原文網站已經打不開了,其他都是轉載位址,在此就不列了
簡介
[HBase]——Hadoop Database的簡稱,Google BigTable的另一種開源實作方式,從問世之初,就為了解決用大量廉價的機器高速存取海量資料、實作資料分布式存儲提供可靠的方案。從功能上來講,HBase不折不扣是一個資料庫,與我們熟悉的Oracle、MySQL、MSSQL等一樣,對外提供資料的存儲和讀取服務。而從應用的角度來說,HBase與一般的資料庫又有所差別,HBase本身的存取接口相當簡單,不支援複雜的資料存取,更不支援SQL等結構化的查詢語言;HBase也沒有除了rowkey以外的索引,所有的資料分布和查詢都依賴rowkey。
是以HBase在表的設計上會有很嚴格的要求。
架構上,HBase是分布式資料庫的典範,這點比較像MongoDB的sharding模式,能根據鍵值的大小,把資料分布到不同的存儲節點上,MongoDB根據configserver來定位資料落在哪個分區上,HBase通過通路Zookeeper來擷取-ROOT-表所在位址,通過-ROOT-表得到相應.META.表資訊,進而擷取資料存儲的region位置。
架構
上面提到,HBase是一個分布式的架構,除去底層存儲的HDFS外,HBase本身從功能上可以分為三塊:Zookeeper群、Master群和RegionServer群。
- Zookeeper群:HBase叢集中不可缺少的重要部分,主要用于存儲Master位址、協調Master和RegionServer等上下線、存儲臨時資料等等。
- Master群:Master主要是做一些管理操作,如:region的配置設定,手動管理操作下發等等,一般資料的讀寫操作并不需要經過Master叢集,是以Master一般不需要很高的配置即可。
- RegionServer群:RegionServer群是真正資料存儲的地方,每個RegionServer由若幹個region組成,而一個region維護了一定區間rowkey值的資料,整個結構如下圖:
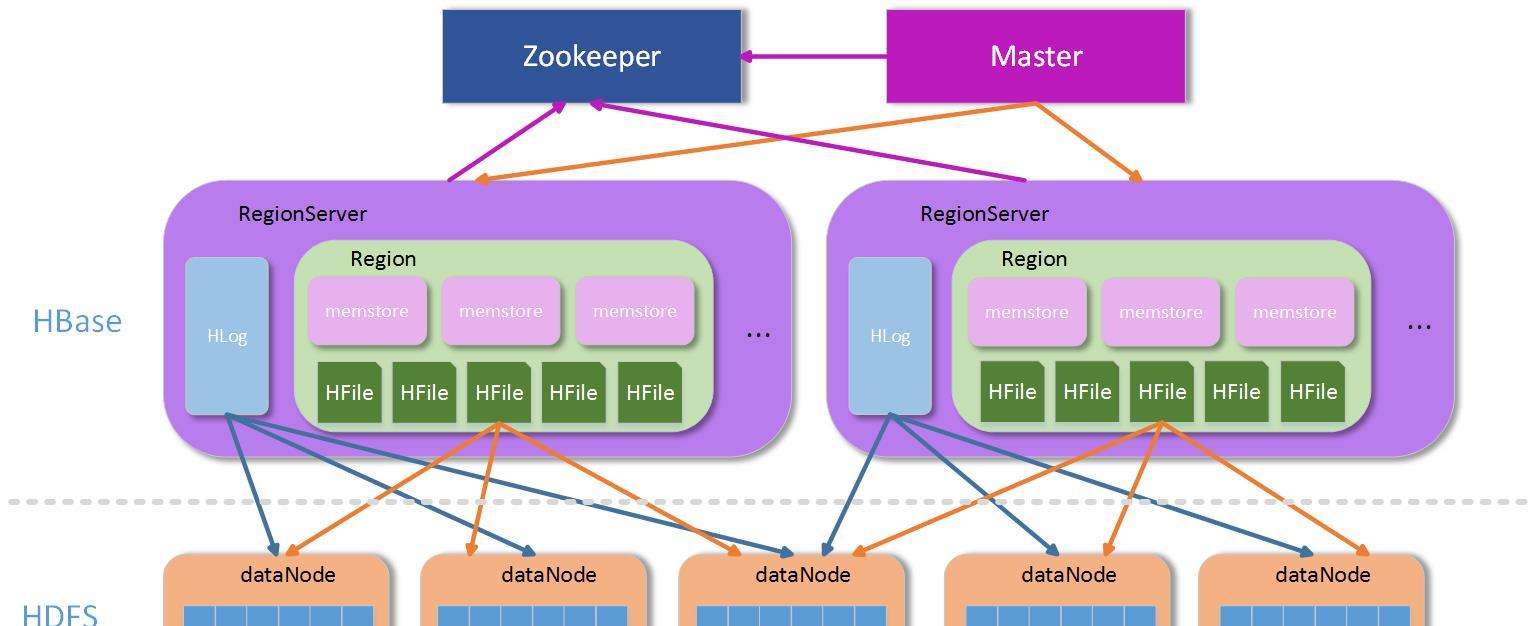
HBase結構圖
上圖中,Zookeeper(簡稱ZK)是一個叢集,通常有奇數個ZK服務組成。Master為了服務可用性,也建議部署成叢集方式,因為Master是整個管理操作的發起者,如果Master一旦發生意外停機,整個叢集将會無法進行管理操作,是以Master也必須有多個,當然多個Master也有主從之分,如何區分哪個是主,哪個是從?關鍵看哪個Master能競争到ZK上對應Master目錄下的鎖,持有該目錄鎖的Master為主Master,其他從Master輪詢競争該鎖,是以一旦主Master發生意外停機,從Master很快會因為競争到Master檔案夾上的鎖而接管服務。
