還是和之前一樣,首先還是要明确一個問題——應用層是幹什麼的?
#應用層就是規定了各種應用程式之間如何交流,如何進行資料的傳遞
那現在回想一下,現在的上網是怎麼樣個流程?
在浏覽器的位址欄中輸入baidu.com就可以上網。那在回想我我們之前講過的IP位址,好像沒有出現過類似于這樣的。都是要知道一個主機的ip位址才可以進行接下來操作。那怎麼輸入baidu.com就可以上網呢?這就是我們接下來要說的DNS域名解析系統
DNS域名解析系統
說起來是很簡單的,那就是将類似于baidu.com轉化為ip位址。那它是怎麼解析的?
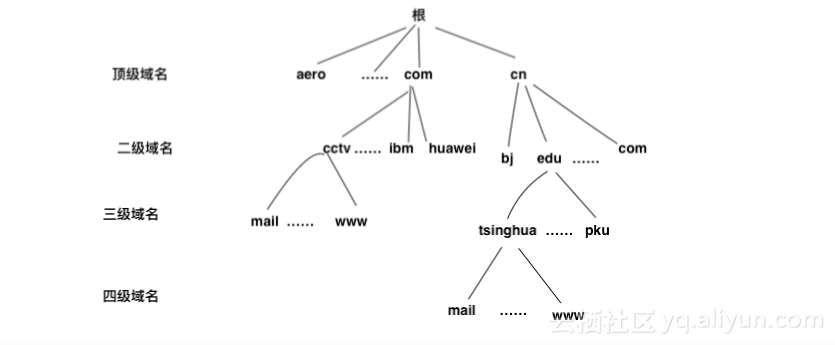
那先得從域名的構成說起。例如:www.baidu.com 。域名采用層次樹狀結構。以.分割,從右向左依次為頂級域名,二級域名,三級域名。這裡的域隻是一個可被管理的劃分區域,還可以繼續劃分為多個子域。但是域名說到底還人為劃分的,并不是實際存在的一塊地方,是以域是邏輯概念。
com就是頂級域名。
baidu就是二級域名
www就是三級域名。
DNS并不要求一個域名需要包含多少個下級域名,也不規定每一級的域名代表什麼意思。
頂級域名還可以分為國家級域名,通用頂級域名,基礎結構域名。
二級域名還可以分為類别域名和行政域名。
下面是域名樹來标示域名的結構
</br>
對應的解析域名的程式叫做**域名伺服器程式**,運作這段程式的機器叫做域名解析伺服器。
域名伺服器解析域名的方法是采用劃分區的方法來解析域名。所謂分區就是 并不是将所有的下一級的的域名全部都放到一個伺服器中,而是 劃分為好幾個區域,這樣做可以提高查詢效率。區(zone)就是一一個伺服器所負責管轄(或者有權限的)範圍。每個區還可以劃分為好幾個子區域,在這裡叫做域。其實這就是概念上的了解,整個網際網路都是采用分層的結構。不能讓一個伺服器頻繁的通路被通路,并且在它所管理的下一級域名還特别多 ,就好像一個公司,老闆不可能直接管理每個員工,是以就有部分經理來管理,有什麼問題再向老闆反應。同樣的,這裡也是這樣的道理,劃分區,在劃分域,每個域中都有一個伺服器,管理這個域 中的所有查詢,要是不知道就向上一級反應,也就是這區中的伺服器。
還有兩個概念明确zz -- 遞歸查詢(一般用于本地向本地的域名伺服器)-若是主機向本地的伺服器查詢,若是不知道,那本地的伺服器就以dns客戶的身份,向其他的根域名伺服器查詢,以此類推,直到有結果,并不是讓主機自己進行下一步的查詢。
疊代查詢(一般用于本地伺服器向根域名伺服器查詢),根域名伺服器收到本地伺服器的查詢封包後,有倆選擇,要不給出位址,要不告訴本地伺服器下一步應該向那個伺服器查詢。
其實。現在為了提高DNS的查詢效率,并且減輕根域名伺服器上的負荷,在域名伺服器中都使用了高速緩存來存放查詢過的資訊和結果況且,為了保證資訊的正确,高速緩存都為每個記錄都設定有效時間。 那回到我們之前的所講的。在上網的時候在浏覽器中輸入baidu.con就可以上上網,但是大家注意了嗎?一般在前面還是有www這三個字母的。那www是什麼?它是怎麼出現的?
www 網際網路(world wide web)
它并不是一種特殊的計算機網絡,而是一個大規模的。聯機式的資訊儲存所,它有連接配接的方法能友善的從網際網路上的一個站點到另一個 站點。它的出現使的網站的數量大規模增長,是網際網路發脹中一個十分重要的裡程碑。。
網際網路是一個分布式的超媒體的系統,是超文本的擴充,超文本就是裡面包含指向其他文本的連結文本。
它把大量的資訊分布在網際網路上,每個主機的文檔都可以獨立運作,一個文檔的變動是不可能通知到所有的使用者的。是以這就導緻了連結失效。它采用cs模型來工作,客戶請求,伺服器響應一個網際網路的文檔
(1)那怎麼來表示一個網際網路文檔?
