閱讀須知:筆記為閱讀《TCP IP 詳解卷1:協定》後摘抄的一些知識點,其間也有加入一些根據英文原版的自己翻譯和結合網上知識後的了解,是以有些段落之間并不能夠串聯上或者知識點與書上略有差别(基本差别不大,參考的資料屬 RFC官方文檔
)。
第五章:Internet 協定
IP是TCP/IP協定族中的核心協定,TCP、UDP、ICMP、IGMP資料都通過IP資料報傳輸。IP提供了一種"盡力而為、無連接配接"的資料傳遞服務:盡力而為表示不保證IP資料報能成功到達目的地;無連接配接意味着IP不維護網絡單元中資料報相關的任何連結狀态資訊,每個資料報獨立于其他資料報來處理,這也意味着IP資料報的可不按順序傳遞。
IPv4頭部
如下是IPv4的資料報結構圖:
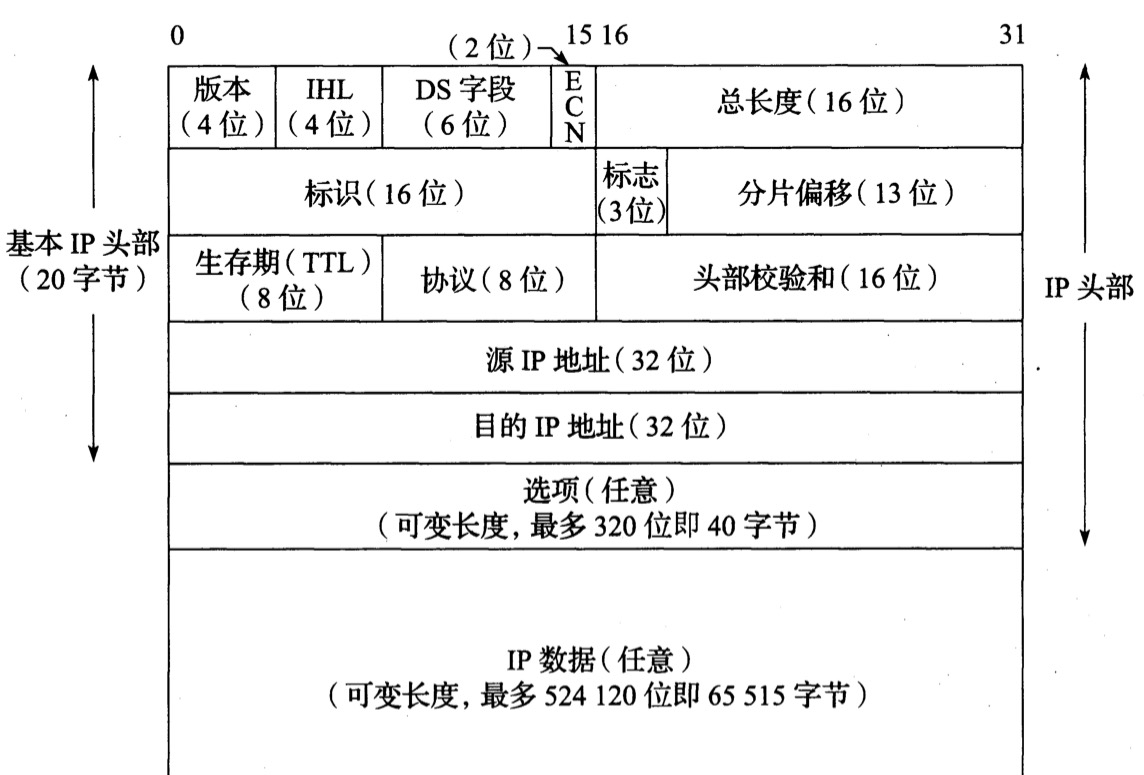
這裡主要關注IPv4的頭部資訊,一個典型的IPv4基本頭部(指不包括IP選項)包含20位元組。包含:
1. 版本辨別(IPv4為4,IPv6為6);
2. IHL(Internet頭部長度);
3. DC字段(服務類型字段),指定一個等效的通信類型字段,前6位是區分服務字段,後2位(ECN)是顯式擁塞通知字段或訓示位;
4. 總長度,IPv4資料報的總長度,由于它是一個16位字段,是以可以算出IPv4資料報的最大長度是65535位元組(理想化的最大,實際通信由多方因素計算後取最小值);
5. 辨別字段,幫助辨別由IPv4主機發送的資料報,避免資料報分片混淆;标志是一個3位的控制字段,表示是否允許資料分片、該資料報是否是末尾的資料報;分片偏移字段給出該分片負載位元組中的第一個位元組在原始IPv4資料中的偏移量;
6. TTL(生存期)用于設定一個資料報可經過的路由器數量上限,每經過一台路由器,該值減1,直至0,用于防止由于出現路由環路而導緻的資料報循環;
7. 協定字段表示資料報有效載荷部分的資料類型,最常用值為17(UDP)和6(TCP);
8. 頭部校驗和字段僅計算IPv4頭部,不檢查資料報有效載荷的正确性;
9. 源IP位址和目标IP位址,資料通信的兩端位址。
IPv4支援一些可供資料報選擇的選項,填充在選項字段,選項有一個8位的類型字段辨別:複制(1位)、類别(2位)、編号(5位)。
IPv4選項如下表:

IPv6頭部
如下是IPv6的頭部資訊圖:
相對于IPv4頭部,少了一些資訊,也多了一些資訊,多了的資訊包括:
1. 流标簽以辨別同一個流裡面的封包;
2. 負載長度(對比辨別字段)字段提供IPv6資料報的長度,不包括頭部長度,但包括IPv6擴充頭部;、
3. 下一個頭部字段用來指明報頭後接的封包頭部的類型,若存在擴充頭,表示第一個擴充頭的類型,否則表示其上層協定的類型,它是IPv6各種功能的核心實作方法;
4. 跳數限制(對比IPv4的TTL)
IPv6擴充頭部
擴充頭部和更高協定頭部與IPv6頭部連結起來構成級聯的頭部,每個頭部的下一個頭部字段辨別緊跟着的頭部類型,類型值有:
IPv6選項
由于IPv4頭部空間的限制,那些來自IPv4的選項已停止使用,而IPv6可變長度的擴充頭部或編碼在特殊擴充頭部中的選項可适應目前更大的Internet。如果選項存在,可放入逐跳選項或目的地選項。
1. 填充1和填充N:填充1選項(類型0)是唯一缺少長度字段和值字段的選項。它僅有1位元組長,取值為0。填充N選項(類型1)向頭部的選項區域填充2位元組或更多位元組,對于n個填充位元組,選項資料長度字段包含的值為(n-2)。