RegionServer(簡稱RS)在非Replication模式下,整個系統中都是唯一的,也就是說,在整個非Replication的HBase叢集中,每台RS上儲存的資料都不一樣,是以相對于前面兩者,該模式下的RS并不是高可用的,至少RS可能存在單點故障的問題,但是由于HBase内部資料分region存儲和region可以遷移的機制,RS服務的單點故障可能會在極小代價下很快恢複,但是一旦停掉的RS上有-ROOT-或者.META.表的region,那後果還是比較嚴重,因為資料節點的RS停機,隻會在短時間内影響該台RS上的region不可通路,等到region遷移完成後即可恢複,如果是-ROOT-、.META.所在的RS停機,整個HBase的新的求情都将受到影響,因為需要通過.META.表來路由,進而尋找到region所在RS的位址。
資料組織
整個架構中,ZK用于服務協調和整個叢集運作過程中部分資訊的儲存和-ROOT-表位址定位,Master用于叢集内部管理,是以剩下的RS主要用于處理資料。
RS是處理資料的主要場所,那麼在RS内部的資料是怎麼分布的?其實RS本身隻是一個容器,其定義了一些功能線程,比如:資料合并線程(compact thread)、storeFile分割線程(split thread)等等。容器中的主要對象就是region,region是一個表根據自身rowkey範圍劃分的一部分,一個表可以被劃分成若幹部分,也就是若幹個region,region可以根據rowkey範圍不同而被分布在不同的RS上(當然也可以在同一個RS上,但不建議這麼做)。一個RS上可以包含多個表的region,也可以隻包含一個表的部分region,RS和表是兩個不同的概念。
這裡還有一個概念——列簇。對HBase有一些了解的人,或多或少聽說過:HBase是一個列式存儲的資料庫,而這個列式存儲中的列,其實是差別于一般資料庫的列,這裡的列的概念,就是列簇。列簇,顧名思義就是很多列的集合,而在資料存儲上來講,不同列簇的資料,一定是分開存儲的,即使是在同一個region内部,不同的列簇也存儲在不同的檔案夾中,這樣做的好處是,一般我們定義列簇的時候,通常會把類似的資料放入同一個列簇,不同的列簇分開存儲,有利于資料的壓縮,并且HBase本身支援多種壓縮方式。
原理
前面介紹了HBase的一般架構,我們知道了HBase有ZK、Master和RS等組成,本節我們來介紹下HBase的基本原理,從資料通路、RS路由到RS内部緩存、資料存儲和刷寫再到region的合并和拆分等等功能。
RegionServer定位
通路HBase通過HBase用戶端(或API)進行,整個HBase提供給外部的位址,其實是ZK的入口,前面也介紹了,ZK中有儲存-ROOT-所在的RS位址,從-ROOT-表可以擷取.META.表資訊,根據.META.表可以擷取region在RS上的分布,整個region尋址過程大緻如下:

RS定位過程
首先,Client通過通路ZK來請求目标資料的位址。
ZK中儲存了-ROOT-表的位址,是以ZK通過通路-ROOT-表來請求資料位址。同樣,-ROOT-表中儲存的是.META.的資訊,通過通路.META.表來擷取具體的RS。.META.表查詢到具體RS資訊後傳回具體RS位址給Client。Client端擷取到目标位址後,然後直接向該位址發送資料請求。
上述過程其實是一個三層索引結構,從ZK擷取-ROOT-資訊,再從-ROOT-擷取.META.表資訊,最後從.META.表中查到RS位址後緩存。這裡有幾個問題:
- 既然ZK中能儲存-ROOT-資訊,那麼為什麼不把.META.資訊直接儲存在ZK中,而需要通過-ROOT-表來定位?
- Client查找到目标位址後,下一次請求還需要走ZK —> -ROOT- —> .META.這個流程麼?
- 先來回答第一個問題:為什麼不直接把.META.表資訊直接儲存到ZK中?主要是為了儲存的資料量考慮,ZK中不宜儲存大量資料,而.META.表主要是儲存Region和RS的映射資訊,region的數量沒有具體限制,隻要在記憶體允許的範圍内,region數量可以有很多,如果儲存在ZK中,ZK的壓力會很大。是以通過一個-ROOT-表來轉存到RS中是一個比較理想的方案,相比直接儲存在ZK中,也就多了一層-ROOT-表的查詢,對性能來說影響不大。
- 第二個問題:每次通路都需要走ZK –> -ROOT- —> .META.的流程麼?當然不需要,Client端有緩存,第一次查詢到相應region所在RS後,這個資訊将被緩存到Client端,以後每次通路都直接從緩存中擷取RS位址即可。當然這裡有個意外:通路的region若果在RS上發生了改變,比如被balancer遷移到其他RS上了,這個時候,通過緩存的位址通路會出現異常,在出現異常的情況下,Client需要重新走一遍上面的流程來擷取新的RS位址。總體來說,region的變動隻會在極少數情況下發生,一般變動不會很大,是以在整個叢集通路過程中,影響可以忽略。
Region資料寫入
HBase通過ZK —> -ROOT- —> .META.的通路擷取RS位址後,直接向該RS上進行資料寫入操作,整個過程如下圖:
RegionServer資料操作過程
Client通過三層索引獲得RS的位址後,即可向指定RS的對應region進行資料寫入,HBase的資料寫入采用WAL(write ahead log)的形式,先寫log,後寫資料。HBase是一個append類型的資料庫,沒有關系型資料庫那麼複雜的操作,是以記錄HLog的操作都是簡單的put操作(delete/update操作都被轉化為put進行)
HLog
HLog寫入
HLog是HBase實作WAL方式産生的日志資訊,其内部是一個簡單的順序日志,每個RS上的region都共享一個HLog,所有對于該RS上的region資料寫入都被記錄到該HLog中。HLog的主要作用就是在RS出現意外崩潰的時候,可以盡量多的恢複資料,這裡說是盡量多,因為在一般情況下,用戶端為了提高性能,會把HLog的auto flush關掉,這樣HLog日志的落盤全靠作業系統保證,如果出現意外崩潰,短時間内沒有被fsync的日志會被丢失。
HLog過期
HLog的大量寫入會造成HLog占用存儲空間會越來越大,HBase通過HLog過期的方式進行HLog的清理,每個RS内部都有一個HLog監控線程在運作,其周期可以通過hbase.master.cleaner.interval進行配置。
HLog在資料從memstore flush到底層存儲上後,說明該段HLog已經不再被需要,就會被移動到.oldlogs這個目錄下,HLog監控線程監控該目錄下的HLog,當該檔案夾下的HLog達到hbase.master.logcleaner.ttl設定的過期條件後,監控線程立即删除過期的HLog。
Memstore
資料存儲
memstore是region内部緩存,其大小通過HBase參數hbase.hregion.memstore.flush.size進行配置。RS在寫完HLog以後,資料寫入的下一個目标就是region的memstore,memstore在HBase内部通過LSM-tree結構組織,是以能夠合并大量對于相同rowkey上的更新操作。
正是由于memstore的存在,HBase的資料寫入都是異步的,而且性能非常不錯,寫入到memstore後,該次寫入請求就可以被傳回,HBase即認為該次資料寫入成功。這裡有一點需要說明,寫入到memstore中的資料都是預先按照rowkey的值進行排序的,這樣有利于後續資料查找。
資料刷盤
memstore中的資料在一定條件下會進行刷寫操作,使資料持久化到相應的儲存設備上,觸發memstore刷盤的操作有多種不同的方式如下圖:
Memstore刷寫流程以上1,2,3都可以觸發memstore的flush操作,但是實作的方式不同:
- 1、通過全局記憶體控制,觸發memstore刷盤操作memstore整體記憶體占用上限通過參數hbase.regionserver.global.memstore.upperLimit進行設定,當然在達到上限後,memstore的刷寫也不是一直進行,在記憶體下降到hbase.regionserver.global.memstore.lowerLimit配置的值後,即停止memstore的刷盤操作。這樣做,主要是為了防止長時間的memstore刷盤,會影響整體的性能。在該種情況下,RS中所有region的memstore記憶體占用都沒達到刷盤條件,但整體的記憶體消耗已經到一個非常危險的範圍,如果持續下去,很有可能造成RS的OOM,這個時候,需要進行memstore的刷盤,進而釋放記憶體。
- 2、手動觸發memstore刷盤操作HBase提供API接口,運作通過外部調用進行memstore的刷盤
- 3、memstore上限觸發資料刷盤前面提到memstore的大小通過hbase.hregion.memstore.flush.size進行設定,當region中memstore的資料量達到該值時,會自動觸發memstore的刷盤操作。
