為何需要預測?
通過分析序列進行合理預測,做到提前掌握未來的發展趨勢,為業務決策提供依據,這也是決策科學化的前提。
時間序列就是按時間順序排列的一組資料序列。時間序列分析就是發現這組資料的變動規律并用于預測的統計技術。
- 明天的賬單大約多少??(根據在各個雲産品中資源消耗量進行預測 ---> 業務穩定)
- 業務流量預測,明天各個小時的流量如何??(業務在穩定的情況下,也是可以預測的)
- 某公司的資源組的消耗情況??(何時下發MR任務,導緻哪些機器的資源消耗的情況,是具有一定規律,可以進行預測)
序列都可預測麼?
- 明天股票價格是多少,未來一年我買這個股票或者基金會賺多少錢??
- 預測一下下一期的彩票号碼是多少??
- ......
在大資料時代,相關關系似乎替代了因果關系。然而世界具有複雜性,大資料時代世界似乎被資料統治,是混沌的。相關關系是指當一個資料變化時,另一個資料也可能随之變化,不論是這兩個資料也沒有必然聯系。相關關系有可能是正相關也有可能是負相關,有可能是強相關也有可能是弱相關。因果關系是指當一個作為原因的資料變化時,另一個作為結果的資料在一定程度發生變化,這兩個資料存在着必然聯系。因果關系可能是線性關系,也可能是非線性關系。
回歸模型比相關系數進了一步,它可以解釋資料之間作用機制和作用的大小。但回歸模型即使通過了各種統計檢驗,也可能隻在一定程度上說明事物之間的因果關系。模型的自變量不一定是原因,因變量不一定是結果。$X_i$與$y_i$之間的因果關系是否成立,還要由統計學所應用領域的專家來判斷,如經濟學家、管理學家、生物學家、醫學家等,并大量的實踐得到檢驗。統計模型隻能說包含真正因果關系的可能性較大,二真值在哪裡?上帝知道。
我們能預測什麼?
- SLB産品中,某使用者的
- 某執行個體小時級别最大連結數預測
- 某執行個體小時級别每秒連結數預測
- 某執行個體每小時的QPS量預測
- 某執行個體每小時入向流量預測
- 某執行個體每小時出向流量預測
- OSS産品中,某使用者的
- 小時級别存儲量預測
- 小時級别外網流量、CDN回源流量預測
- 小時級别Get請求和Put請求數量的預測
- ECS産品中,某用的使用情況
- 某使用者在某叢集中60min/30min/15minCPU使用情況的預測
- 某使用者在某叢集中60min/30min/15minIO延遲情況的預測
- 具有相對穩定的業務規律的時序資料(>=15min的資料點)能更好的預測
我們提供了什麼?
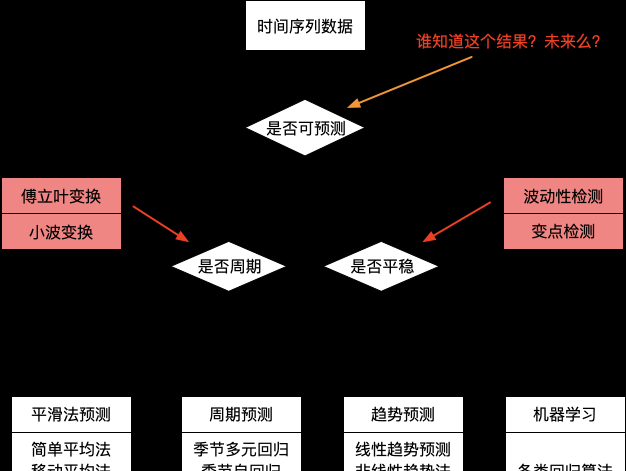
統計學模型
ts_predicate_simple(unixtime, val, nPred, samplePeriod, sampleMethod)
ts_predicate_ar(unixtime, val, p, nPred, samplePeriod, sampleMethod)
ts_predicate_arma(unixtime, val, p, q, nPred, samplePeriod, sampleMethod)
ts_predicate_arima(unixtime, val, p, d, q, nPred, samplePeriod, sampleMethod) 機器學習模型
- 不對資料做任何處理,直接使用GBRT模型進行預測
ts_regression_predict(unixtime, val, nPred, 'origin', samplePeriod, sampleMethod) - 對資料做時序分解,對分解出來的序列分别做預測,在進行整合
ts_regression_predict(unixtime, val, nPred, 'forest', samplePeriod, sampleMethod) - 不對資料做任何處理,使用線性模型進行預測
ts_regression_predict(unixtime, val, nPred, 'linear', samplePeriod, sampleMethod) 實際案例
使用者存儲量的預測
select ts_regression_predict(EndTime, Storage, 168, 'linear', 1, 'avg') from (
select EndTime, sum(Storage) as Storage from log GROUP by EndTime ) limit 1000 
使用者外網流量的預測
select ts_regression_predict(EndTime, NetworkOut, 168, 'origin', 1, 'avg') from (
select EndTime, sum(NetworkOut) as NetworkOut from log GROUP by EndTime ) limit 10000 使用者Get請求數量的預測
select ts_regression_predict(EndTime, GetRequest, 168, 'origin', 1, 'avg') from (
select EndTime, sum(GetRequest) as GetRequest from log GROUP by EndTime) limit 1000 機櫃電量預測
select ts_regression_predict(time, rackTotalPower, 100, 'origin', 1, 'avg') from (
select __time__ - __time__ % 1800 as time, sum(rackTotalPower) as rackTotalPower from log GROUP BY time ) limit 10000 SLB中各個名額的預測情況
相關文獻
- Autoregressive–moving-average model
- Time Series Analysis - 時間序列分析
- 随機過程與應用
- STL Decompose
- Gradient Boosting
- Gradient Boosted Regression Trees
- Web-Search Ranking with Initialized Gradient Boosted Regression Trees
- A General Boosting Method and its Application to Learning Ranking Functions for Web Search
硬廣時間
日志進階
阿裡雲日志服務針對日志提供了完整的解決方案,以下相關功能是日志進階的必備良藥:
- 機器學習文法與函數: https://help.aliyun.com/document_detail/93024.html
- 日志上下文查詢: https://help.aliyun.com/document_detail/48148.html
- 快速查詢: https://help.aliyun.com/document_detail/88985.html
- 實時分析: https://help.aliyun.com/document_detail/53608.html
- 快速分析: https://help.aliyun.com/document_detail/66275.html
- 基于日志設定告警: https://help.aliyun.com/document_detail/48162.html
- 配置大盤: https://help.aliyun.com/document_detail/69313.html
更多日志進階内容可以參考:
日志服務學習路徑。
聯系我們
糾錯或者幫助文檔以及最佳實踐貢獻,請聯系:悟冥
問題咨詢請加釘釘群: