1.概述
HBase是一個實時的非關系型資料庫,用來存儲海量資料。但是,在實際使用場景中,在使用HBase API查詢HBase中的資料時,有時會發現資料查詢會很慢。本篇部落格将從用戶端優化和服務端優化兩個方面來介紹,如何提高查詢HBase的效率。
2.内容
這裡,我們先給大家介紹如何從用戶端優化查詢速度。
2.1 用戶端優化
用戶端查詢HBase,均通過HBase API的來擷取資料,如果在實作代碼邏輯時使用API不當,也會造成讀取耗時嚴重的情況。
2.1.1 Scan優化
在使用HBase的Scan接口時,一次Scan會傳回大量資料。用戶端向HBase發送一次Scan請求,實際上并不會将所有資料加載到本地,而是通過多次RPC請求進行加載。這樣設計的好處在于避免大量資料請求會導緻網絡帶寬負載過高影響其他業務使用HBase,另外從用戶端的角度來說可以避免資料量太大,進而本地機器發送OOM(記憶體溢出)。
預設情況下,HBase每次Scan會緩存100條,可以通過屬性hbase.client.scanner.caching來設定。另外,最大值預設為-1,表示沒有限制,具體實作見源代碼:
/**
* @return the maximum result size in bytes. See {@link #setMaxResultSize(long)}
*/
public long getMaxResultSize() {
return maxResultSize;
}
/**
* Set the maximum result size. The default is -1; this means that no specific
* maximum result size will be set for this scan, and the global configured
* value will be used instead. (Defaults to unlimited).
*
* @param maxResultSize The maximum result size in bytes.
*/
public Scan setMaxResultSize(long maxResultSize) {
this.maxResultSize = maxResultSize;
return this;
} 一般情況下,預設緩存100就可以滿足,如果資料量過大,可以适當增大緩存值,來減少RPC次數,進而降低Scan的總體耗時。另外,在做報表呈現時,建議使用HBase分頁來傳回Scan的資料。
2.1.2 Get優化
HBase系統提供了單條get資料和批量get資料,單條get通常是通過請求表名+rowkey,批量get通常是通過請求表名+rowkey集合來實作。用戶端在讀取HBase的資料時,實際是與RegionServer進行資料互動。在使用批量get時可以有效的較少用戶端到各個RegionServer之間RPC連接配接數,進而來間接的提高讀取性能。批量get實作代碼見org.apache.hadoop.hbase.client.HTable類:
public Result[] get(List<Get> gets) throws IOException {
if (gets.size() == 1) {
return new Result[]{get(gets.get(0))};
}
try {
Object[] r1 = new Object[gets.size()];
batch((List<? extends Row>)gets, r1, readRpcTimeoutMs);
// Translate.
Result [] results = new Result[r1.length];
int i = 0;
for (Object obj: r1) {
// Batch ensures if there is a failure we get an exception instead
results[i++] = (Result)obj;
}
return results;
} catch (InterruptedException e) {
throw (InterruptedIOException)new InterruptedIOException().initCause(e);
}
} 從實作的源代碼分析可知,批量get請求的結果,要麼全部傳回,要麼抛出異常。
2.1.3 列簇和列優化
通常情況下,HBase表設計我們一個指定一個列簇就可以滿足需求,但也不排除特殊情況,需要指定多個列簇(官方建議最多不超過3個),其實官方這樣建議也是有原因的,HBase是基于列簇的非關系型資料庫,意味着相同的列簇資料會存放在一起,而不同的列簇的資料會分開存儲在不同的目錄下。如果一個表設計多個列簇,在使用rowkey查詢而不限制列簇,這樣在檢索不同列簇的資料時,需要獨立進行檢索,查詢效率固然是比指定列簇查詢要低的,列簇越多,這樣影響越大。
而同一列簇下,可能涉及到多個列,在實際查詢資料時,如果一個表的列簇有上1000+的列,這樣一個大表,如果不指定列,這樣查詢效率也是會很低。通常情況下,在查詢的時候,可以查詢指定我們需要傳回結果的列,對于不需要的列,可以不需要指定,這樣能夠有效地的提高查詢效率,降低延時。
2.1.4 禁止緩存優化
批量讀取資料時會全表掃描一次業務表,這種提現在Scan操作場景。在Scan時,用戶端與RegionServer進行資料互動(RegionServer的實際資料時存儲在HDFS上),将資料加載到緩存,如果加載很大的資料到緩存時,會對緩存中的實時業務熱資料有影響,由于緩存大小有限,加載的資料量過大,會将這些熱資料“擠壓”出去,這樣當其他業務從緩存請求這些資料時,會從HDFS上重新加載資料,導緻耗時嚴重。
在批量讀取(T+1)場景時,建議用戶端在請求是,在業務代碼中調用setCacheBlocks(false)函數來禁止緩存,預設情況下,HBase是開啟這部分緩存的。源代碼實作為:
/**
* Set whether blocks should be cached for this Get.
