mysql中的utf8
mysql中的“utf8”最大隻支援3 個bytes,而真正的utf8編碼(大家都使用的标準),最大支援4個bytes。正是由于mysql的utf8少一個byte,導緻中文的一些特殊字元和emoji都無法正常的顯示。mysql真正的utf8其實是utf8mb4,這是在5.5版本之後加入的。而目前的“utf8”其實是utf8mb3。mb就是 max bytes的意思(猜測)。是以盡量不要使用預設的utf8,使用utf8mb4才是正确的選擇。
mysql> show create table t1;
+-------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+-------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| t1 | CREATE TABLE `t1` (
`info` varchar(10) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci |
+-------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
mysql>
mysql>
mysql>
mysql>
mysql>
mysql>
mysql> select length('你');
+---------------+
| length('你') |
+---------------+
| 3 |
+---------------+
1 row in set (0.00 sec)
mysql> select length('𩱻');
+-------------+
| length('?') |
+-------------+
| 4 |
+-------------+
1 row in set (0.00 sec)
mysql>
mysql>
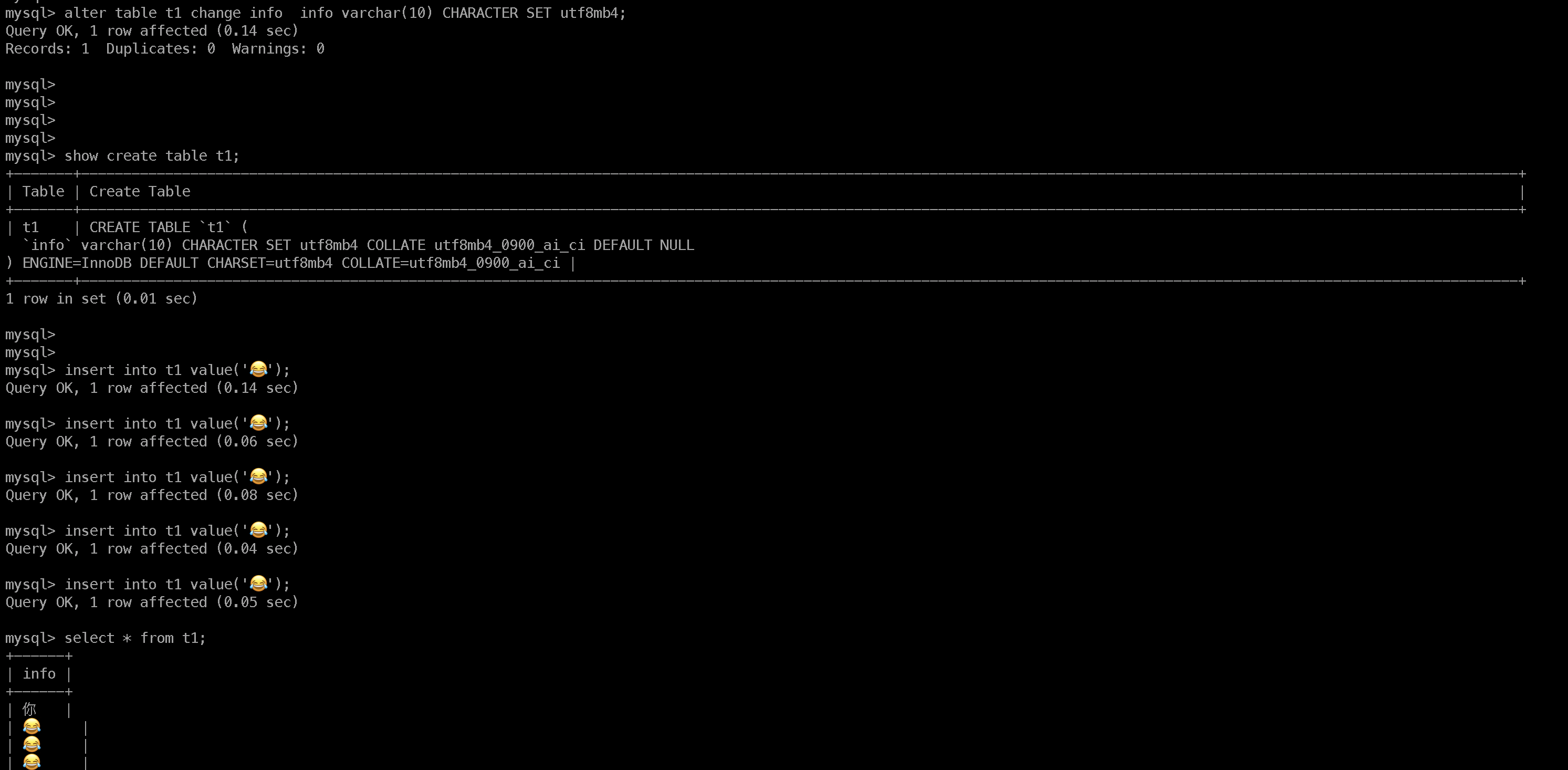
mysql> insert into t1 value('你');
Query OK, 1 row affected (0.05 sec)
mysql> insert into t1 value('𩱻');
ERROR 1366 (HY000): Incorrect string value: '\xF0\xA9\xB1\xBB' for column 'info' at row 1
mysql> 建立了一個編碼為utf8的列info,插入byte長度分别為3位和4位的中文,可以發現插入4位中文是報錯。同樣我們看看emoji表情:
utf8可以直接轉成utf8mb4,使用ALTER TABLE ... CONVERT TO CHARACTER SET ...語句,這是由于utf8是utf8mb4的子集。其他類型最好不要直接轉,會出現問題,比如latin轉utf8.
這篇文章描述了一種錯誤情況。檢視資料庫支援的編碼
> mysql> select * from information_schema.CHARACTER_SETS;
> +--------------------+----------------------+---------------------------------+--------+
> | CHARACTER_SET_NAME | DEFAULT_COLLATE_NAME | DESCRIPTION | MAXLEN |
> +--------------------+----------------------+---------------------------------+--------+
> | big5 | big5_chinese_ci | Big5 Traditional Chinese | 2 |
> | dec8 | dec8_swedish_ci | DEC West European | 1 |
> | cp850 | cp850_general_ci | DOS West European | 1 |
> | hp8 | hp8_english_ci | HP West European | 1 |
> | koi8r | koi8r_general_ci | KOI8-R Relcom Russian | 1 |
> | latin1 | latin1_swedish_ci | cp1252 West European | 1 |
> | latin2 | latin2_general_ci | ISO 8859-2 Central European | 1 |
> | swe7 | swe7_swedish_ci | 7bit Swedish | 1 |
> | ascii | ascii_general_ci | US ASCII | 1 |
> | ujis | ujis_japanese_ci | EUC-JP Japanese | 3 |
> | sjis | sjis_japanese_ci | Shift-JIS Japanese | 2 |
> | hebrew | hebrew_general_ci | ISO 8859-8 Hebrew | 1 |
> | tis620 | tis620_thai_ci | TIS620 Thai | 1 |
> | euckr | euckr_korean_ci | EUC-KR Korean | 2 |
> | koi8u | koi8u_general_ci | KOI8-U Ukrainian | 1 |
> | gb2312 | gb2312_chinese_ci | GB2312 Simplified Chinese | 2 |
> | greek | greek_general_ci | ISO 8859-7 Greek | 1 |
> | cp1250 | cp1250_general_ci | Windows Central European | 1 |
> | gbk | gbk_chinese_ci | GBK Simplified Chinese | 2 |
> | latin5 | latin5_turkish_ci | ISO 8859-9 Turkish | 1 |
> | armscii8 | armscii8_general_ci | ARMSCII-8 Armenian | 1 |
> | utf8 | utf8_general_ci | UTF-8 Unicode | 3 |
> | ucs2 | ucs2_general_ci | UCS-2 Unicode | 2 |
> | cp866 | cp866_general_ci | DOS Russian | 1 |
> | keybcs2 | keybcs2_general_ci | DOS Kamenicky Czech-Slovak | 1 |
> | macce | macce_general_ci | Mac Central European | 1 |
> | macroman | macroman_general_ci | Mac West European | 1 |
> | cp852 | cp852_general_ci | DOS Central European | 1 |
> | latin7 | latin7_general_ci | ISO 8859-13 Baltic | 1 |
> | cp1251 | cp1251_general_ci | Windows Cyrillic | 1 |
> | utf16 | utf16_general_ci | UTF-16 Unicode | 4 |
> | utf16le | utf16le_general_ci | UTF-16LE Unicode | 4 |
> | cp1256 | cp1256_general_ci | Windows Arabic | 1 |
> | cp1257 | cp1257_general_ci | Windows Baltic | 1 |
> | utf32 | utf32_general_ci | UTF-32 Unicode | 4 |
> | binary | binary | Binary pseudo charset | 1 |
> | geostd8 | geostd8_general_ci | GEOSTD8 Georgian | 1 |
> | cp932 | cp932_japanese_ci | SJIS for Windows Japanese | 2 |
> | eucjpms | eucjpms_japanese_ci | UJIS for Windows Japanese | 3 |
> | gb18030 | gb18030_chinese_ci | China National Standard GB18030 | 4 |
> | utf8mb4 | utf8mb4_0900_ai_ci | UTF-8 Unicode | 4 |
> +--------------------+----------------------+---------------------------------+--------+ 由于mysql中utf8的maxlen是3個byte,而正常的unicode使用的是2~4個byte,導緻mysql的 不能顯示emoji和一些生僻的中文。是以mysql又推出了uft8mb4,這個才是真正的utf8編碼。不過在oracle接手mysql之後,預設的字元編碼之後會改成utf8mb4。
這裡詳細闡述了mysql utf8編碼的坑以及應對方法。伺服器參數設定
[mysqld]
character_set_server=utf8mb4
aws雲上資料庫設定
參數組中:
- character_set_client
- character_set_connection
- character_set_database
- character_set_results
-
character_set_server
這幾個參數設定成utf8mb4,不過這裡有個限制,aws的資料傳輸工具DMS中不支援utf8mb4編碼,有這類需求的同學需要注意。--已經在3.1.1版本中修複。
查詢目前字元集設定
檢視參數
mysql> show variables like 'character%';
+--------------------------+------------------------------------------------------+
