版權聲明:本文為部落客原創文章,未經部落客允許不得轉載。 https://blog.csdn.net/qq_34173549/article/details/81047181
Java集合類: Set、List、Map、Queue使用場景梳理
本文主要關注Java程式設計中涉及到的各種集合類,以及它們的使用場景
相關學習資料
http://files.cnblogs.com/LittleHann/java%E9%9B%86%E5%90%88%E6%8E%92%E5%BA%8F%E5%8F%8Ajava%E9%9B%86%E5%90%88%E7%B1%BB%E8%AF%A6%E8%A7%A3%28collection%E3%80%81list%E3%80%81map%E3%80%81set%29.rar
http://blog.sina.com.cn/s/blog_a345a8960101k9vx.html
http://f51889920.iteye.com/blog/1884810 目錄
1. Java集合類基本概念
2. Java集合類架構層次關系
3. Java集合類的應用場景代碼 1. Java集合類基本概念
在程式設計中,常常需要集中存放多個資料。從傳統意義上講,數組是我們的一個很好的選擇,前提是我們事先已經明确知道我們将要儲存的對象的數量。一旦在數組初始化時指定了這個數組長度,這個數組長度就是不可變的,如果我們需要儲存一個可以動态增長的資料(在編譯時無法确定具體的數量),java的集合類就是一個很好的設計方案了。
集合類主要負責儲存、盛裝其他資料,是以集合類也被稱為容器類。是以的集合類都位于java.util包下,後來為了處理多線程環境下的并發安全問題,java5還在java.util.concurrent包下提供了一些多線程支援的集合類。
在學習Java中的集合類的API、程式設計原理的時候,我們一定要明白,"集合"是一個很古老的數學概念,它遠遠早于Java的出現。從數學概念的角度來了解集合能幫助我們更好的了解程式設計中什麼時候該使用什麼類型的集合類。
Java容器類類庫的用途是"儲存對象",并将其劃分為兩個不同的概念:
1) Collection
一組"對立"的元素,通常這些元素都服從某種規則
1.1) List必須保持元素特定的順序
1.2) Set不能有重複元素
1.3) Queue保持一個隊列(先進先出)的順序
2) Map
一組成對的"鍵值對"對象 Collection和Map的差別在于容器中每個位置儲存的元素個數:
1) Collection 每個位置隻能儲存一個元素(對象)
2) Map儲存的是"鍵值對",就像一個小型資料庫。我們可以通過"鍵"找到該鍵對應的"值" 2. Java集合類架構層次關系
1. Interface Iterable
疊代器接口,這是Collection類的父接口。實作這個Iterable接口的對象允許使用foreach進行周遊,也就是說,所有的Collection集合對象都具有"foreach可周遊性"。這個Iterable接口隻
有一個方法: iterator()。它傳回一個代表目前集合對象的泛型<T>疊代器,用于之後的周遊操作
1.1 Collection
Collection是最基本的集合接口,一個Collection代表一組Object的集合,這些Object被稱作Collection的元素。Collection是一個接口,用以提供規範定義,不能被執行個體化使用
1) Set
Set集合類似于一個罐子,"丢進"Set集合裡的多個對象之間沒有明顯的順序。Set繼承自Collection接口,不能包含有重複元素(記住,這是整個Set類層次的共有屬性)。
Set判斷兩個對象相同不是使用"=="運算符,而是根據equals方法。也就是說,我們在加入一個新元素的時候,如果這個新元素對象和Set中已有對象進行注意equals比較都傳回false,
則Set就會接受這個新元素對象,否則拒絕。
因為Set的這個制約,在使用Set集合的時候,應該注意兩點:1) 為Set集合裡的元素的實作類實作一個有效的equals(Object)方法、2) 對Set的構造函數,傳入的Collection參數不能包
含重複的元素
1.1) HashSet
HashSet是Set接口的典型實作,HashSet使用HASH算法來存儲集合中的元素,是以具有良好的存取和查找性能。當向HashSet集合中存入一個元素時,HashSet會調用該對象的
hashCode()方法來得到該對象的hashCode值,然後根據該HashCode值決定該對象在HashSet中的存儲位置。
值得主要的是,HashSet集合判斷兩個元素相等的标準是兩個對象通過equals()方法比較相等,并且兩個對象的hashCode()方法的傳回值相等
1.1.1) LinkedHashSet
LinkedHashSet集合也是根據元素的hashCode值來決定元素的存儲位置,但和HashSet不同的是,它同時使用連結清單維護元素的次序,這樣使得元素看起來是以插入的順序儲存的。
當周遊LinkedHashSet集合裡的元素時,LinkedHashSet将會按元素的添加順序來通路集合裡的元素。
LinkedHashSet需要維護元素的插入順序,是以性能略低于HashSet的性能,但在疊代通路Set裡的全部元素時(周遊)将有很好的性能(連結清單很适合進行周遊)
1.2) SortedSet
此接口主要用于排序操作,即實作此接口的子類都屬于排序的子類
1.2.1) TreeSet
TreeSet是SortedSet接口的實作類,TreeSet可以確定集合元素處于排序狀态
1.3) EnumSet
