背景
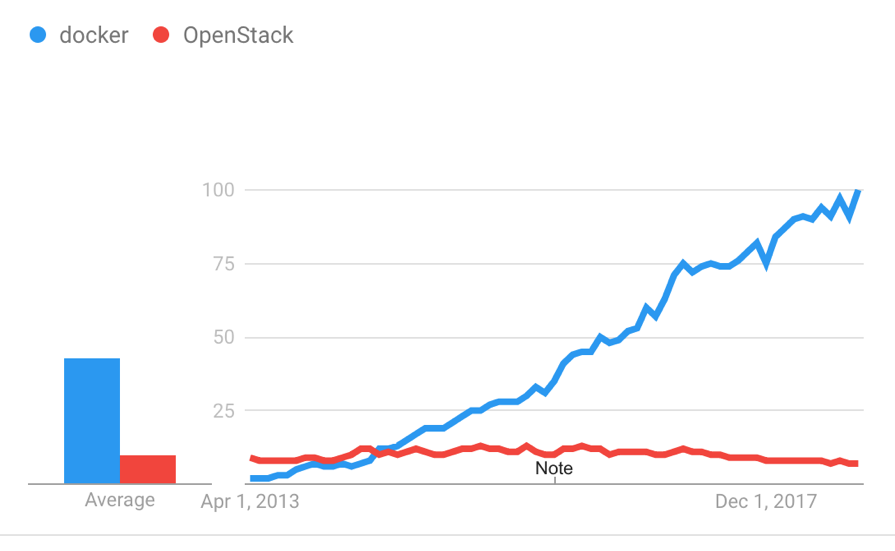
自 2013 年 dotCloud 公司開源 Docker 以來,以 Docker 為代表的容器産品憑借着隔離性好、可移植性高、資源占用少、啟動迅速等特性迅速風靡世界。下圖展示了 2013 年以來 Docker 和 OpenStack 的搜尋趨勢。
容器技術在部署、傳遞等環節給人們帶來了很多便捷,但在日志處理領域卻帶來了許多新的挑戰,包括:
- 如果把日志儲存在容器内部,它會随着容器的銷毀而被删除。由于容器的生命周期相對虛拟機大大縮短,建立銷毀屬于常态,是以需要一種方式持久化的儲存日志;
- 進入容器時代後,需要管理的目标對象遠多于虛拟機或實體機,登入到目标容器排查問題會變得更加複雜且不經濟;
- 容器的出現讓微服務更容易落地,它在給我們的系統帶來松耦合的同時引入了更多的元件。是以我們需要一種技術,它既能幫助我們全局性的了解系統運作情況,又能迅速定位問題現場、還原上下文。
日志處理流程
本文以 Docker 為例,依托阿裡雲日志服務團隊在日志領域深耕多年積累下的豐富經驗,介紹容器日志處理的一般方法和最佳實踐,包括:
- 容器日志實時采集;
- 查詢分析和可視化;
- 日志上下文分析;
- LiveTail - 雲上 tail -f。
容器日志實時采集
容器日志分類
采集日志首先要弄清日志存在的位置,這裡以 Nginx、Tomcat 這兩個常用容器為例進行分析。
Nginx 産生的日志包括 access.log 和 error.log,根據
nginx Dockerfile可知 access.log 和 error.log 被分别重定向到了 STDOUT 和 STDERR 上。
Tomcat 産生的日志比較多,包括 catalina.log、access.log、manager.log、host-manager.log 等,
tomcat Dockerfile并沒有将這些日志重定向到标準輸出,它們存在于容器内部。
容器産生的日志大部分都可以歸結于上述情形。這裡,我們不妨将容器日志分成以下兩類。
| 定義 | |
|---|---|
| 标準輸出 | 通過 STDOUT、STDERR 輸出的資訊,包括被重定向到标準輸出的文本檔案。 |
| 文本日志 | 存在于容器内部并且沒有被重定向到标準輸出的日志。 |
使用 logging driver
容器的标準輸出會由
logging driver統一處理。如下圖所示,不同的 logging driver 會将标準輸出寫往不同的目的地。

通過 logging driver 采集容器标準輸出的優勢在于使用簡單,例如:
# 該指令表示在 docker daemon 級别為所有容器配置 syslog 日志驅動
dockerd -–log-driver syslog –-log-opt syslog-address=udp://1.2.3.4:1111
# 該指令表示為目前容器配置 syslog 日志驅動
docker run -–log-driver syslog –-log-opt syslog-address=udp://1.2.3.4:1111 alpine echo hello world 缺點
除了 json-file 和 journald,使用其他 logging driver 将使 docker logs API 不可用。例如,當您使用
portainer管理主控端上的容器,并且使用了上述兩者之外的 logging driver,您會發現無法通過 UI 界面觀察到容器的标準輸出。
使用 docker logs API
對于那些使用預設 logging driver 的容器,我們可以通過向 docker daemon 發送
docker logs指令來擷取容器的标準輸出。使用此方式采集日志的工具包括