刷盤影響
memstore在不同的條件下會觸發資料刷盤,那麼整個資料在刷盤過程中,對region的資料寫入等有什麼影響?memstore的資料刷盤,對region的直接影響就是:在資料刷盤開始到結束這段時間内,該region上的通路都是被拒絕的,這裡主要是因為在資料刷盤結束時,RS會對改region做一個snapshot,同時HLog做一個checkpoint操作,通知ZK哪些HLog可以被移到.oldlogs下。從前面圖上也可以看到,在memstore寫盤開始,相應region會被加上UpdateLock鎖,寫盤結束後該鎖被釋放。
StoreFile
memstore在觸發刷盤操作後會被寫入底層存儲,每次memstore的刷盤就會相應生成一個存儲檔案HFile,storeFile即HFile在HBase層的輕量級分裝。資料量的持續寫入,造成memstore的頻繁flush,每次flush都會産生一個HFile,這樣底層儲存設備上的HFile檔案數量将會越來越多。不管是HDFS還是Linux下常用的檔案系統如Ext4、XFS等,對小而多的檔案上的管理都沒有大檔案來的有效,比如小檔案打開需要消耗更多的檔案句柄;在大量小檔案中進行指定rowkey資料的查詢性能沒有在少量大檔案中查詢來的快等等。
Compact
大量HFile的産生,會消耗更多的檔案句柄,同時會造成RS在資料查詢等的效率大幅度下降,HBase為解決這個問題,引入了compact操作,RS通過compact把大量小的HFile進行檔案合并,生成大的HFile檔案。RS上的compact根據功能的不同,可以分為兩種不同類型,即:minor compact和major compact。
Minor Compact
minor compact又叫small compact,在RS運作過程中會頻繁進行,主要通過參數hbase.hstore.compactionThreshold進行控制,該參數配置了HFile數量在滿足該值時,進行minor compact,minor compact隻選取region下部分HFile進行compact操作,并且選取的HFile大小不能超過hbase.hregion.max.filesize參數設定。
Major Compact
相反major compact也被稱之為large compact,major compact會對整個region下相同列簇的所有HFile進行compact,也就是說major compact結束後,同一個列簇下的HFile會被合并成一個。major compact是一個比較長的過程,對底層I/O的壓力相對較大。
major compact除了合并HFile外,另外一個重要功能就是清理過期或者被删除的資料。前面提到過,HBase的delete操作也是通過append的方式寫入,一旦某些資料在HBase内部被删除了,在内部隻是被簡單标記為删除,真正在存儲層面沒有進行資料清理,隻有通過major compact對HFile進行重組時,被标記為删除的資料才能被真正的清理。
compact操作都有特定的線程進行,一般情況下不會影響RS上資料寫入的性能,當然也有例外:在compact操作速度跟不上region中HFile增長速度時,為了安全考慮,RS會在HFile達到一定數量時,對寫入進行鎖定操作,直到HFile通過compact降到一定的範圍内才釋放鎖。
Split
compact将多個HFile合并單個HFile檔案,随着資料量的不斷寫入,單個HFile也會越來越大,大量小的HFile會影響資料查詢性能,大的HFile也會,HFile越大,相對的在HFile中搜尋的指定rowkey的資料花的時間也就越長,HBase同樣提供了region的split方案來解決大的HFile造成資料查詢時間過長問題。
一個較大的region通過split操作,會生成兩個小的region,稱之為Daughter,一般Daughter中的資料是根據rowkey的之間點進行切分的,region的split過程大緻如下圖:
region split流程
- 1、region先更改ZK中該region的狀态為SPLITING。
- 2、Master檢測到region狀态改變。
- 3、region會在存儲目錄下建立.split檔案夾用于儲存split後的daughter region資訊。
- 4、Parent region關閉資料寫入并觸發flush操作,保證所有寫入Parent region的資料都能持久化。
- 5、在.split檔案夾下建立兩個region,稱之為daughter A、daughter B。
- 6、Daughter A、Daughter B拷貝到HBase根目錄下,形成兩個新的region。
- 7、Parent region通知修改.META.表後下線,不再提供服務。
- 8、Daughter A、Daughter B上線,開始向外提供服務。
- 9、如果開啟了balance_switch服務,split後的region将會被重新分布。
上面1 ~ 9就是region split的整個過程,split過程非常快,速度基本會在秒級内,那麼在這麼快的時間内,region中的資料怎麼被重新組織的?