2. IPv6超大有效載荷:IPv6超大有效載荷選項指定了一種有效載荷大于65535位元組的IPv6資料報,稱為超大封包。超大有效載荷選項提供了一個32位的字段,用于攜帶有效載荷在65535~4294967295位元組直接的資料報,當使用超大封包時,正常的敷在長度字段被設定位0。
3. 隧道封裝限制:路由器想要将IPv6資料封裝在一條隧道中,它首先檢查隧道封裝限制選項是否存在并置位,如果不為0,則可進行隧道封裝,且新封裝的IPv6資料報必須包括這個選項,其值相對之前的封裝限制值減1,依次封裝遞減。
4. 路由器警告:與IPv4的該選項一樣,指出包含需要路由器處理的資訊。
5. 快速啟動:适用于IPv4和IPv6,但目前建議僅用于專用網絡。選項包括發送者需要的以比特/秒為機關的傳輸速率的編碼值、QS TTL值和一些額外資訊。
6. CALIPSO:于在某些專用網絡中支援通用體系結構标簽IPv6安全選項。它提供了一種為資料報做标記的方法,包括一個安全級别辨別符和一些額外的資訊。
7. 家鄉位址:當使用IPV6移動選項時,這個選項儲存發送資料報的IPv6節點的"家鄉"位址。當遠離"家鄉"(典型位置的位址字首)漫遊時,通常為該節點配置設定一個不同的IP位址。該選項允許這個節點提供自已正常的家鄉位址,以及它在漫遊時的新位址(通常是臨時配置設定)。當其他IPv6節點需要與移動節點通信時,它可以使用該節點的家鄉位址。如果家鄉位址選項存在,包含它的目的地選項頭部必須出現在路由頭部之後,并在分片和ESP頭部之前。
"家鄉"的概念來自典型位置的位址字首,其設計目的是為了讓移動裝置使用者,能夠從一個網上系統中,移動到另一個網上系統,但是裝置的IP位址保持不變。這能夠使移動節點在移動中保持其連接配接性,實作跨越不同網段的漫遊功能。
Internet校驗和
Intenret校驗和是一個被校驗資料(如果被計算的位元組數為奇數,用0填充)的16位反碼和的反碼,它能以相當高的機率确定接收的消息或其中的部内容是否與發送的相比對。如果被計算資料包括一個校驗和字段,該字段在進行校驗和運算之前被設定為0,然後将計算出的校驗和填充到該字段。為了檢查一個包含校驗和字段(頭部、有效載荷等)的資料輸入是否有效,需要對整個資料塊(包括校驗和字段)同樣計算校驗和。由于校驗和字段本質上是其餘資料校驗和的反碼,對正确接收的資料計算校驗和應産生一個值0。
發送的行為:
為了給輸出的資料報計算IPv4頭部校驗和,首先将資料報的校驗和字段值設定為0。然後,對頭部(整個頭部被認為是一個16位字的序列)計算16位二進制反碼和。這個16位二進制反碼和被存儲在校驗和字段中。二進制反碼加法可通過“循環進位加法”實作:當使用傳統(二進制補碼)加法産生一個進位時,這個進位以二進制值1加在高位。
接收的行為:
當一個IPv4資料報被接收時,對整個頭部計算出一個校驗和,包括校驗和字段自身的值。假設資料報沒有錯誤,計算出的校驗和值為0(值FFFF的反碼)。對于任何不正常的分組或頭部,分組中的校驗和字段值不為FFFF。
案例:
# 發送
消息: E3 4F 23 96 44 27 99 F3 [00 00] ← 校驗和字段 = 0000
二進制補碼和: 1E4FF
二進制反碼和: E4FF + 1 = E500
二進制反碼: ~(E500)=~(1110 0101 0000 0000) = 0001 1010 1111 1111 = 1AFF (校驗和)
# 接收
消息 + 校驗和 = E34F + 2396 + 4427 + 99F3 + 1AFF = E500 + 1AFF = FFFF
~(消息 + 校驗和) = 0000 路由頭部