EnumSet是一個專門為枚舉類設計的集合類,EnumSet中所有元素都必須是指定枚舉類型的枚舉值,該枚舉類型在建立EnumSet時顯式、或隐式地指定。EnumSet的集合元素也是有序的,
它們以枚舉值在Enum類内的定義順序來決定集合元素的順序
2) List
List集合代表一個元素有序、可重複的集合,集合中每個元素都有其對應的順序索引。List集合允許加入重複元素,因為它可以通過索引來通路指定位置的集合元素。List集合預設按元素
的添加順序設定元素的索引
2.1) ArrayList
ArrayList是基于數組實作的List類,它封裝了一個動态的增長的、允許再配置設定的Object[]數組。
2.2) Vector
Vector和ArrayList在用法上幾乎完全相同,但由于Vector是一個古老的集合,是以Vector提供了一些方法名很長的方法,但随着JDK1.2以後,java提供了系統的集合架構,就将
Vector改為實作List接口,統一歸入集合架構體系中
2.2.1) Stack
Stack是Vector提供的一個子類,用于模拟"棧"這種資料結構(LIFO後進先出)
2.3) LinkedList
implements List<E>, Deque<E>。實作List接口,能對它進行隊列操作,即可以根據索引來随機通路集合中的元素。同時它還實作Deque接口,即能将LinkedList當作雙端隊列
使用。自然也可以被當作"棧來使用"
3) Queue
Queue用于模拟"隊列"這種資料結構(先進先出 FIFO)。隊列的頭部儲存着隊列中存放時間最長的元素,隊列的尾部儲存着隊列中存放時間最短的元素。新元素插入(offer)到隊列的尾部,
通路元素(poll)操作會傳回隊列頭部的元素,隊列不允許随機通路隊列中的元素。結合生活中常見的排隊就會很好了解這個概念
3.1) PriorityQueue
PriorityQueue并不是一個比較标準的隊列實作,PriorityQueue儲存隊列元素的順序并不是按照加入隊列的順序,而是按照隊列元素的大小進行重新排序,這點從它的類名也可以
看出來
3.2) Deque
Deque接口代表一個"雙端隊列",雙端隊列可以同時從兩端來添加、删除元素,是以Deque的實作類既可以當成隊列使用、也可以當成棧使用
3.2.1) ArrayDeque
是一個基于數組的雙端隊列,和ArrayList類似,它們的底層都采用一個動态的、可重配置設定的Object[]數組來存儲集合元素,當集合元素超出該數組的容量時,系統會在底層重
新配置設定一個Object[]數組來存儲集合元素
3.2.2) LinkedList
1.2 Map
Map用于儲存具有"映射關系"的資料,是以Map集合裡儲存着兩組值,一組值用于儲存Map裡的key,另外一組值用于儲存Map裡的value。key和value都可以是任何引用類型的資料。Map的key不允
許重複,即同一個Map對象的任何兩個key通過equals方法比較結果總是傳回false。
關于Map,我們要從代碼複用的角度去了解,java是先實作了Map,然後通過包裝了一個所有value都為null的Map就實作了Set集合
Map的這些實作類和子接口中key集的存儲形式和Set集合完全相同(即key不能重複)
Map的這些實作類和子接口中value集的存儲形式和List非常類似(即value可以重複、根據索引來查找)
1) HashMap
和HashSet集合不能保證元素的順序一樣,HashMap也不能保證key-value對的順序。并且類似于HashSet判斷兩個key是否相等的标準也是: 兩個key通過equals()方法比較傳回true、
同時兩個key的hashCode值也必須相等
1.1) LinkedHashMap
LinkedHashMap也使用雙向連結清單來維護key-value對的次序,該連結清單負責維護Map的疊代順序,與key-value對的插入順序一緻(注意和TreeMap對所有的key-value進行排序進行區
分)
2) Hashtable
是一個古老的Map實作類
2.1) Properties
Properties對象在處理屬性檔案時特别友善(windows平台上的.ini檔案),Properties類可以把Map對象和屬性檔案關聯起來,進而可以把Map對象中的key-value對寫入到屬性文
件中,也可以把屬性檔案中的"屬性名-屬性值"加載到Map對象中
3) SortedMap
正如Set接口派生出SortedSet子接口,SortedSet接口有一個TreeSet實作類一樣,Map接口也派生出一個SortedMap子接口,SortedMap接口也有一個TreeMap實作類
3.1) TreeMap
TreeMap就是一個紅黑樹資料結構,每個key-value對即作為紅黑樹的一個節點。TreeMap存儲key-value對(節點)時,需要根據key對節點進行排序。TreeMap可以保證所有的
key-value對處于有序狀态。同樣,TreeMap也有兩種排序方式: 自然排序、定制排序
4) WeakHashMap
WeakHashMap與HashMap的用法基本相似。差別在于,HashMap的key保留了對實際對象的"強引用",這意味着隻要該HashMap對象不被銷毀,該HashMap所引用的對象就不會被垃圾回收。
但WeakHashMap的key隻保留了對實際對象的弱引用,這意味着如果WeakHashMap對象的key所引用的對象沒有被其他強引用變量所引用,則這些key所引用的對象可能被垃圾回收,當垃
圾回收了該key所對應的實際對象之後,WeakHashMap也可能自動删除這些key所對應的key-value對