logspout、
sematext-agent-docker等。下列樣例中的指令表示擷取容器自
2018-01-01T15:00:00
以來最新的5條日志。
docker logs --since "2018-01-01T15:00:00" --tail 5 <container-id> 當日志量較大時,這種方式會對 docker daemon 造成較大壓力,導緻 docker daemon 無法及時響應建立容器、銷毀容器等指令。
采集 json-file 檔案
預設 logging driver 會将日志以 json 的格式寫入主控端檔案裡,檔案路徑為
/var/lib/docker/containers/<container-id>/<container-id>-json.log
。這樣可以通過直接采集主控端檔案來達到采集容器标準輸出的目的。
該方案較為推薦,因為它既不會使 docker logs API 變得不可用,又不會影響 docker daemon,并且現在許多工具原生支援采集主控端檔案,如
filebeat logtail等。
挂載主控端目錄
采集容器内文本日志最簡單的方法是在啟動容器時通過
bind mounts或
volumes方式将主控端目錄挂載到容器日志所在目錄上,如下圖所示。
針對 tomcat 容器的 access log,使用指令
docker run -it -v /tmp/app/vol1:/usr/local/tomcat/logs tomcat
将主控端目錄
/tmp/app/vol1
挂載到 access log 在容器中的目錄
/usr/local/tomcat/logs
上,通過采集主控端目錄
/tmp/app/vol1
下日志達到采集 tomcat access log 的目的。
計算容器 rootfs 挂載點
使用挂載主控端目錄的方式采集日志對應用會有一定的侵入性,因為它要求容器啟動的時候包含挂載指令。如果采集過程能對使用者透明那就太棒了。事實上,可以通過計算容器 rootfs 挂載點來達到這種目的。
和容器 rootfs 挂載點密不可分的一個概念是
storage driver。實際使用過程中,使用者往往會根據 linux 版本、檔案系統類型、容器讀寫情況等因素選擇合适的 storage driver。不同 storage driver 下,容器的 rootfs 挂載點遵循一定規律,是以我們可以根據 storage driver 的類型推斷出容器的 rootfs 挂載點,進而采集容器内部日志。下表展示了部分 storage dirver 的 rootfs 挂載點及其計算方法。
| Storage driver | rootfs 挂載點 | 計算方法 |
|---|---|---|
| aufs | /var/lib/docker/aufs/mnt/<id> | id 可以從如下檔案讀到。 |
| overlay | /var/lib/docker/overlay/<id>/merged | 完整路徑可以通過如下指令得到。 |
| overlay2 | /var/lib/docker/overlay2/<id>/merged | |
| devicemapper | /var/lib/docker/devicemapper/mnt/<id>/rootfs | id 可以通過如下指令得到。 |
Logtail 方案
在充分比較了容器日志的各種采集方法,綜合整理了廣大使用者的回報與訴求後,日志服務團隊推出了容器日志一站式解決方案。
功能特點
logtail 方案包含如下功能:
- 支援采集主控端檔案以及主控端上容器的日志(包括标準輸出和日志檔案);
- 支援容器自動發現,即當您配置了采集目标後,每當有符合條件的容器被建立時,該容器上的目标日志将被自動采集;