| Variable_name | Value |
+--------------------------+------------------------------------------------------+
| character_set_client | utf8mb4 |
| character_set_connection | utf8mb4 |
| character_set_database | utf8mb4 |
| character_set_filesystem | binary |
| character_set_results | utf8mb4 |
| character_set_server | utf8mb4 |
| character_set_system | utf8 |
| character_sets_dir | /usr/local/Cellar/mysql/8.0.12/share/mysql/charsets/ |
+--------------------------+------------------------------------------------------+ 檢視資料庫字元集
mysql> select * from information_schema.SCHEMATA;
+--------------+--------------------+----------------------------+------------------------+----------+
| CATALOG_NAME | SCHEMA_NAME | DEFAULT_CHARACTER_SET_NAME | DEFAULT_COLLATION_NAME | SQL_PATH |
+--------------+--------------------+----------------------------+------------------------+----------+
| def | mysql | utf8 | utf8_general_ci | NULL |
| def | information_schema | utf8 | utf8_general_ci | NULL |
| def | performance_schema | utf8mb4 | utf8mb4_0900_ai_ci | NULL |
| def | sys | utf8mb4 | utf8mb4_0900_ai_ci | NULL |
| def | mydb | utf8mb4 | utf8mb4_unicode_ci | NULL |
| def | t1 | utf8mb4 | utf8mb4_0900_ai_ci | NULL |
+--------------+--------------------+----------------------------+------------------------+----------+ 檢視表的字元集
mysql> show create table t1\G
*************************** 1. row ***************************
Table: t1
Create Table: CREATE TABLE `t1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`description` varchar(50) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
1 row in set (0.00 sec) mysql> show table status from t1\G
*************************** 1. row ***************************
Name: t3
Engine: InnoDB
Version: 10
Row_format: Dynamic
Rows: 0
Avg_row_length: 0
Data_length: 16384
Max_data_length: 0
Index_length: 0
Data_free: 0
Auto_increment: NULL
Create_time: 2018-11-28 12:05:37
Update_time: NULL
Check_time: NULL
Collation: utf8mb4_0900_ai_ci
Checksum: NULL
Create_options:
Comment:
1 row in set (0.15 sec) 這種情況隻能看到Collation,Collation的概念是字元比較的規則,每種字元集都會有其預設的Collation,我們從information_schema.CHARACTER_SETS這個表中可以查詢到相應的資訊,一般我們設定好字元集之後,Collation會被預設該字元集的預設值。
檢視所有表的字元集
mysql> select TABLE_SCHEMA,TABLE_NAME,TABLE_COLLATION from information_schema.tables where table_schema = 'mydb';
+--------------+---------------------+--------------------+
| TABLE_SCHEMA | TABLE_NAME | TABLE_COLLATION |
+--------------+---------------------+--------------------+
| mydb | charset_test_latin1 | utf8mb4_0900_ai_ci |
| mydb | student | utf8_general_ci |
| mydb | t1 | utf8mb4_0900_ai_ci |
| mydb | t2 | utf8_general_ci |
| mydb | t3 | utf8_general_ci |
| mydb | t4 | utf8_general_ci |
| mydb | t5 | utf8mb4_unicode_ci |
| mydb | t6 | utf8mb4_0900_ai_ci |
| mydb | t8 | utf8mb4_unicode_ci |
| mydb | vc | utf8mb4_unicode_ci |
+--------------+---------------------+--------------------+ 這種方法可以檢視到一個資料庫中所有表的TABLE_COLLATION,推導出對應使用什麼類型的字元集。
檢視所有列的字元集
mysql> select TABLE_SCHEMA,TABLE_NAME,COLUMN_NAME,DATA_TYPE,CHARACTER_SET_NAME,COLLATION_NAME from information_schema.columns where TABLE_SCHEMA='mydb';
+--------------+---------------------+-------------+-----------+--------------------+--------------------+
| TABLE_SCHEMA | TABLE_NAME | COLUMN_NAME | DATA_TYPE | CHARACTER_SET_NAME | COLLATION_NAME |