5) IdentityHashMap
IdentityHashMap的實作機制與HashMap基本相似,在IdentityHashMap中,當且僅當兩個key嚴格相等(key1 == key2)時,IdentityHashMap才認為兩個key相等
6) EnumMap
EnumMap是一個與枚舉類一起使用的Map實作,EnumMap中的所有key都必須是單個枚舉類的枚舉值。建立EnumMap時必須顯式或隐式指定它對應的枚舉類。EnumMap根據key的自然順序
(即枚舉值在枚舉類中的定義順序) 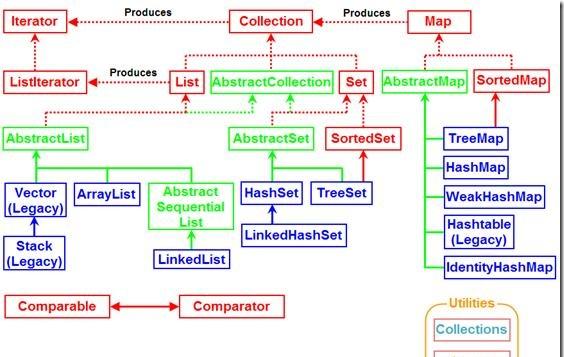
3. Java集合類的應用場景代碼
學習了集合類的基本架構架構之後,我們接着來學習它們各自的應用場景、以及細節處的注意事項
0x1: Set
HashSet
import java.util.*;
//類A的equals方法總是傳回true,但沒有重寫其hashCode()方法。不能保證目前對象是HashSet中的唯一對象
class A
{
public boolean equals(Object obj)
{
return true;
}
}
//類B的hashCode()方法總是傳回1,但沒有重寫其equals()方法。不能保證目前對象是HashSet中的唯一對象
class B
{
public int hashCode()
{
return 1;
}
}
//類C的hashCode()方法總是傳回2,且有重寫其equals()方法
class C
{
public int hashCode()
{
return 2;
}
public boolean equals(Object obj)
{
return true;
}
}
public class HashSetTest
{
public static void main(String[] args)
{
HashSet books = new HashSet();
//分别向books集合中添加兩個A對象,兩個B對象,兩個C對象
books.add(new A());
books.add(new A());
books.add(new B());
books.add(new B());
books.add(new C());
books.add(new C());
System.out.println(books);
}
} result:
[B@1, B@1, C@2, A@3bc257, A@785d65] 可以看到,如果兩個對象通過equals()方法比較傳回true,但這兩個對象的hashCode()方法傳回不同的hashCode值時,這将導緻HashSet會把這兩個對象儲存在Hash表的不同位置,進而使對象可以添加成功,這就與Set集合的規則有些出入了。是以,我們要明确的是: equals()決定是否可以加入HashSet、而hashCode()決定存放的位置,它們兩者必須同時滿足才能允許一個新元素加入HashSet
但是要注意的是: 如果兩個對象的hashCode相同,但是它們的equlas傳回值不同,HashSet會在這個位置用鍊式結構來儲存多個對象。而HashSet通路集合元素時也是根據元素的HashCode值來快速定位的,這種鍊式結構會導緻性能下降。
是以如果需要把某個類的對象儲存到HashSet集合中,我們在重寫這個類的equlas()方法和hashCode()方法時,應該盡量保證兩個對象通過equals()方法比較傳回true時,它們的hashCode()方法傳回值也相等
LinkedHashSet
import java.util.*;
public class LinkedHashSetTest
{
public static void main(String[] args)
{
LinkedHashSet books = new LinkedHashSet();
books.add("Java");
books.add("LittleHann");
System.out.println(books);
//删除 Java
books.remove("Java");
//重新添加 Java
books.add("Java");
System.out.println(books);
}
} 元素的順序總是與添加順序一緻,同時要明白的是,LinkedHashSetTest是HashSet的子類,是以它不允許集合元素重複
TreeSet
import java.util.*;
public class TreeSetTest
{
public static void main(String[] args)
{
TreeSet nums = new TreeSet();
//向TreeSet中添加四個Integer對象
nums.add(5);
nums.add(2);
nums.add(10);
nums.add(-9);
//輸出集合元素,看到集合元素已經處于排序狀态
System.out.println(nums);
//輸出集合裡的第一個元素
System.out.println(nums.first());
//輸出集合裡的最後一個元素
System.out.println(nums.last());
//傳回小于4的子集,不包含4
System.out.println(nums.headSet(4));
//傳回大于5的子集,如果Set中包含5,子集中還包含5
System.out.println(nums.tailSet(5));
//傳回大于等于-3,小于4的子集。