- 支援通過 docker label 以及環境變量過濾指定容器,支援白名單、黑名單機制;
- 采集資料自動打标,即對收集上來的日志自動加上 container name、container IP、檔案路徑等用于辨別資料源的資訊;
- 支援采集 K8s 容器日志。
核心優勢
- 通過 checkpoint 機制以及部署額外的監控程序保證 at-least-once 語義;
- 曆經多次雙十一、雙十二的考驗以及阿裡集團内部百萬級别的部署規模,穩定和性能方面非常有保障。
K8s 容器日志采集
和 K8s 生态深度內建,能非常友善地采集 K8s 容器日志是日志服務 logtail 方案的又一大特色。
采集配置管理:
- 支援通過 WEB 控制台進行采集配置管理;
- 支援通過 CRD(CustomResourceDefinition)方式進行采集配置管理(該方式更容易與 K8s 的部署、釋出流程進行內建)。
采集模式:
- 支援通過 DaemonSet 模式采集 K8s 容器日志,即每個節點上運作一個采集用戶端 logtail,适用于功能單一型的叢集;
- 支援通過 Sidecar 模式采集 K8s 容器日志,即每個 Pod 裡以容器的形式運作一個采集用戶端 logtail,适用于大型、混合型、PAAS 型叢集。
關于 Logtail 方案的詳細說明可參考文章
全面提升,阿裡雲Docker/Kubernetes(K8S) 日志解決方案與選型對比。
查詢分析和可視化
完成日志采集工作後,下一步需要對這些日志進行查詢分析和可視化。這裡以 Tomcat 通路日志為例,介紹日志服務提供的強大的查詢、分析、可視化功能。
快速查詢
容器日志被采集時會帶上 container name、container IP、目标檔案路徑等資訊,是以在查詢的時候可以通過這些資訊快速定位目标容器和檔案。查詢功能的詳細介紹可參考文檔
查詢文法實時分析
日志服務
功能相容 SQL 文法且提供了 200 多種聚合函數。如果您有使用 SQL 的經驗,能夠很容易寫出滿足業務需求的分析語句。例如:
- 統計通路次數排名前 10 的 uri。
* | SELECT request_uri, COUNT(*) as c GROUP by request_uri ORDER by c DESC LIMIT 10 - 統計目前15分鐘的網絡流量相對于前一個小時的變化情況。
* | SELECT diff[1] AS c1, diff[2] AS c2, round(diff[1] * 100.0 / diff[2] - 100.0, 2) AS c3 FROM (select compare( flow, 3600) AS diff from (select sum(body_bytes_sent) as flow from log)) 該語句使用
同比環比函數計算不同時間段的網絡流量。
可視化
為了讓資料更加生動,您可以使用日志服務内置的多種
圖表對 SQL 計算結果進行可視化展示,并将圖表組合成一個
儀表盤 下圖展示了基于 Tomcat 通路日志的儀表盤,它展示了錯誤請求率、網絡流量、狀态碼随時間的變化趨勢等資訊。該儀表盤展現的是多個 Tomcat 容器資料聚合後的結果,您可以使用
儀表盤過濾器功能,通過指定容器名檢視單個容器的資料。
日志上下文分析
查詢分析、儀表盤等功能能幫助我們把握全局資訊、了解系統整體運作情況,但定位具體問題往往需要上下文資訊的幫助。
上下文定義
上下文指的是圍繞某個問題展開的線索,如日志中某個錯誤的前後資訊。上下文包含兩個要素:
- 最小區分粒度:區分上下文的最小空間劃分,例如同一個線程、同一個檔案等。這一點在定位問題階段非常關鍵,因為它能夠使得我們在調查過程中避免很多幹擾。
- 保序:在最小區分粒度的前提下,資訊的呈現必須是嚴格有序的,即使一秒内有幾萬次操作。
