hadoop架構結構學習詳述
近年,随着網際網路的發展特别是移動網際網路的發展,資料的增長呈現出一種爆炸式的成長勢頭。單是谷歌的爬蟲程式每天下載下傳的網頁超過1億個(2000年資料,)資料的爆炸式增長直接推動了海量資料處理技術的發展。谷歌公司提出的大表、分布式檔案系統和分布式計算的三大技術構架,解決了海量資料處理的問題。谷歌公司随即将設計思路開源,發表了具有劃時代意義的三篇論文,很快根據谷歌設計思路的開源架構就出現了,就是如今非常火爆的hadoop、Maperduce和許多Nosql系統。這三大技術也是整個大資料技術的核心基礎。
目前國内的hadoop商業發行版也是比較多,這些hadoop商業版大部分都是由國外發行的,純國産的發行版不是很多,比如DKhadoop,可以說是目前國内自主做hadoop商業版比較好的了。下面就以大快搜尋DKhadoop為例來給大家介紹一下hadoop架構結構!
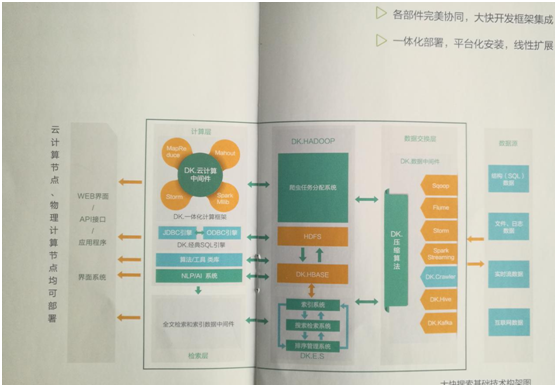
圖示:DKhadoop技術技術架構圖
hadoop架構結構核心:
hadoop的架構結構最核心的設計就是:HDFS和MapReduce。HDFS為海量的資料提供了存儲,MapReduce為海量的資料提供了計算。
大資料一體化開發架構:
大資料的應用開發過于偏向底層,設計技術面非常廣泛,學習的難度自然要大的很多。對于新手入門更是難上加難。DKhadoop則是大快搜尋将一系列技術架構在底層進行了重新封裝。把大資料開發中的一些通用的,重複使用的基礎代碼、算法封裝為類庫,降低了大俗局的學習門檻,降低開發難度。
DKhadoop架構結構構成子產品:
我們以DKhadoop發行版為例:
1、架構由:資料源與SQL引擎、資料采集(自定義爬蟲)子產品、資料處理子產品、機器學習算法、自然語言處理子產品、搜尋引擎子產品,六部分組成。
2、大快的大資料通用計算平台(DKH),已經內建相同版本号的開發架構的全部元件。如果在開源大資料架構上部署大快的開發架構,需要平台的元件支援如下:
(1)資料源與SQL引擎:DK.Hadoop、spark、hive、sqoop、flume、kafka
(2)資料采集:DK.hadoop
(3)資料處理子產品:DK.Hadoop、spark、storm、hive
(4)機器學習和AI:DK.Hadoop、spark
(5)NLP子產品:上傳伺服器端JAR包,直接支援
(6)搜尋引擎子產品:不獨立釋出
Dkhadoop是大快深度整合,重新編譯後的HADOOP發行版,可單獨釋出。獨立部署FreeRCH(大快大資料一體化開發架構)時,必需的元件。DK.HADOOP整合內建了NOSQL資料庫,簡化了檔案系統與非關系資料庫之間的程式設計;DK.HADOOP改進了叢集同步系統,使得HADOOP的資料處理更加高效。
關于hadoop架構結構暫且簡單介紹這些,感興趣的朋友可以找一下大快搜尋的DKhadoop試一下。
![SQL語言基礎:常用的資料查詢語句[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)