* <p>
* This is true by default. When true, default settings of the table and
* family are used (this will never override caching blocks if the block
* cache is disabled for that family or entirely).
*
* @param cacheBlocks if false, default settings are overridden and blocks
* will not be cached
*/
public Get setCacheBlocks(boolean cacheBlocks) {
this.cacheBlocks = cacheBlocks;
return this;
}
/**
* Get whether blocks should be cached for this Get.
* @return true if default caching should be used, false if blocks should not
* be cached
*/
public boolean getCacheBlocks() {
return cacheBlocks;
} 2.2 服務端優化
HBase服務端配置或叢集有問題,也會導緻用戶端讀取耗時較大,叢集出現問題,影響的是整個叢集的業務應用。
2.2.1 負載均衡優化
用戶端的請求實際上是與HBase叢集的每個RegionServer進行資料互動,在細分一下,就是與每個RegionServer上的某些Region進行資料互動,每個RegionServer上的Region個數上的情況下,可能這種耗時情況影響不大,展現不夠明顯。但是,如果每個RegionServer上的Region個數較大的話,這種影響就會很嚴重。筆者這裡做過統計的資料統計,當每個RegionServer上的Region個數超過800+,如果發生負載不均衡,這樣的影響就會很嚴重。
可能有同學會有疑問,為什麼會發送負載不均衡?負載不均衡為什麼會造成這樣耗時嚴重的影響?
1.為什麼會發生負載不均衡?
負載不均衡的影響通常由以下幾個因素造成:
- 沒有開啟自動負載均衡
- 叢集維護,擴容或者縮減RegionServer節點
- 叢集有RegionServer節點發生當機或者程序停止,随後守護程序又自動拉起當機的RegionServer程序
針對這些因素,可以通過以下解決方案來解決:
- 開啟自動負載均衡,執行指令:echo "balance_switch true" | hbase shell
- 在維護叢集,或者守護程序拉起停止的RegionServer程序時,定時排程執行負載均衡指令:echo "balancer" | hbase shell
2.負載不均衡為什麼會造成這樣耗時嚴重的影響?