下表展示了不同資料源的最小區分粒度。
| 分類 | 最小區分粒度 |
|---|---|
| 單機檔案 | IP + 檔案 |
| Docker 标準輸出 | Container + STDOUT/STDERR |
| Docker 檔案 | Container + 檔案 |
| K8s 容器标準輸出 | Namespace + Pod + Container + STDOUT/STDERR |
| K8s 容器檔案 | Namespace + Pod + Container + 檔案 |
| SDK | 線程 |
| Log Appender |
上下文查詢面臨的挑戰
在日志集中式存儲的背景下,采集端和服務端都很難保證日志原始的順序:
- 在用戶端層面,一台主控端上運作着多個容器,每個容器會有多個目标檔案需要采集。日志采集軟體需要利用機器的多個 cpu 核心解析、預處理日志,并通過多線程并發或者單線程異步回調的方式處理網絡發送的慢 IO 問題。這使得日志資料不能按照機器上的事件産生順序依次到達服務端。
- 在服務端層面,由于水準擴充的多機負載均衡架構,使得同一用戶端機器的日志會分散在多台存儲節點上。在分散存儲的日志基礎上再恢複最初的順序是困難的。
原理
日志服務通過給每條日志附加一些額外的資訊以及服務端的關鍵詞查詢能力巧妙地解決了上述難題。原理如下圖所示。
- 日志被采集時會自動加入用于辨別日志來源的資訊(即上文提到的最小區分粒度)作為 source_id。針對容器場景,這些資訊包括容器名、檔案路徑等;
- 日志服務的各種采集用戶端一般會選擇批量上傳日志,若幹條日志組成一個資料包。用戶端會向這些資料包裡寫入一個單調遞增的 package_id,并且包内每條日志都擁有包内位移 offset;
- 服務端會将 source_id、package_id、offset 組合起來作為一個字段并為其建立索引。這樣,即使各種日志在服務端是混合存儲的狀态,我們也可以根據 source_id、package_id、offset 精确定位某條日志。
想了解更多有關上下文分析的功能可參考文章
上下文查詢 分布式系統日志上下文查詢功能LiveTail - 雲上 tail -f
除了檢視日志的上下文資訊,有時我們也希望能夠持續觀察容器的輸出。
傳統方式
下表展示了傳統模式下實時監控容器日志的方法。
| 類别 | 步驟 |
|---|---|
| 1. 定位容器,擷取容器 id; 2. 使用指令 在終端上觀察輸出; 3. 使用 | |
進入容器; 3. 找到目标檔案,使用指令 觀察輸出; 4. 使用 |
痛點
通過傳統方法監控容器日志存在以下痛點:
- 容器很多時,定位目标容器耗時耗力;
- 不同類型的容器日志需要使用不同的觀察方法,增加使用成本;
- 關鍵資訊查詢展示不夠簡單直覺。
功能和原理
針對這些問題,日志服務推出了
LiveTail功能。相比傳統模式,它有如下優點:
- 可以根據單條日志或日志服務的查詢分析功能快速定位目标容器;
- 使用統一的方式觀察不同類型的容器日志,無需進入目标容器;
- 支援通過關鍵詞進行過濾;
- 支援設定關鍵列。
在實作上,LiveTail 主要用到了上一章中提到的上下文查詢原理快速定位目标容器和目标檔案。然後,用戶端定期向服務端發送請求,拉取最新資料。
視訊樣例
您還可以通過觀看視訊,進一步了解容器日志的采集、查詢、分析和可視化等功能。
參考資料
- LC3視角:Kubernetes下日志采集、存儲與處理技術實踐 - https://yq.aliyun.com/articles/606248
- 全面提升,阿裡雲Docker/Kubernetes(K8S) 日志解決方案與選型對比 - https://yq.aliyun.com/articles/448676
技術支援