System.out.println(nums.subSet(-3 , 4));
}
} 與HashSet集合采用hash算法來決定元素的存儲位置不同,TreeSet采用紅黑樹的資料結構來存儲集合元素。TreeSet支援兩種排序方式: 自然排序、定制排序
1. 自然排序:
TreeSet會調用集合元素的compareTo(Object obj)方法來比較元素之間的大小關系,然後将集合元素按升序排序,即自然排序。如果試圖把一個對象添加到TreeSet時,則該對象的類必須實作Comparable接口,否則程式會抛出異常。
當把一個對象加入TreeSet集合中時,TreeSet會調用該對象的compareTo(Object obj)方法與容器中的其他對象比較大小,然後根據紅黑樹結構找到它的存儲位置。如果兩個對象通過compareTo(Object obj)方法比較相等,新對象将無法添加到TreeSet集合中(牢記Set是不允許重複的概念)。
注意: 當需要把一個對象放入TreeSet中,重寫該對象對應類的equals()方法時,應該保證該方法與compareTo(Object obj)方法有一緻的結果,即如果兩個對象通過equals()方法比較傳回true時,這兩個對象通過compareTo(Object obj)方法比較結果應該也為0(即相等)
看到這裡,我們應該明白:
1) 對與Set來說,它定義了equals()為唯一性判斷的标準,而對于到了具體的實作,HashSet、TreeSet來說,它們又會有自己特有的唯一性判斷标準,隻有同時滿足了才能判定為唯一性
2) 我們在操作這些集合類的時候,對和唯一性判斷有關的函數重寫要重點關注 2. 定制排序
TreeSet的自然排序是根據集合元素的大小,TreeSet将它們以升序排序。如果我們需要實作定制排序,則可以通過Comparator接口的幫助(類似PHP中的array_map回調處理函數的思想)。該接口裡包含一個int compare(T o1, T o2)方法,該方法用于比較大小
import java.util.*;
class M
{
int age;
public M(int age)
{
this.age = age;
}
public String toString()
{
return "M[age:" + age + "]";
}
}
public class TreeSetTest4
{
public static void main(String[] args)
{
TreeSet ts = new TreeSet(new Comparator()
{
//根據M對象的age屬性來決定大小
public int compare(Object o1, Object o2)
{
M m1 = (M)o1;
M m2 = (M)o2;
return m1.age > m2.age ? -1
: m1.age < m2.age ? 1 : 0;
}
});
ts.add(new M(5));
ts.add(new M(-3));
ts.add(new M(9));
System.out.println(ts);
}
} 看到這裡,我們需要梳理一下關于排序的概念
1) equals、compareTo決定的是怎麼比的問題,即用什麼field進行大小比較
2) 自然排序、定制排序、Comparator決定的是誰大的問題,即按什麼順序(升序、降序)進行排序
它們的關注點是不同的,一定要注意區分 EnumSet
import java.util.*;
enum Season
{
SPRING,SUMMER,FALL,WINTER
}
public class EnumSetTest
{
public static void main(String[] args)
{
//建立一個EnumSet集合,集合元素就是Season枚舉類的全部枚舉值
EnumSet es1 = EnumSet.allOf(Season.class);
//輸出[SPRING,SUMMER,FALL,WINTER]
System.out.println(es1);
//建立一個EnumSet空集合,指定其集合元素是Season類的枚舉值。
EnumSet es2 = EnumSet.noneOf(Season.class);
//輸出[]
System.out.println(es2);
//手動添加兩個元素
es2.add(Season.WINTER);
es2.add(Season.SPRING);
//輸出[SPRING,WINTER]
System.out.println(es2);
//以指定枚舉值建立EnumSet集合
EnumSet es3 = EnumSet.of(Season.SUMMER , Season.WINTER);
//輸出[SUMMER,WINTER]
System.out.println(es3);
EnumSet es4 = EnumSet.range(Season.SUMMER , Season.WINTER);
//輸出[SUMMER,FALL,WINTER]
System.out.println(es4);
//新建立的EnumSet集合的元素和es4集合的元素有相同類型,
//es5的集合元素 + es4集合元素 = Season枚舉類的全部枚舉值
EnumSet es5 = EnumSet.complementOf(es4);
//輸出[SPRING]
System.out.println(es5);
}
} 以上就是Set集合類的程式設計應用場景。那麼應該怎樣選擇何時使用這些集合類呢?