(2)怎麼來标示一個文檔?
(3)客戶發出的請求是那種格式,伺服器傳回的又是什麼格式?
依次來解答——如下
(1) html語言來表示,在w3c的官方上面有學習資料
(2) URL(uniform resource locator)來标示。格式如下:
<協定>://<主機>:<端口>/<路徑>
一般來說,協定預設是http端口是80,一般都是先通路一個網站的首頁,就可以通過不同的連結查找不想要的東西。
(3)http(s)協定
http是基于tcp連結的 ,它就是規定了怎麼樣向伺服器請求文檔一個伺服器怎麼回送文檔。是以它是面向事務的。它是基于tcp連結的,是以傳送的資料是可靠和安全,完整的,但是同時協定本身是無連接配接的,就是在使用http協定的兩方在通信之前并不要求倆方要建立http連接配接
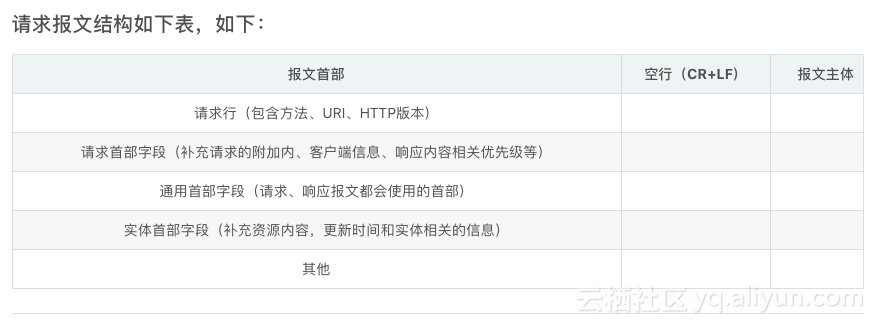
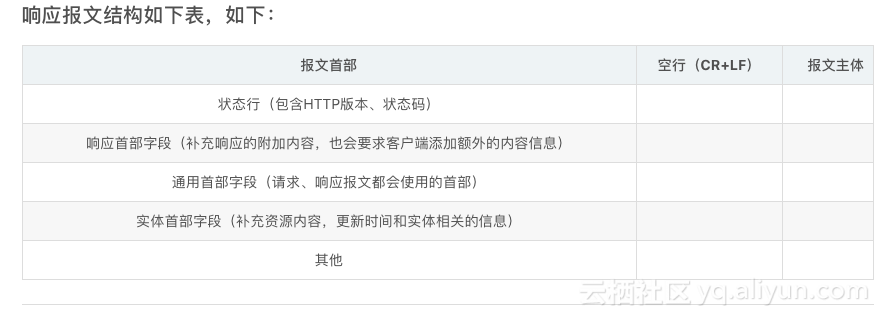
http的封包結構。
有兩種封包 請求封包 和響應封包
a:請求封包(客戶機向伺服器發送請求)
b:響應封包(伺服器給客戶急的回應)
倆個封包大體都分為
開始行:用來差別到底是請求封包還是響應封包
首部行:用來說明浏覽器,伺服器或者封包的一些資訊,可以有好幾行,也可以沒有。
主體:在請求封包中可以沒有,在響應中也可能沒有
下面是一個http請求封包的例子:
GET /dir/index.html HTTP/1.1 相對路徑的URL
Host: www.kaleidoscope.cn 首部的開始行。給出主機的域名
Connection :close 告訴伺服器發送完請求後關閉連接配接
User-Agent: Mozilla/5.0 表示使用者代理使用的firefox
Accept-Language: cn 表示使用者希望優先得到中文版
響應封包的狀态行中的狀态碼有五大類
1XX 表示通知資訊,
2XX 表示成功
3XX 表示重定向 如要晚上請求還要采取的方法
4XX 表示客戶的差錯
5XX 表示伺服器的差錯
那http是怎麼工作的呢?