這裡筆者用一個例子來說,叢集每個RegionServer包含由800+的Region數,但是,由于叢集維護,有幾台RegionServer節點的Region全部集中到一台RegionServer,分布如下圖所示:
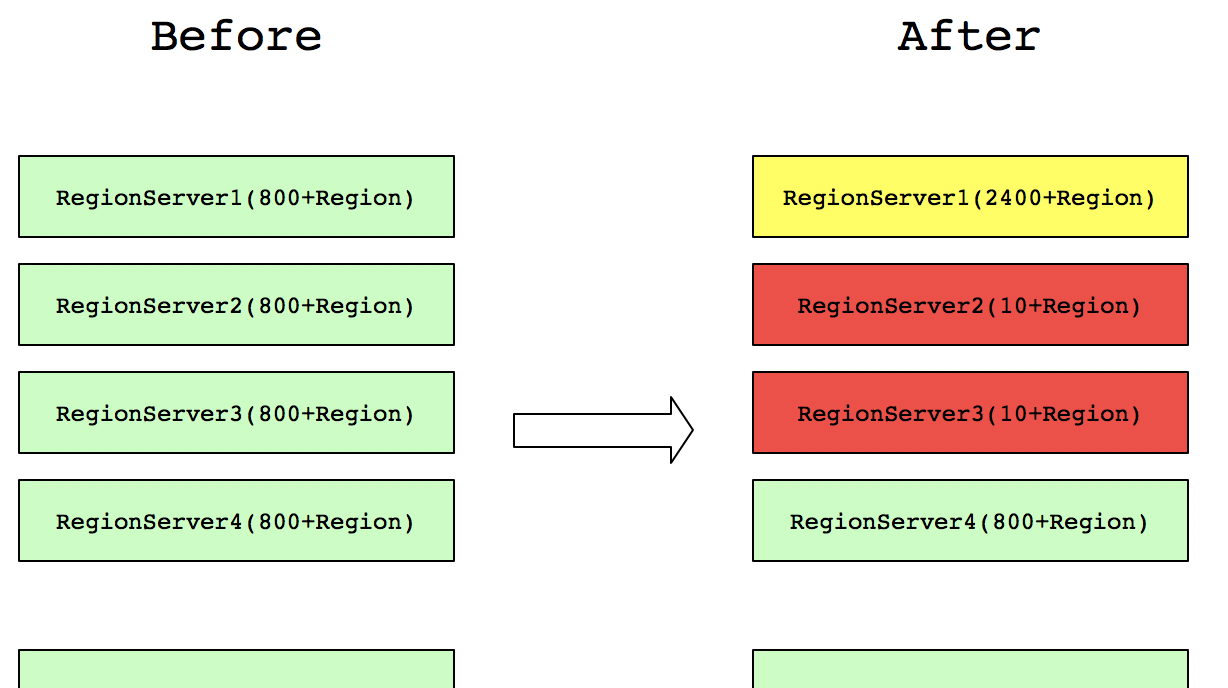
這樣之前請求在RegionServer2和RegionServer3上的,都會集中到RegionServer1上去請求。這樣就不能發揮整個叢集的并發處理能力,另外,RegionServer1上的資源使用将會翻倍(比如網絡、磁盤IO、HBase RPC的Handle數等)。而原先其他正常業務到RegionServer1的請求也會是以受到很大的影響。是以,讀取請求不均衡不僅會造成本身業務性能很長,還會嚴重影響其他正常業務的查詢。同理,寫請求不均衡,也會造成類似的影響。故HBase負載均衡是HBase叢集性能的重要展現。
2.2.2 BlockCache優化
BlockCache作為讀緩存,合理設定對于提高讀性能非常重要。預設情況下,BlockCache和Memstore的配置各站40%,可以通過在hbase-site.xml配置以下屬性來實作:
- hfile.block.cache.size,預設0.4,用來提高讀性能
- hbase.regionserver.global.memstore.size,預設0.4,用來提高寫性能
本篇部落客要介紹提高讀性能,這裡我們可以将BlockCache的占比設定大一些,Memstore的占比設定小一些(總占比保持在0.8即可)。另外,BlockCache的政策選擇也是很重要的,不同的政策對于讀性能來說影響不大,但是對于GC的影響卻比較明顯,在設定hbase.bucketcache.ioengine屬性為offheap時,GC表現的很優秀。緩存結構如下圖所示:

設定BlockCache可以在hbase-site.xml檔案中,配置如下屬性:
<!-- 配置設定的記憶體大小盡可能的多些,前提是不能超過 (機器實際實體記憶體-JVM記憶體) -->
<property>
<name>hbase.bucketcache.size</name>
<value>16384</value>
</property>
<property>
<name>hbase.bucketcache.ioengine</name>
<value>offheap</value>
</property> 設定塊記憶體大小,可以參考入下表格:
| 标号 | 描述 | 計算公式或值 | 結果 |
| A | 實體記憶體選擇:on-heap(JVM)+off-heap(Direct) | 單台實體節點記憶體值,機關MB | 262144 |
| B | HBASE_HEAPSIZE('-Xmx) | 機關MB | 20480 |
| C | -XX:MaxDirectMemorySize,off-heap允許的最大記憶體值 | A-B | 241664 |
| Dp | hfile.block.cache.size和hbase.regionserver.global.memstore.size總和不要超過0.8 | 讀取比例占比*0.8 | 0.5*0.8=0.4 |
| Dm | JVM Heap允許的最大BlockCache(MB) | B*Dp | 20480*0.4=8192 |
| Ep | hbase.regionserver.global.memstore.size設定的最大JVM值 | 0.8-Dp | 0.8-0.4=0.4 |
| F | 用于其他用途的off-heap記憶體,例如DFSClient | 推薦1024到2048 | 2048 |
| G | BucketCache允許的off-heap記憶體 | C-F | 241664-2048=239616 |
另外,BlockCache政策,能夠有效的提高緩存命中率,這樣能夠間接的提高熱資料覆寫率,進而提升讀取性能。
