所謂
網頁抓取,就是把URL位址中指定的網絡資源從網絡流中讀取出來,儲存到本地。 類似于使用程式模拟IE浏覽器的功能,把URL作為HTTP請求的内容發送到伺服器端, 然後讀取伺服器端的響應資源。
一、通過urllib2抓取百度網頁在Python中,我們使用urllib2這個元件來抓取網頁。urllib2是Python的一個擷取URLs(Uniform Resource Locators)的元件。它以urlopen函數的形式提供了一個非常簡單的接口。最簡單的urllib2的應用代碼隻需要四行。
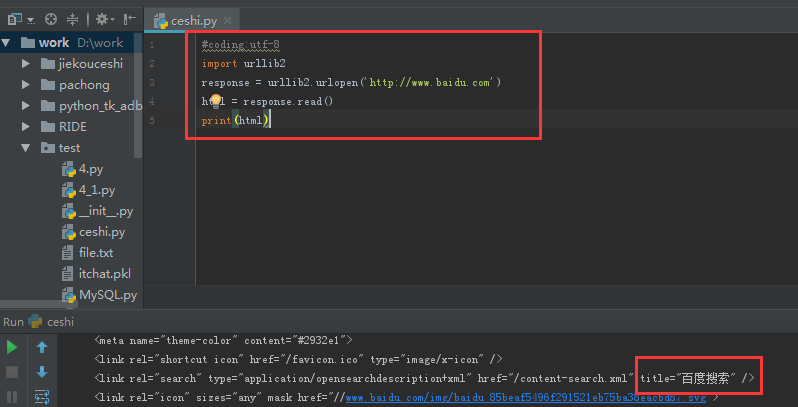
urllib2抓取百度網頁
我們通過浏覽器可以打開百度首頁,右擊,選擇檢視源代碼(火狐OR谷歌浏覽器均可),會發現也是完全一樣的内容。也就是說,上面這四行代碼将我們通路百度時浏覽器收到的代碼們全部列印了出來。這就是一個最簡單的urllib2的例子。
當然,除了"http:",URL同樣可以使用"ftp:","file:"等等來替代。HTTP是基于請求和應答機制的:用戶端提出請求,服務端提供應答。
二、urllib結合Request用法urllib2用一個Request對象來映射你提出的HTTP請求。在它最簡單的使用形式中你将用你要請求的位址建立一個Request對象,通過調用urlopen并傳入Request對象,将傳回一個相關請求response對象,這個應答對象如同一個檔案對象,是以你可以在Response中調用.read()用戶端提出請求,服務端提供應答。

urllib+Request用法
可以看到,以上兩種用法的輸出結果都是一緻的。
三、HTTP請求的同時傳入參數data設定Headers到http請求
有一些網站不喜歡被程式(非人為通路)通路,或者發送不同版本的内容到不同的浏覽器。預設的urllib2把自己作為“Python-urllib/x.y”(x和y是Python主版本和次版本号,例如Python-urllib/2.7),浏覽器确認自己身份是通過User-Agent頭,當你建立了一個請求對象,你可以給他一個包含頭資料的字典。
Headers請求HTTP