每一個網際網路網店都有一個伺服器程序,它不斷的監聽TCP的80端口,如是發現有使用者的請求,經過tcp的三次握手中的前兩次後,之後第三次發送http封包,建tcp連接配接;浏覽器就可以向網際網路發送要浏覽某個連結頁面的請求,伺服器就響應請求,并且傳回。最後釋放tcp連接配接。 那之前所講的http是無狀态的,什麼是無狀态呢。并不會記錄目前通路者的資訊。那麼我們在雲栖社群上面怎麼有自己的首頁這些隻屬于自己的資訊呢,伺服器是怎麼知道目前的通路者是你呢?
這中就有一個叫做**cookie**的東西。表示http伺服器和客戶機時間傳遞的狀态資訊。當使用者在浏覽這個雲栖網站時,該網站的伺服器就會為這個使用者産生一個唯一的表示碼,用來表示這個使用者,并且在給使用者的響應封包中有一個叫做set-cookie的字段後,填上标示碼。當浏覽器收到這個後,就在其管理的cookie檔案中添加這個伺服器的主機名和标示碼,當使用者下次浏覽這個網站的時候,就把這個cookie發送給伺服器,伺服器就知道是這個使用者來通路了,那就可以在資料庫中将這個使用者的資訊查找出來。
上面所講的還是靜态網站 靜态網站就是内容是不能及時自動更改,要更改就要創作者要更改在伺服器中的文檔。那這個肯定是不可以的。這就有了動态網站(動态網際網路文檔)。動态網站是值文檔的内容是有浏覽器通路伺服器的時候才有應用程式來建立的,那當浏覽器的請求到達的時候,就需要一段程式,來處理結果,并生成文檔 随後伺服器傳回這個頁面并且應該一套規則來規定,浏覽器發來的資料是要怎麼給這段程式,伺服器怎麼處理這段程式的輸出結果。以及輸出結果應該怎麼使用
這個機制叫做通用網關接口CGI(Common Gateway Interface),叫做網關是因為這段程式在運作的時候還可能通路别的程式和伺服器資源,資料庫, CGI程式的叫做CGI腳本。
随着技術的發脹,上面已經不能滿足了,新的問題又出現了。動态網際網路文檔一旦建立就不能變化了,就不能更改了,比如我要點選一個某個圖像然後要觀察它的動畫效果,之前的就不能滿足了。那新的技術出現了叫做**活動網際網路文檔** 有兩種技術來進行浏覽器螢幕顯示的連續更新
(a) 伺服器推送 ,就是建立tcp連接配接後不釋放連接配接,伺服器一直推送消息來更新。這樣做會一直占用資源
(b)活動文檔(active document)這種技術就是把更新的技術給浏覽器,在傳回的文檔中傳回一段内嵌代碼的HTML,這是,活動文檔就可以動态更新。 在繼續回想。我們在百度搜尋的時候是怎麼找的呢?
這種搜尋工具叫做搜尋引擎,大體上搜尋方式可以分為兩種,
(a)全文檢索,通過一段程式在網際網路上收集資訊,然後建立一個很大的索引關系庫,使用者輸入關鍵字,程式就在已經建立的資料庫中查詢,這種資料庫并不是在查詢的時候建立的,是以這中查詢的結果并不是及時的。是以要對資料庫進行更新
(b) 分類目錄
根據網站送出的關鍵字,通過人工稽核後,輸入到對應的分類的資料庫中,這樣做的好處是使用者可根據網站設計号的目錄有針對性的查詢,但是分類查詢的并不是内容,而是某個網站的URL。
新生的搜尋技術
(a)垂直搜尋引擎 。為某一特定領域的人提供查詢服務
(b)元搜尋引擎:就是搜尋引擎的搜尋引擎,它把使用者送出的查詢送出給多個獨立的搜尋引擎上去 行了,網際網路的就說完了
檔案傳輸協定
檔案傳送協定FTP(file transfer protocol)提供互動式的通路允許使用者指明檔案的類型,檔案的權限
需要講明的是ftp并不是網際網路的部分。是個獨立的類型
檔案共享有倆種類型
(a):FTP ——基于tcp ,這種通路首先是無差錯的,倆計算機之間進行檔案的通路,是很複雜的事情,因為倆計算機的存儲格式,檔案系統,目錄結構……都是不相同的。是以FTP做的就是盡可能的消除這種差錯,FTP使用cs模型,一個ftp伺服器同時為多個使用者提供服務,是以,伺服器有兩大部分組成,一個是主程序(建立程序) 一個是交流程序(傳送資料),主要的操作如下:
使用者先伺服器發出連接配接的請求的時候。尋找21端口,同時還要告訴伺服器自己的另一個端口号碼。用來傳送資料,伺服器上的和使用者建立一個傳送資料的程序通過之前告訴的另一個端口号來進行資料的交流。主程序則繼續監聽21端口。
(b):TFTP ——基于UDP 當然這種通路時很小的,因為沒有tcp那樣麻煩,TFTP隻支援資料的傳輸而不是互動,可以同時向許多機器傳輸資料。
他們的共同目的就是複制整個檔案,特點是想要存取一個檔案,那就要先獲得一個本地的檔案副本,要是想要修改檔案,那就要先對檔案的副本修改,然後回傳到原來結點。 #遠端終端協定
TELNET協定現在用的少了,但是原理還是要講一講
這種協定并不複雜,目的就是消除作業系統之間的差異。使用者用這個協定就可連接配接到遠端的主機。 原理就是将資料轉換為一種NVT的資料格式,進行傳輸,然後在另一個主機上解析就好。 電子郵件
大家想想現實中的快遞時怎麼郵寄的,假設a給b要寄快遞,那得到快遞站然後郵寄,然後通過快遞公司到b的地方,然後那個快遞站給b發送消息,b有時間了就去快遞站去拿快遞。
那在電子郵件中基本時這樣的道理。
如下圖所示:


基本的流程就是
1.發件人通過使用者代理寫郵件,點選發送
2.使用者代理使用SMTP協定發送給發送方郵件伺服器,
3.發送方郵件伺服器的SMTP協定與接收方的郵件伺服器 的SMTP伺服器建立TCP連接配接,然後把在緩存隊列中的郵件全部發送出去。接收方接受
4.接收方的郵件伺服器就将郵件放在收件人的信箱裡,等待收件人來取
5。收件人在打算收信時,就使用計算機中的使用者代理,在用POP3(或者IMAP)協定讀取。
電子信箱的位址如下:
使用者名@ 郵件伺服器的域名
POP3的協定的缺點在于,如果使用者從伺服器中讀取了信件,那就删除。假如一個使用者在桌上型電腦上讀取了信件,那在沒有備份的情況下,在筆記本上就沒有這份信件,這樣是不友善的
IMAP協定,使用者在自己的計算機上就可以操控郵件伺服器的郵箱,就想在本地操作一樣。是以它一個聯機協定,當使用者打開時 看到的是郵箱的首部,若要是打開某個郵件時,這個郵件才能打開。缺點是,要是沒有下載下傳在本地那本地就沒有。 最後在無聊一下 寫一寫P2P應用。
p2p就是沒有絕對的伺服器,大家都是伺服器,同時大家也都是客戶機。大多數的互動都是使用對等方式進行的
介紹兩種p2p的方式
(a)集中目錄伺服器的p2p的工作方式
有名的就是Napster ,原理就是有一個集中管理的目錄伺服器,裡面記錄着那個使用者有那些檔案,它要求安裝了Napster的計算機,都要想伺服器報告自己有什麼東西。當某個檔案想要查詢什麼的時候,就想去問問目錄伺服器這個東西在哪裡,然後去對應的位置去下載下傳。
(b)全分布式結構的p2p檔案共享程式
使用洪泛法查詢。把計算機這種的連接配接必做洪流,每個計算機都可以加入這個洪流,也可以自願的退出,當每個計算機加入的時候都要向一個基礎設施結點(追蹤器)報告自己加入洪流,并且洪流中的每個裝置都要隔一段時間要向其報告自己還在洪流中,追蹤器就随機的從參與的計算機中選擇若幹個,并告訴對方的ip位址,也是a就和這些建立連接配接(這些叫做對等方),就可以交流資料。因為一個對等方可能隻是擁有這個檔案的一個檔案塊子集,是以要對等方将檔案塊清單發過來嗎,比對,看自己少什麼就讓他發送什麼東西來。
那a就要決定哪些檔案要傳過來?先和對等方中的誰進行通行,先寵幸誰呢?
第一個問題解決是采用了最稀有優先的技術,就先和擁有a缺少的檔案的對等方少的通信。比如a缺少的1和2這倆個檔案,有這個檔案的對等方很多,那就不急,有2這個檔案的對等方很少,那就要先和這些通行
第二個問題的算法思想就是:凡事最高資料率向a發送資料的對等方,就先通信。具體就是a會持續的測量相鄰對等方接受資料的資料率,并且确定最高的4個,接着就發送資料給這4個,每隔十秒鐘就要重新測量,然後可能修改這4個,并且a每隔三十秒鐘,就要随機的找一個另外的相鄰對等方b,并發送資料,這樣,a有可能成為b的前四個上傳檔案的提供者,并且b也有可能向a發送檔案。那b也有可能成為a的四個檔案的提供者,這樣這些對等方互相之間都能夠令人滿意的速率交換檔案塊。