, ntrain_samples, 'A', "save.xml");
return true;
}
static bool build_knearest_classifier(const string& data_filename, int K)
{
Mat data;
Mat responses;
bool ok = read_num_class_data(data_filename, 16, &data, &responses);
if (!ok)
return ok;
int nsamples_all = data.rows;
int ntrain_samples = (int)(nsamples_all*0.8);
// create classifier by using <data> and <responses>
cout << "Training the classifier ...\n";
Ptr<TrainData> tdata = prepare_train_data(data, responses, ntrain_samples);
Ptr<KNearest> model = KNearest::create();
model->setDefaultK(K);
model->setIsClassifier(true);
model->train(tdata);
cout << endl;
test_and_save_classifier(model, data, responses, ntrain_samples, 0, string());
return true;
}
static bool build_nbayes_classifier(const string& data_filename)
{
Mat data;
Mat responses;
bool ok = read_num_class_data(data_filename, 16, &data, &responses);
if (!ok)
return ok;
Ptr<NormalBayesClassifier> model;
int nsamples_all = data.rows;
int ntrain_samples = (int)(nsamples_all*0.8);
// create classifier by using <data> and <responses>
cout << "Training the classifier ...\n";
Ptr<TrainData> tdata = prepare_train_data(data, responses, ntrain_samples);
model = NormalBayesClassifier::create();
model->train(tdata);
cout << endl;
test_and_save_classifier(model, data, responses, ntrain_samples, 0, string());
return true;
}
static bool build_svm_classifier(const string& data_filename, const string& filename_to_save, const string& filename_to_load)
{
Mat data;
Mat responses;
bool ok = read_num_class_data(data_filename, 16, &data, &responses);
if (!ok)
return ok;
Ptr<SVM> model;
int nsamples_all = data.rows;
int ntrain_samples = (int)(nsamples_all*0.8);
// Create or load Random Trees classifier
if (!filename_to_load.empty())
{
model = load_classifier<SVM>(filename_to_load);
if (model.empty())
return false;
ntrain_samples = 0;
}
else
{
// create classifier by using <data> and <responses>
cout << "Training the classifier ...\n";
Ptr<TrainData> tdata = prepare_train_data(data, responses, ntrain_samples);
model = SVM::create();
model->setType(SVM::C_SVC);
model->setKernel(SVM::LINEAR);
model->setC(1);
model->train(tdata);
cout << endl;
}
test_and_save_classifier(model, data, responses, ntrain_samples, 0, filename_to_save);
return true;
}
int main(int argc, char *argv[])
{
string filename_to_save = "";
string filename_to_load = "";
string data_filename;
string method = "rtrees";
data_filename = "letter-recognition.data";//資料集
filename_to_save = "model.xml";//儲存模型
//filename_to_load = "model.xml";//載入已有模型
//三目運算符,替代if……else if嵌套
if ((method == "rtrees" ? build_rtrees_classifier(data_filename, filename_to_save, filename_to_load) :
method == "boost" ? build_boost_classifier(data_filename, filename_to_save, filename_to_load) :
method == "mlp" ? build_mlp_classifier(data_filename, filename_to_save, filename_to_load) :
method == "knearest" ? build_knearest_classifier(data_filename, 10) :
method == "nbayes" ? build_nbayes_classifier(data_filename) :
method == "svm" ? build_svm_classifier(data_filename, filename_to_save, filename_to_load) :
-1) < 0)
return 0;
} ![HDU 6232 Confliction[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)