IPv6路由頭部位發送方提供一種IPv6資料報控制機制,以控制資料報通過網絡的路徑。路由頭部包含一個8位的路由類型辨別符和一個8位的剩餘部分字段。路由類型辨別符為0或者2,分别代表類型0(RH0)和類型2(RH2)。剩餘部分字段指出還有多少段路由需要處理,也就是在到達最終目的地之前仍需通路的中間節點數。
如下圖的路由轉發過程:
路由頭部指定了經過的路由路徑:R1、R2、R3、D;Left字段位剩餘部分字段。由于R0的位址在資料報中不存在,是以R0沒有修改路由頭部或位址。當資料報到達R1時,将基本頭部的目的位址和路由頭部的第一個位址交換,并将剩餘部分字段遞減1。
分片頭部
分片頭部用于IPv6源節點向目的地發送一個大于路徑MTU的資料報,1280位元組是整個網絡中針對IPv6定義的鍊路層最小MTU。
在IPv4中,如果資料報大小超過下一跳MTU,任何主機或路由器都可以将該資料分片,而在IPv6中僅資料報的發送者可以執行分片操作,這種情況下就需要添加一個分片頭部。
在分片過程中,輸入的資料報稱為“原始資料報”,它由兩部分組成: “不可分片部分”和“可分片部分”。
不可分片部分包括IPv6頭部和任何在到達目的地之前需由中間節點處理的擴充頭部(即包括路由頭部之前的所有頭部,如果有逐跳選項擴充頭部,則是該頭部之前的所有頭部);可分片部分包括資料報的其餘部分(即目的選項頭部、上層頭部和有效載荷資料)。當原始資料報被分片後,将會産生多個分片,其中每個分片都包含一個原始資料報中不可分片部分的副本,但是需要修改每個IPv6頭部的負栽長度字段,以反映它所描述的分片的大小。在不可分片部分之後,每個新的分片都包含一個分片頭部,其中包含一個分片相應的分片偏移字段(例如第一個分片的偏移量為0),以及一個原始分組的辨別符字段的副本。最後一個分片的M(更多分片)位字段設定為0。
資料報分片過程如圖:
1個3960位元組的有效載荷被分為3個1448位元組或更小的分片,每個分片包含一個帶相同的辨別符字段的分片頭部,除了最後一個分片,所有分片的更多分片(M)字段設定為1。偏移量以8位元組為機關,例如最後一個分片包含的資料是從原始資料開始處偏移(362*8)=2896位元組。
IP轉發
主機和路由器處理IP資料報的差別在于:主機不轉發那些不是由它生成的資料報,但路由器會。
IP轉發表包含以下資訊:
1. 目的地:32位字段,,用于與一個掩碼操作結果相比對。用于發送到所有目的地的預設路由情況下,位址全設為0。
2. 掩碼:32位字段,用作資料報目的IP位址按位與操作的掩碼。
3. 下一跳:下一個IP實體的32位IPv4位址或者128位的IPv6位址,資料報将被轉發到這。
4. 接口:它包含一個由IP層使用的辨別符,以确定将資料報發送到下一跳的網絡接口。
IP轉發逐跳進行,當一台主機或路由器中的IP層需要向下一跳的路由器或主機發送一個資料報時,它首先檢查資料報中的目的IP位址(D)。在轉發表中使用該值D來執行最長字首比對算法:在表中搜尋具有以下屬性的所有條目:(D^mj)=dj。
1. 其中mj是索引為j的轉發條目ej的掩碼字段值,dj是轉發條目ej的目的字段值。
2. 這意味着目的IP位址D與每個轉發表條目中的掩碼mj執行按位與,并将該結果與同一個條目中的目的地dj比較。
3. 如果滿足這個屬性,該條目ej與目的IP位址進行"比對"。
4. 當進行比對時,該算法檢視這個條目的索引j,以及在掩碼mj中有多少位設定為1。設定為1的位數越多,說明比對的越好。
5. 選擇最比對的條目ek(即掩碼mk中最多位為1的條目),将其下一跳字段nk作為轉發資料報的下一跳IP位址。
如果轉發表中沒有發現比對的條目,這個資料報則無法傳遞。
移動IP
