1.文檔編寫目的
HBase是一款基于Hadoop的Key-Value資料庫,提供了對HDFS上資料的高效随機讀寫服務,填補了Hadoop MapReduce批處理的缺陷,但HBase作為列簇資料庫無法輕易的建立“二級索引”、難以執行求和、計數、排序等操作。在HBase0.96版本後引入了協處理器(Coprocessor),使用者可以編寫運作在HBase Server端的代碼。HBase支援兩種類型的協處理器,Endpoint和Observer。
Endpoint協處理器類似傳統資料庫中的存儲過程,用戶端可以調用這些Endpoint協處理器執行一段Server端代碼,并将Server端代碼的結果傳回給用戶端處理。
Observer Coprocessor,這中協處理器類似于傳統資料庫中的觸發器,當發生某些事件的時候,Observer協處理器會被Server端調用。
本篇文章先不介紹如何去開發協處理器,主要借助于HBase示例中自帶的RowCount Endpoint協處理器來說明如何使用Java代碼在用戶端調用。在後面的文章Fayson會介紹如何去編寫一個協處理器。
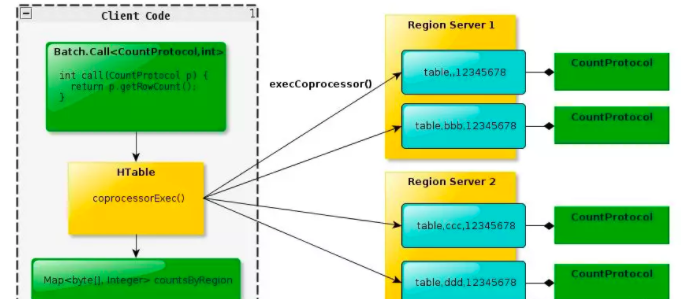
Endpoint Coprocessor用戶端調用過程,如下圖所示:
- 内容概述
1.環境準備
2.編寫Java示例代碼及運作
3.統計方式對比
- 測試環境
1.CM和CDH版本為5.14.3
2.環境準備
HBase中自帶的Endpoint的協處理器,在hbase-examples.jar包中,在CDH的/opt/cloudera/parcels/CDH/lib/hbase/lib目錄下,如下圖所示:
1.确認hbase-examples-1.2.0-cdh5.14.2.jar是否在

注意:在這裡的配置為全局配置,協處理器有兩種使用方式上圖的方式是其中的一種,另外一種則是對單個表進行修改。
3.編寫Java示例
1.建立HBase的Maven工程
2.工程的pom.xml檔案内容如下
3.編寫CoprocessorExample.java類,内容如下
4.示例代碼運作
4.HBase表統計效率對比
1.使用HBase的count來統計測試表的總條數
2.使用HBase提供的MapReduce方式統計測試表的總條數
執行耗時:14.12s
耗時統計:
5.總結
- 在使用HBase的coprocessor方法是如果傳入startkey和endkey是會根據rowkey的通路檢索出符合條件的region并統計每個region上資料量。
- HBase的Endpoint Coprocessor協處理器可以通過CM的方式配置全局的也可以通過用戶端或hbase shell的方式來指定某一個表使用比較靈活,在後面的文章Fayson會介紹如何指定單個表的方式。
GitHub位址:
https://github.com/fayson/cdhproject/blob/master/hbasedemo/src/main/java/com/cloudera/hbase/coprocessor/CoprocessorExample.java
大家工作學習遇到HBase技術問題,把問題釋出到HBase技術社群論壇http://hbase.group,歡迎大家論壇上面提問留言讨論。想了解更多HBase技術關注HBase技術社群公衆号(微信号:hbasegroup),非常歡迎大家積極投稿。
HBase技術交流社群 - 阿裡官方“HBase生态+Spark社群大群”點選加入:
https://dwz.cn/Fvqv066s