+--------------+---------------------+-------------+-----------+--------------------+--------------------+
| mydb | charset_test_latin1 | id | int | NULL | NULL |
| mydb | charset_test_latin1 | char_col | varchar | utf8mb4 | utf8mb4_0900_ai_ci |
| mydb | student | course | varchar | utf8 | utf8_general_ci |
| mydb | student | mark | int | NULL | NULL |
| mydb | student | name | varchar | utf8 | utf8_general_ci |
| mydb | t1 | id | int | NULL | NULL |
| mydb | t1 | description | varchar | utf8mb4 | utf8mb4_0900_ai_ci |
| mydb | t2 | info | varchar | utf8 | utf8_general_ci |
| mydb | t3 | info | varchar | utf8mb4 | utf8mb4_0900_ai_ci |
| mydb | t4 | info | char | utf8mb4 | utf8mb4_0900_ai_ci |
| mydb | t5 | info | char | utf8mb4 | utf8mb4_unicode_ci |
| mydb | t6 | info | varchar | utf8mb4 | utf8mb4_0900_ai_ci |
| mydb | t8 | id | int | NULL | NULL |
| mydb | vc | v | varchar | utf8mb4 | utf8mb4_unicode_ci |
| mydb | vc | c | char | utf8mb4 | utf8mb4_unicode_ci |
+--------------+---------------------+-------------+-----------+--------------------+--------------------+ utf8 轉 utf8mb4
For each database:
ALTER DATABASE
database_name
CHARACTER SET = utf8mb4
COLLATE = utf8mb4_unicode_ci; For each table:
ALTER TABLE
table_name
CONVERT TO CHARACTER SET utf8mb4
COLLATE utf8mb4_unicode_ci; For each column:
ALTER TABLE
table_name
CHANGE column_name column_name
data_type
CHARACTER SET utf8mb4
COLLATE utf8mb4_unicode_ci; utf8是utf8mb4的子集,是以直接轉換理論上不會有問題。當然也可以使用dump轉換編碼。
批量生成腳本:
use information_schema;
SELECT concat("ALTER DATABASE `",table_schema,"` CHARACTER SET = utf8mb4 COLLATE = utf8mb4_unicode_ci;") as _sql
FROM `TABLES` where table_schema like "yourDbName" group by table_schema;
SELECT concat("ALTER TABLE `",table_schema,"`.`",table_name,"` CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;") as _sql
FROM `TABLES` where table_schema like "yourDbName" group by table_schema, table_name;
SELECT concat("ALTER TABLE `",table_schema,"`.`",table_name, "` CHANGE `",column_name,"` `",column_name,"` ",data_type,"(",character_maximum_length,") CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;") as _sql
FROM `COLUMNS` where table_schema like "yourDbName" and data_type in ('varchar');
SELECT concat("ALTER TABLE `",table_schema,"`.`",table_name, "` CHANGE `",column_name,"` `",column_name,"` ",data_type," CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;") as _sql
FROM `COLUMNS` where table_schema like "yourDbName" and data_type in ('text','tinytext','mediumtext','longtext'); ERROR 1071 (42000) 問題解決
出現這種報錯主要有兩種情況:
ERROR 1071 (42000): Specified key was too long; max key length is 3072 bytes ERROR 1071 (42000): Specified key was too long; max key length is 1000 bytes 一個是length 大于3072 bytes,一個是大于1000 bytes。
mysql5.7中支援index key最大的長度是 767 bytes,在開啟了innodb_large_prefix這個參數之後,max len 限制是3072 bytes。在5.7之前這個參數沒有預設開啟,5.7之後預設是開啟的。8.0之後去掉了這個參數,預設就支援3072個位元組。
是以在轉換字元集過程中,如果一個列上有索引,由于之前的utf8的編碼是3個bytes,utf8mb4是4個bytes。轉換之後key的值可能會超過767或則3072,這個時候就是出現類似的報錯。如果是MyISAM的引擎,是直接不能超過1000 bytes這個限制的。
這個時候的解決辦法是如果是MyISAM的引擎,改成innodb引擎。
如果改成innodb還不行,隻能縮小字段的大小。
常用指令
set names utf8mb4;
相當于設定
- 三個值為utf8mb4.
總結
不得不說,mysql這個3個byte的utf8是個巨坑,沒有按照國際的标準來設計,不過之後肯定會改成utf8mb4為預設字元集。
![vue搭建過程及出現問題[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)