基于上文中提到的"家鄉"的概念,移動IP的實作方案依賴于一種特殊類型的路由器,被稱為"家鄉代理",用于為移動節點提供路由。MIPv6的複雜性主要涉及信令消息以及如何保證它們的安全,這些消息使用各種形式的移動擴充頭部,是以移動IP自身實際上是一種特殊協定。
下圖顯示了MIPv6運作中涉及的實體,大部分适用于MIPv4。
1. 一台可能移動的主句稱為移動節點(MN),與它通信的主句稱為通信節點(CN)。
2. MN被賦予一個由家鄉網絡的網絡字首獲得的IP位址,被稱為家鄉位址HoA。
3. 當它漫遊到一個可通路的網絡時,它被賦予另外一個位址,稱為轉交位址CoA。
4. 當一個CN與一個MN通信時,該流量需要通過MN的家鄉代理HA來路由,并使用一種雙向的IPv6分組隧道,稱為雙向隧道。
這些消息通常由IPsec的封裝安全有效負載(ESP)來保護。
基于雙向隧道的MIPv6可能出現低效的路由,可使用路由優化(RO)方法來處理,這需要被涉及的各個節點都支援該功能。
路由優化涉及到一個通信注冊過程,一個MN将目前的CoA通知給相應的CN,允許它們執行無須HA協助的路由。操作分為兩部分:一部分涉及注冊綁定的建立和維護;一部分涉及所有綁定建立後的資料報交換方法。
為了與CN建議綁定,MN必須向每個CN證明自己的"真實身份",通過傳回路由程式RRP完成這些。
RRP中,MN和CN通過家鄉代理HA進行資訊轉發,以達到身份認證。如圖所示:
家鄉測試初始化(HoTI)、家鄉測試(HoT)、轉交測試初始化(CoTI)和轉交測試(CoT),數字表示順序。
HoT消息經由HA發送到MN,消息中包含稱為令牌的随機字元串, MN使用它形成一個加密密鑰,這個密鑰被用于生成發送給CN的經過認證的綁定更新。
IP資料報的主機處理
對于主機如何處理接收或發送的資料報,存在兩種模式:強主機模式和弱主機模式。
對于接收行為:
強主機模式中,隻有當"目的IP位址字段中包含的IP位址"與"資料報到達的接口配置的IP位址"比對時,才同意把将資料報傳遞本地協定棧。
弱主機模式中,"資料報攜帶的目的位址"與"它到達的任何接口的任何本地位址"比對,無論它到達哪個網絡接口,它都會被接收的協定棧處理。
對于發送行為:
強主機模式中,隻有在"資料報的源IP位址"所對應的網絡接口才可以發送資料報。
弱主機模式中,無論哪個網絡接口都可以發送資料報。
在Windows系統中,強主機模式是IPv4和IPv6發送和接收的預設模式;Linux中預設采用弱主機模式;BSD(含 Mac OS X)采用強主機模式。
當一台主機發送一個IP資料報時,它必須将自已的IP位址寫入資料報的源IP位址字段,在它已知多個位址的情況下,資料報的目的位址确定一台特定的目的主機。
目前IP實作中,資料報的源IP位址和目的IP位址是通過"源位址選擇程式和目的位址選擇程式"獲得的。
源位址選擇程式
算法說明:
1. 該算法定義了一個源位址的候選集合CS(D),基于一個特點的目的位址D(除去任播、多點傳播和未指定位址)。
2. 符号R(A)表示位址A在集合CS(D)中的等級,A比B的等級高,則R(A)>R(B),意味着優先選用A作為到達位址D的源位址。
3. R(A)*>R(B)表示在CS(D)中為A配置設定一個比B更高的等級。
4. I(D)表示選擇到達目的D的接口(通過最長比對字首轉發算法擷取)。
5. @i是配置設定給接口i的位址集合。
6. 如果A是一個臨時位址,T(A)為布爾值true,否則為false。
7. Q(D)表示目的地D選擇一個最高等級的源位址,如果Q(D)=φ(空),可能無法為目的地D确定源位址。
算法規則如下:
1. 優先選擇相同位址:if A = D, R(A) *> R(B);if B = D, R(B) *> R(A).
