https://dev.mysql.com/doc/refman/8.0/en/group-replication-technical-details.html
這一章主要描述MGR的更多細節
18.10.1 Group Replication Plugin Architecture
MGR是一個MySQL插件,它是建構在MySQL複制架構上的,是以就擁有了它的很多優秀的特性
比如: binog、row-based、GTID等
它也整合了現在MySQL的一些元件如:performance schema 、plugin、service的架構
下面一張圖可以很好的展示MGR的整體結構和架構
- Figure 18.9 Group Replication Plugin Block Diagram
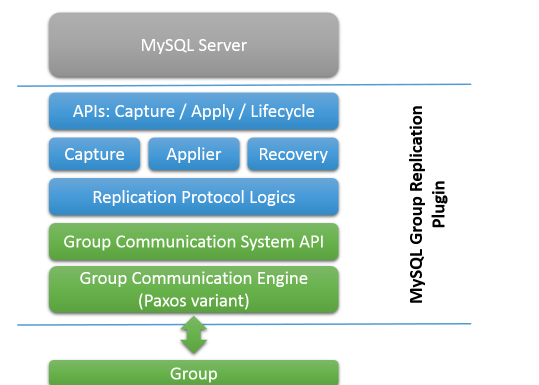
MGR包括了一系列的API如:capture, apply, and lifecycle,這些東西控制這個plugin如何與MySQL server進行協助
這些接密碼資訊從server到plugin進行流動這,反之亦然
這些接口将MySQL Server和Group進行了隔離
在某一方面,從server到pugin,有一些事件通知資訊如:server的開啟、server的恢複、server接收請求連接配接、送出事務等
在另一方面,plugin通知server完成相關動作,如:commit事務,或拒絕即将來臨的事務,讓事務排隊等
下面一層,又是一些MGR元件
capture元件 負責 執行并與相關的事務持續保持聯系
applier元件 負責 執行遠端接收的事務
recovery元件 負責 管理分布式恢複,以及管理成員的加入、新成員的日志同步,處理相關donor失敗等情況
繼續往下,replication protocol子產品,包含了具體的邏輯複制協定
他負責處理組複制的事務沖突、競争
最後2層是:Group Communication System (GCS) API 和 communication engine (XCom)【基于Paxos的實作】
Group Communication System (GCS) API 高層的API,負責抽象複制狀态機所需要的屬性
communication engine(XCom)主要處理組成員之間的協作和交流
18.10.2 The Group
在MGR中,一堆servers組成了複制group
一個由UUID組成的名字的group
這個group是動态的,且servers可在任何時間自由(不管是主動,還是被動)加入和離開
如果一個server加入了一個group,他會自動的從donar中catch沒有的事務,這其實就是異步複制機制
如果一個server離開了group,剩下的server會意識到它的離開,并自動重新更新配置
18.10.3 Data Manipulation Statements
任何事務都可以自由執行事務不用協調,但是在commit的時候,需要其他server一起協調來做決定這個事務的命運
這種協調有兩種目的:
1)檢測這個事務是應該commit,還是不應該commit
2)傳遞這個changes,以至于其他的servers可以很好的應用它
由于事務是通過原子廣播的形式來傳遞,是以要麼所有server都能接收到,要麼全部都接收不到
如果他們接收到了原子廣播資訊: 那麼他們都将以同樣的順序接收到
由于沖突檢測需要比對事務寫集,是以他們是在row-level層面上進行檢測
沖突檢測的解決方案是:誰第一個送出,誰獲勝的方式(first committer wins rule)
假設:t1和t2同時送出,那麼總有一個在前面,如果t1在前,t2在後,那麼t1就會赢得送出權,t2就會被拒絕或rollback
18.10.4 Data Definition Statements
在MGR中,DDL是需要大家關注的
雖然8.0介紹說已經支援原子DDL,就是完全的DDL語句作為一個原子事務一樣,要麼送出,要麼rollback
但是,DDL語句,原子的,非原子的,都會隐式送出目前session的任何活躍事務
也就是說:DDL無法跟其他事務組合使用
MGR是基于樂觀複制的模式,也就是先執行,如有必要在rollback的模式
在multi-primary模式下,DDL和DML作用在同一個對象上,會造成資料不一緻的情況,是以需要引起大家足夠的關心
如果是single-primary,這種問題就不會發生,因為所有事務更新都在同一個server完成,那就是primary
18.10.5 Distributed Recovery
當一個成員加入group,需要追上現有成員的事務日志,這個過程叫做Distributed Recovery
這一節,主要描述Distributed Recovery
18.10.5.1 Distributed Recovery Basics
Distributed Recovery的基礎是:異步複制
主要分2階段:
phase1: 一個server要加入一個group,首先會選擇一個成員作為donar,它主要提供新成員所需要的所有事務日志
除此之外,它還會cache住這個group的其他exchange事務
一旦從donar的複制結束,對于donar的異步複制通道就會關閉 ,然後這個server 開啟第二個步驟,catch up
phase2:這個階段,它會執行之前cache住的exchange,直到這個queue的隊列為0,最後宣布這個成員為 online
在恢複過程中,如果在phase1的時候,遇到donar server的錯誤,那麼就會換一個server作為donar開始同步資料