2.2.3 HFile優化
HBase讀取資料時會先從BlockCache中進行檢索(熱資料),如果查詢不到,才會到HDFS上去檢索。而HBase存儲在HDFS上的資料以HFile的形式存在的,檔案如果越多,檢索所花費的IO次數也就必然增加,對應的讀取耗時也就增加了。檔案數量取決于Compaction的執行政策,有以下2個屬性有關系:
- hbase.hstore.compactionThreshold,預設為3,表示store中檔案數超過3個就開始進行合并操作
- hbase.hstore.compaction.max.size,預設為9223372036854775807,合并的檔案最大閥值,超過這個閥值的檔案不能進行合并
另外,hbase.hstore.compaction.max.size值可以通過實際的Region總數來計算,公式如下:
hbase.hstore.compaction.max.size = RegionTotal / hbase.hstore.compactionThreshold 2.2.4 Compaction優化
Compaction操作是将小檔案合并為大檔案,提高後續業務随機讀取的性能,但是在執行Compaction操作期間,節點IO、網絡帶寬等資源會占用較多,那麼什麼時候執行Compaction才最好?什麼時候需要執行Compaction操作?
1.什麼時候執行Compaction才最好?
實際應用場景中,會關閉Compaction自動執行政策,通過屬性hbase.hregion.majorcompaction來控制,将hbase.hregion.majorcompaction=0,就可以禁止HBase自動執行Compaction操作。一般情況下,選擇叢集負載較低,資源空閑的時間段來定時排程執行Compaction。
如果合并的檔案較多,可以通過設定如下屬性來提生Compaction的執行速度,配置如下:
<property>
<name>hbase.regionserver.thread.compaction.large</name>
<value>8</value>
<description></description>
</property>
<property>
<name>hbase.regionserver.thread.compaction.small</name>
<value>5</value>
<description></description>
</property> 2.什麼時候需要執行Compaction操作?
一般維護HBase叢集後,由于叢集發生過重新開機,HBase資料本地性較低,通過HBase頁面可以觀察,此時如果不執行Compaction操作,那麼用戶端查詢的時候,需要跨副本節點去查詢,這樣來回需要經過網絡帶寬,對比正常情況下,從本地節點讀取資料,耗時是比較大的。在執行Compaction操作後,HBase資料本地性為1,這樣能夠有效的提高查詢效率。
3.總結
本篇部落格HBase查詢優化從用戶端和服務端角度,列舉一些常見有效地優化手段。當然,優化還需要從自己實際應用場景出發,例如代碼實作邏輯、實體機的實際配置等方面來設定相關參數。大家可以根據實際情況來參考本篇部落格進行優化。
4.結束語
這篇部落格就和大家分享到這裡,如果大家在研究學習的過程當中有什麼問題,可以加群進行讨論或發送郵件給我,我會盡我所能為您解答,與君共勉!
另外,部落客出書了《Hadoop大資料挖掘從入門到進階實戰》,喜歡的朋友或同學, 可以在公告欄那裡點選購買連結購買部落客的書進行學習,在此感謝大家的支援。
聯系方式:
Twitter:
https://twitter.com/smartloliQQ群(Hadoop - 交流社群1):
424769183溫馨提示:請大家加群的時候寫上加群理由(姓名+公司/學校),友善管理者稽核,謝謝!