其實,split隻是簡單的把region從邏輯上劃分成兩個,并沒有涉及到底層資料的重組,split完成後,Parent region并沒有被銷毀,隻是被做下線處理,不再對外部提供服務。而新産生的region Daughter A和Daughter B,内部的資料隻是簡單的到Parent region資料的索引,Parent region資料的清理在Daughter A和Daughter B進行major compact以後,發現已經沒有到其内部資料的索引後,Parent region才會被真正的清理。
HBase設計
HBase是一個分布式資料庫,其性能的好壞主要取決于内部表的設計和資源的配置設定是否合理。
Rowkey設計
rowkey是HBase實作分布式的基礎,HBase通過rowkey範圍劃分不同的region,分布式系統的基本要求就是在任何時候,系統的通路都不要出現明顯的熱點現象,是以rowkey的設計至關重要,一般我們建議rowkey的開始部分以hash或者MD5進行散列,盡量做到rowkey的頭部是均勻分布的。禁止采用時間、使用者id等明顯有分段現象的标志直接當作rowkey來使用。
列簇設計
HBase的表設計時,根據不同需求有不同選擇,需要做線上查詢的資料表,盡量不要設計多個列簇,我們知道,不同的列簇在存儲上是被分開的,多列簇設計會造成在資料查詢的時候讀取更多的檔案,進而消耗更多的I/O。
TTL設計
選擇合适的資料過期時間也是表設計中需要注意的一點,HBase中允許列簇定義資料過期時間,資料一旦超過過期時間,可以被major compact進行清理。大量無用曆史資料的殘餘,會造成region體積增大,影響查詢效率。
Region設計
一般地,region不宜設計成很大,除非應用對階段性性能要求很多,但是在将來運作一段時間可以接受停服處理。region過大會導緻major compact調用的周期變長,而單次major compact的時間也相應變長。major compact對底層I/O會造成壓力,長時間的compact操作可能會影響資料的flush,compact的周期變長會導緻許多删除或者過期的資料不能被及時清理,對資料的讀取速度等都有影響。
相反,小的region意味着major compact會相對頻繁,但是由于region比較小,major compact的相對時間較快,而且相對較多的major compact操作,會加速過期資料的清理。
當然,小region的設計意味着更多的region split風險,region容量過小,在資料量達到上限後,region需要進行split來拆分,其實split操作在整個HBase運作過程中,是被不怎麼希望出現的,因為一旦發生split,涉及到資料的重組,region的再配置設定等一系列問題。是以我們在設計之初就需要考慮到這些問題,盡量避免region的運作過程中發生split。
HBase可以通過在表建立的時候進行region的預配置設定來解決運作過程中region的split産生,在表設計的時候,預先配置設定足夠多的region數,在region達到上限前,至少有部分資料會過期,通過major compact進行清理後, region的資料量始終維持在一個平衡狀态。
region數量的設計還需要考慮記憶體上的限制,通過前面的介紹我們知道每個region都有memstore,memstore的數量與region數量和region下列簇的數量成正比,一個RS下memstore記憶體消耗
Memory = memstore大小 * region數量 * 列簇數量
如果不進行前期資料量估算和region的預配置設定,通過不斷的split産生新的region,容易導緻因為記憶體不足而出現OOM現象。
個人介紹:
高廣超:多年一線網際網路研發與架構設計經驗,擅長設計與落地高可用、高性能網際網路架構。
本文首發在
高廣超的簡書部落格轉載請注明!
image.png