1) HashSet的性能總是比TreeSet好(特别是最常用的添加、查詢元素等操作),因為TreeSet需要額外的紅黑樹算法來維護集合元素的次序。隻有當需要一個保持排序的Set時,才應該使用TreeSet,否則都應該使用HashSet
2) 對于普通的插入、删除操作,LinkedHashSet比HashSet要略慢一點,這是由維護連結清單所帶來的開銷造成的。不過,因為有了連結清單的存在,周遊LinkedHashSet會更快
3) EnumSet是所有Set實作類中性能最好的,但它隻能儲存同一個枚舉類的枚舉值作為集合元素
4) HashSet、TreeSet、EnumSet都是"線程不安全"的,通常可以通過Collections工具類的synchronizedSortedSet方法來"包裝"該Set集合。
SortedSet s = Collections.synchronizedSortedSet(new TreeSet(...));
0x2: List
ArrayList
如果一開始就知道ArrayList集合需要儲存多少元素,則可以在建立它們時就指定initialCapacity大小,這樣可以減少重新配置設定的次數,提供性能,ArrayList還提供了如下方法來重新配置設定Object[]數組
1) ensureCapacity(int minCapacity): 将ArrayList集合的Object[]數組長度增加minCapacity
2) trimToSize(): 調整ArrayList集合的Object[]數組長度為目前元素的個數。程式可以通過此方法來減少ArrayList集合對象占用的記憶體空間 import java.util.*;
public class ListTest
{
public static void main(String[] args)
{
List books = new ArrayList();
//向books集合中添加三個元素
books.add(new String("輕量級Java EE企業應用實戰"));
books.add(new String("瘋狂Java講義"));
books.add(new String("瘋狂Android講義"));
System.out.println(books);
//将新字元串對象插入在第二個位置
books.add(1 , new String("瘋狂Ajax講義"));
for (int i = 0 ; i < books.size() ; i++ )
{
System.out.println(books.get(i));
}
//删除第三個元素
books.remove(2);
System.out.println(books);
//判斷指定元素在List集合中位置:輸出1,表明位于第二位
System.out.println(books.indexOf(new String("瘋狂Ajax講義"))); //①
//将第二個元素替換成新的字元串對象
books.set(1, new String("LittleHann"));
System.out.println(books);
//将books集合的第二個元素(包括)
//到第三個元素(不包括)截取成子集合
System.out.println(books.subList(1 , 2));
}
Stack
注意Stack的後進先出的特點
import java.util.*;
public class VectorTest
{
public static void main(String[] args)
{
Stack v = new Stack();
//依次将三個元素push入"棧"
v.push("瘋狂Java講義");
v.push("輕量級Java EE企業應用實戰");
v.push("瘋狂Android講義");
//輸出:[瘋狂Java講義, 輕量級Java EE企業應用實戰 , 瘋狂Android講義]
System.out.println(v);
//通路第一個元素,但并不将其pop出"棧",輸出:瘋狂Android講義
System.out.println(v.peek());
//依然輸出:[瘋狂Java講義, 輕量級Java EE企業應用實戰 , 瘋狂Android講義]
System.out.println(v);
//pop出第一個元素,輸出:瘋狂Android講義
System.out.println(v.pop());
//輸出:[瘋狂Java講義, 輕量級Java EE企業應用實戰]
System.out.println(v);
}
} LinkedList
import java.util.*;
public class LinkedListTest
{
public static void main(String[] args)
{
LinkedList books = new LinkedList();
//将字元串元素加入隊列的尾部(雙端隊列)
books.offer("瘋狂Java講義");
//将一個字元串元素加入棧的頂部(雙端隊列)
books.push("輕量級Java EE企業應用實戰");
//将字元串元素添加到隊列的頭(相當于棧的頂部)
books.offerFirst("瘋狂Android講義");
for (int i = 0; i < books.size() ; i++ )
{
System.out.println(books.get(i));
}
//通路、并不删除棧頂的元素
System.out.println(books.peekFirst());
//通路、并不删除隊列的最後一個元素
System.out.println(books.peekLast());
//将棧頂的元素彈出"棧"
System.out.println(books.pop());
//下面輸出将看到隊列中第一個元素被删除
System.out.println(books);
//通路、并删除隊列的最後一個元素
System.out.println(books.pollLast());
//下面輸出将看到隊列中隻剩下中間一個元素:
//輕量級Java EE企業應用實戰
System.out.println(books);
}
} 從代碼中我們可以看到,LinkedList同時表現出了雙端隊列、棧的用法。功能非常強大
0x3: Queue
PriorityQueue
import java.util.*;
public class PriorityQueueTest
{
public static void main(String[] args)
{
PriorityQueue pq = new PriorityQueue();
//下面代碼依次向pq中加入四個元素
pq.offer(6);
pq.offer(-3);
pq.offer(9);
pq.offer(0);