2. 優先選擇适當範圍:if S(A) < S(B) and S(A) < S(D), R(B) *> R(A) else R(A) *> R(B);if S(B) < S(A) and S(B) < S(D), R(A) *> R(B) else R(B) *> R(A).
3. 避免過期位址:if S(A)=S(B), {if ∧(A)<∧(B), R(B)*>R(A) else R(A)*>R(B)}.
4. 優先選擇家鄉位址:if H(A) and C(A) and ┐(C(B) and H(B)), R(A) *> R(B);if H(B) and C(B) and ┐(C(B) and H(A)), R(B) *> R(A);if (H(A) and ┐C(A)) and (┐H(B) and C(B)), R(A) *> R(B);if (H(B) and ┐C(B)) and (┐H(A) and C(A)), R(B) *> R(A).
5. 優先選擇輸出接口:if A ∈ @(I(D)) and B ∈ @(I(D)), R(A) *> R(B);if B ∈ @(I(D)) and A ∈ @(I(D)), R(B) *> R(A).
6. 優先選擇比對标簽:if L(A) = L(D) and L(B) ≠ L(D), R(A) *> R(B);if L(B) = L(D) and L(A) ≠ L(D), R(B) *> R(A).
7. 優先選則非臨時位址:if T(B) and ┐T(A), R(A) *> R(B);if T(A) and ┐T(B), R(B) *> R(A).
8. 使用最長比對字首:if CPL(A,D) > CPL(B,D), R(A) *> R(B);if CPL(B,D) > CPL(A,D), R(B) *> R(A).
目的位址選擇程式
1. Q(D)是為目的地D選擇的源位址
2. 如果目的地B不可到達,則U(B)為布爾值true
3. E(A)表示采用某些"封裝傳輸"可到達目的地A
4. 集合SD(S)采用與前面的成對元素A和B相同的結構
1. 避免不可用的目的地:if U(B) or Q(B) = φ, R(A) *> R(B);if U(A) or Q(A) = φ, R(B) *> R(A).
2. 優先選擇比對範圍:if S(A) = S(Q(A)) and S(B) ≠ S(Q(B)), R(A) *> R(B);if S(B) = S(Q(B)) and S(A) ≠ S(Q(A)), R(B) *> R(A).
3. 避免過期位址:if ∧(Q(A)) < ∧(Q(B)), R(B) *> R(A);if ∧(Q(B)) < ∧(Q(A)), R(A) *> R(B).
4. 優先選擇家鄉位址:if H(Q(A)) and C(Q(A)) and ┐(C(Q(B)) and H(Q(B))), R(A) *> R(B);if (Q(B)) and C(Q(B)) and ┐(C(Q(A)) and H(Q(A))), R(B) *> R(A);if (H(Q(A)) and ┐C(Q(A))) and (┐H(Q(B)) and C(Q(B))), R(A) *> R(B);if (H(Q(B)) and ┐C(Q(B))) and (┐H(Q(A)) and C(Q(A))), R(B) *> R(A).
5. 優先選擇比對标簽:if L(Q(A)) = L(A) and L(Q(B)) ≠ L(B), R(A) *> R(B);if L(Q(A)) ≠ L(A) and L(Q(B)) = L(B), R(B) *> R(A).
6. 優先選擇更高優先級:if P(A) > P(B), R(A) *> R(B);if P(A) < P(B), R(B) *> R(A).
7. 優先選擇本地傳輸:if E(A) and ┐E(B), R(B) *> R(A);if E(B) and ┐E(A), R(A) *> R(B).
8. 優先選擇更小範圍:if S(A) < S(B), R(A) *> R(B) else R(B) *> R(A).
9. 使用最長比對字首:if CPL(A,Q(A)) > CPL(B,Q(B)), R(A) *> R(B);if CPL(A,Q(A)) < CPL(B,Q(B)), R(B) *> R(A).
10. 否則,保持等級順序不變
這些算法(源位址和目的位址選擇)傾向于選擇範圍有限、永久性的位址。