如果phase1 donar結束connection的階段有問題,那麼直接開啟一個新的connection指向新的donar即可,這都是自動的
18.10.5.2 Recovering From a Point-in-time
GTID可以提供哪些日志需要恢複,server已經處理哪些事務,但是它沒辦法做到标記一個具體的point(組成員進行catch up),也沒辦法傳送certification資訊
這是binlog view marker做的事情,它可以在binlog stream中标記一個view,也可以打上額外的中繼資料資訊标記(缺失的certification資訊)
18.10.5.3 View Changes
這一節主要描述 view change identifier内部是如何在binary log 事件中協調工作的
- Begin: Stable Group
所有的成員都是online,且正在處理即将要來的事務
有些成員可能落後,但是最後都會追上

- View Change: a Member Joins
當一個新的成員需要加入時,這個view就change了,每一個server都在queue一個view change
同時,S4 選擇需要在online清單中選擇一個server作為donar
每一個online server 都講view change事 寫入到了 binlog
- State Transfer: Catching Up
一旦這個server選擇了s2作為donar,那麼就會建立一個異步複制通道(之前說過的phase1)來同步資料,直到之前的view change 事件(VC4)
換句話說就是:新成員從donar(s2)中複制資料,直到view change 事件結束(vc4)
當server正從donar中同步資料的同時,它也會cache住從group傳來的事務(temporary Applier Buffer)。
一旦從donar同步結束,就會切換,選擇來應用之前cache的事務
- Finish: Caught Up
在 catch up (phase 2) 階段中,一旦cached事務隊列數量變成0,他就會變成online,正式成為其中一員
18.10.5.4 Usage Advice and Limitations of Distributed Recovery
分布式恢複也有一些限制。
由于phase1階段需要同步大量資料,是以推薦做法是,在加入group的server,應該要選擇一個合适的Snapchat或備份(rencent),這樣會減少catch-up的phase1的時間
18.10.6 Observability
由于MGR内部很多機制都是自動的,是以你需要了解其中的原理和場景。
這樣看來,Performance Schema是非常重要的,因為他可以監控和查詢相關的MGR場景和狀态
18.10.7 Group Replication Performance
這一節主要描述怎麼樣配置才能讓MGR達到最好的性能
18.10.7.1 Fine Tuning the Group Communication Thread
當MGR插件load的時候, group communication thread (GCT)就在循環跑起來了
如果想要強制讓GCT來等待,可以使用 group_replication_poll_spin_loops
mysql> SET GLOBAL group_replication_poll_spin_loops= 10000;
18.10.7.2 Message Compression
當網絡帶寬是瓶頸的時候,消息壓縮可能提升30-40%的吞吐
預設情況下,壓縮是開啟的
預設是LZ4,門檻值是:1000000 bytes
如果設定門檻值:
STOP GROUP_REPLICATION;
SET GLOBAL group_replication_compression_threshold= 2097152;
START GROUP_REPLICATION;
以上設定的是2MB,意味着,如果事務産生了2MB的消息,它就會壓縮。
取消壓縮,設定為group_replication_compression_threshold=0
18.10.7.3 Flow Control
大部分成員确認接收到事務,且同意所有事務的順序後,MGR才能確定事務commit
如果所有的寫事務沒有超過這個group任何成員的壓力承受極限的時候,一切都運作的很好
一旦有部分成員承受不了極限,那麼他們就可能落後其他成員
當部分成員落後的時候,就很有可能産生一緻性問題,尤其是部分讀可能讀到的是落後的資料
為了解決這種問題,有一種複制協定機制,他就是流控
流控的隊列有兩個:1)certification queue 2)binlog applier queue.
兩大機制:1)monitor機制 2)Throttling機制
18.10.7.3.1 探針和統計
監控機制是建立在group中設定探針,并定期收集資料,階段性上報資訊,來一起分享這些探針資料
探針資料如下:
- certifier queue 大小
- replication applier queue 大小
- 總認證事務的大小
- 總遠端執行事務的大小(一個member)
- 總本地事務的大小
18.10.7.3.2 MGR Throttling
一旦達到1)certification queue 2)binlog applier queue.的上限,那麼Throttling機制就開啟