//輸出pq隊列,并不是按元素的加入順序排列,
//而是按元素的大小順序排列,輸出[-3, 0, 9, 6]
System.out.println(pq);
//通路隊列第一個元素,其實就是隊列中最小的元素:-3
System.out.println(pq.poll());
}
} PriorityQueue不允許插入null元素,它還需要對隊列元素進行排序,PriorityQueue的元素有兩種排序方式
1) 自然排序:
采用自然順序的PriorityQueue集合中的元素對象都必須實作了Comparable接口,而且應該是同一個類的多個執行個體,否則可能導緻ClassCastException異常
2) 定制排序
建立PriorityQueue隊列時,傳入一個Comparator對象,該對象負責對隊列中的所有元素進行排序
關于自然排序、定制排序的原理和之前說的TreeSet類似 ArrayDeque
import java.util.*;
public class ArrayDequeTest
{
public static void main(String[] args)
{
ArrayDeque stack = new ArrayDeque();
//依次将三個元素push入"棧"
stack.push("瘋狂Java講義");
stack.push("輕量級Java EE企業應用實戰");
stack.push("瘋狂Android講義");
//輸出:[瘋狂Java講義, 輕量級Java EE企業應用實戰 , 瘋狂Android講義]
System.out.println(stack);
//通路第一個元素,但并不将其pop出"棧",輸出:瘋狂Android講義
System.out.println(stack.peek());
//依然輸出:[瘋狂Java講義, 輕量級Java EE企業應用實戰 , 瘋狂Android講義]
System.out.println(stack);
//pop出第一個元素,輸出:瘋狂Android講義
System.out.println(stack.pop());
//輸出:[瘋狂Java講義, 輕量級Java EE企業應用實戰]
System.out.println(stack);
}
} 以上就是List集合類的程式設計應用場景。我們來梳理一下思路
1. java提供的List就是一個"線性表接口",ArrayList(基于數組的線性表)、LinkedList(基于鍊的線性表)是線性表的兩種典型實作
2. Queue代表了隊列,Deque代表了雙端隊列(既可以作為隊列使用、也可以作為棧使用)
3. 因為數組以一塊連續記憶體來儲存所有的數組元素,是以數組在随機通路時性能最好。是以的内部以數組作為底層實作的集合在随機通路時性能最好。
4. 内部以連結清單作為底層實作的集合在執行插入、删除操作時有很好的性能
5. 進行疊代操作時,以連結清單作為底層實作的集合比以數組作為底層實作的集合性能好 我們之前說過,Collection接口繼承了Iterable接口,也就是說,我們以上學習到的所有的Collection集合類都具有"可周遊性"
Iterable接口也是java集合架構的成員,它隐藏了各種Collection實作類的底層細節,向應用程式提供了周遊Collection集合元素的統一程式設計接口:
1) boolean hasNext(): 是否還有下一個未周遊過的元素
2) Object next(): 傳回集合裡的下一個元素
3) void remove(): 删除集合裡上一次next方法傳回的元素 iterator實作周遊:
import java.util.*;
public class IteratorTest
{
public static void main(String[] args)
{
//建立一個集合
Collection books = new HashSet();
books.add("輕量級Java EE企業應用實戰");
books.add("瘋狂Java講義");
books.add("瘋狂Android講義");
//擷取books集合對應的疊代器
Iterator it = books.iterator();
while(it.hasNext())
{
//it.next()方法傳回的資料類型是Object類型,
//需要強制類型轉換
String book = (String)it.next();
System.out.println(book);
if (book.equals("瘋狂Java講義"))
{
//從集合中删除上一次next方法傳回的元素
it.remove();
}
//對book變量指派,不會改變集合元素本身
book = "測試字元串";
}
System.out.println(books);
}
} 從代碼可以看出,iterator必須依附于Collection對象,若有一個iterator對象,必然有一個與之關聯的Collection對象。
除了可以使用iterator接口疊代通路Collection集合裡的元素之外,使用java5提供的foreach循環疊代通路集合元素更加便捷
foreach實作周遊:
import java.util.*;
public class ForeachTest
{
public static void main(String[] args)
{
//建立一個集合
Collection books = new HashSet();
books.add(new String("輕量級Java EE企業應用實戰"));
books.add(new String("瘋狂Java講義"));
books.add(new String("瘋狂Android講義"));
for (Object obj : books)
{
//此處的book變量也不是集合元素本身
String book = (String)obj;
System.out.println(book);
if (book.equals("瘋狂Android講義"))
{
//下面代碼會引發ConcurrentModificationException異常
//books.remove(book);
}
}
System.out.println(books);
}
} 除了Collection固有的iterator()方法,List還額外提供了一個listIterator()方法,該方法傳回一個ListIterator對象,ListIterator接口繼承了Iterator接口,提供了專門操作List的方法。ListIterator接口在Iterator接口的繼承上增加了如下方法:
1) boolean hasPrevious(): 傳回該疊代器關聯的集合是否還有上一個元素
2) Object previous(): 傳回該疊代器的上一個元素(向前疊代)
3) void add(): 在指定位置插入一個元素 ListIterator實作周遊:
import java.util.*;
public class ListIteratorTest
{
public static void main(String[] args)
{
String[] books = {
"瘋狂Java講義",
"輕量級Java EE企業應用實戰"
};
List bookList = new ArrayList();
for (int i = 0; i < books.length ; i++ )
{
bookList.add(books[i]);
}
ListIterator lit = bookList.listIterator();
while (lit.hasNext())
{
System.out.println(lit.next());
lit.add("-------分隔符-------");
}
System.out.println("=======下面開始反向疊代=======");
while(lit.hasPrevious())
{
System.out.println(lit.previous());
}
}
} 0x4: Map
HashMap、Hashtable
import java.util.*;
class A
{
int count;
public A(int count)
{
this.count = count;
}
//根據count的值來判斷兩個對象是否相等。
public boolean equals(Object obj)
{
if (obj == this)
return true;
if (obj!=null &&
obj.getClass()==A.class)
{
A a = (A)obj;
return this.count == a.count;
}
return false;
}
//根據count來計算hashCode值。
public int hashCode()
{
return this.count;
}
}
class B
{
//重寫equals()方法,B對象與任何對象通過equals()方法比較都相等
public boolean equals(Object obj)
{
return true;
}
}
public class HashtableTest
{
public static void main(String[] args)
{
Hashtable ht = new Hashtable();
ht.put(new A(60000) , "瘋狂Java講義");
ht.put(new A(87563) , "輕量級Java EE企業應用實戰");
ht.put(new A(1232) , new B());
System.out.println(ht);
//隻要兩個對象通過equals比較傳回true,
//Hashtable就認為它們是相等的value。
//由于Hashtable中有一個B對象,
//它與任何對象通過equals比較都相等,是以下面輸出true。
System.out.println(ht.containsValue("測試字元串")); //①
//隻要兩個A對象的count相等,它們通過equals比較傳回true,且hashCode相等
//Hashtable即認為它們是相同的key,是以下面輸出true。
System.out.println(ht.containsKey(new A(87563))); //②
//下面語句可以删除最後一個key-value對
ht.remove(new A(1232)); //③
//通過傳回Hashtable的所有key組成的Set集合,
//進而周遊Hashtable每個key-value對
for (Object key : ht.keySet())
{
System.out.print(key + "---->");
System.out.print(ht.get(key) + "\n");
}
}
} 當使用自定義類作為HashMap、Hashtable的key時,如果重寫該類的equals(Object obj)和hashCode()方法,則應該保證兩個方法的判斷标準一緻--當兩個key通過equals()方法比較傳回true時,兩個key的hashCode()的傳回值也應該相同
LinkedHashMap
import java.util.*;
public class LinkedHashMapTest
{
public static void main(String[] args)
{
LinkedHashMap scores = new LinkedHashMap();
scores.put("國文" , 80);
scores.put("英文" , 82);
scores.put("數學" , 76);
//周遊scores裡的所有的key-value對
for (Object key : scores.keySet())
{
System.out.println(key + "------>" + scores.get(key));
}
}
} Properties
import java.util.*;
import java.io.*;
public class PropertiesTest
{
public static void main(String[] args) throws Exception
{
Properties props = new Properties();
//向Properties中增加屬性
props.setProperty("username" , "yeeku");
props.setProperty("password" , "123456");
//将Properties中的key-value對儲存到a.ini檔案中
props.store(new FileOutputStream("a.ini"), "comment line"); //①
//建立一個Properties對象
Properties props2 = new Properties();
//向Properties中增加屬性
props2.setProperty("gender" , "male");
//将a.ini檔案中的key-value對追加到props2中
props2.load(new FileInputStream("a.ini") ); //②
System.out.println(props2);
}
} Properties還可以把key-value對以XML檔案的形式儲存起來,也可以從XML檔案中加載key-value對
TreeMap
import java.util.*;
class R implements Comparable
{
int count;
public R(int count)
{
this.count = count;
}
public String toString()
{
return "R[count:" + count + "]";
}
//根據count來判斷兩個對象是否相等。
public boolean equals(Object obj)
{
if (this == obj)
return true;
if (obj!=null
&& obj.getClass()==R.class)
{
R r = (R)obj;
return r.count == this.count;
}
return false;
}
//根據count屬性值來判斷兩個對象的大小。
public int compareTo(Object obj)
{
R r = (R)obj;
return count > r.count ? 1 :
count < r.count ? -1 : 0;
}
}
public class TreeMapTest
{
public static void main(String[] args)
{
TreeMap tm = new TreeMap();
tm.put(new R(3) , "輕量級Java EE企業應用實戰");
tm.put(new R(-5) , "瘋狂Java講義");
tm.put(new R(9) , "瘋狂Android講義");
System.out.println(tm);
//傳回該TreeMap的第一個Entry對象
System.out.println(tm.firstEntry());
//傳回該TreeMap的最後一個key值
System.out.println(tm.lastKey());
//傳回該TreeMap的比new R(2)大的最小key值。
System.out.println(tm.higherKey(new R(2)));
//傳回該TreeMap的比new R(2)小的最大的key-value對。
System.out.println(tm.lowerEntry(new R(2)));
//傳回該TreeMap的子TreeMap
System.out.println(tm.subMap(new R(-1) , new R(4)));
}
} 從代碼中可以看出,類似于TreeSet中判斷兩個元素是否相等的标準,TreeMap中判斷兩個key相等的标準是:
1) 兩個key通過compareTo()方法傳回0
2) equals()放回true 我們在重寫這兩個方法的時候一定要保證它們的邏輯關系一緻。
再次強調一下:
Set和Map的關系十分密切,java源碼就是先實作了HashMap、TreeMap等集合,然後通過包裝一個所有的value都為null的Map集合實作了Set集合類 WeakHashMap
import java.util.*;
public class WeakHashMapTest
{
public static void main(String[] args)
{
WeakHashMap whm = new WeakHashMap();
//将WeakHashMap中添加三個key-value對,
//三個key都是匿名字元串對象(沒有其他引用)
whm.put(new String("國文") , new String("良好"));
whm.put(new String("數學") , new String("及格"));
whm.put(new String("英文") , new String("中等"));
//将WeakHashMap中添加一個key-value對,
//該key是一個系統緩存的字元串對象。"java"是一個常量字元串強引用
whm.put("java" , new String("中等"));
//輸出whm對象,将看到4個key-value對。
System.out.println(whm);
//通知系統立即進行垃圾回收
System.gc();
System.runFinalization();
//通常情況下,将隻看到一個key-value對。
System.out.println(whm);
}
} 如果需要使用WeakHashMap的key來保留對象的弱引用,則不要讓key所引用的對象具有任何強引用,否則将失去使用WeakHashMap的意義
IdentityHashMap
import java.util.*;
public class IdentityHashMapTest
{
public static void main(String[] args)
{
IdentityHashMap ihm = new IdentityHashMap();
//下面兩行代碼将會向IdentityHashMap對象中添加兩個key-value對
ihm.put(new String("國文") , 89);
ihm.put(new String("國文") , 78);
//下面兩行代碼隻會向IdentityHashMap對象中添加一個key-value對
ihm.put("java" , 93);
ihm.put("java" , 98);
System.out.println(ihm);
}
} EnumMap
import java.util.*;
enum Season
{
SPRING,SUMMER,FALL,WINTER
}
public class EnumMapTest
{
public static void main(String[] args)
{
//建立一個EnumMap對象,該EnumMap的所有key
//必須是Season枚舉類的枚舉值
EnumMap enumMap = new EnumMap(Season.class);
enumMap.put(Season.SUMMER , "夏日炎炎");
enumMap.put(Season.SPRING , "春暖花開");
System.out.println(enumMap);
}
} 與建立普通Map有所差別的是,建立EnumMap是必須指定一個枚舉類,進而将該EnumMap和指定枚舉類關聯起來
以上就是Map集合類的程式設計應用場景。我們來梳理一下思路
1) HashMap和Hashtable的效率大緻相同,因為它們的實作機制幾乎完全一樣。但HashMap通常比Hashtable要快一點,因為Hashtable需要額外的線程同步控制
2) TreeMap通常比HashMap、Hashtable要慢(尤其是在插入、删除key-value對時更慢),因為TreeMap底層采用紅黑樹來管理key-value對
3) 使用TreeMap的一個好處就是: TreeMap中的key-value對總是處于有序狀态,無須專門進行排序操作 ![Java小案例——随機數猜測随機數猜測[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)