【架構】
Spark采用了分布式計算中的Master-Slave模型。
【1】Master作為整個叢集的控制器,負責整個叢集的正常運作;【2】Worker是計算節點,接受主節點指令以及進行狀态彙報;
【3】Executor負責任務(Tast)的排程和執行;
【4】Client作為使用者的用戶端負責送出應用;
【5】Driver負責控制一個應用的執行。
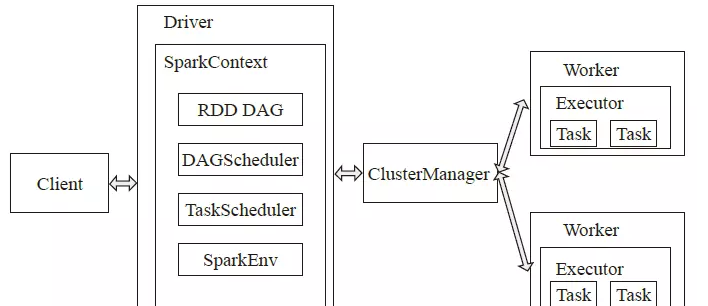
Spark叢集啟動時,需要從主節點和從節點分别啟動Master程序和Worker程序,對整個叢集進行控制。在一個Spark應用的執行過程中,Driver是應用的邏輯執行起點,運作Application的main函數并建立SparkContext,DAGScheduler把對Job中的RDD有向無環圖根據依賴關系劃分為多個Stage,每一個Stage是一個TaskSet, TaskScheduler把Task分發給Worker中的Executor;Worker啟動Executor,Executor啟動線程池用于執行Task。
【RDD】
RDD:彈性分布式資料集,是一種記憶體抽象,可以了解為一個大數組,數組的元素是RDD的分區Partition,分布在叢集上;在實體資料存儲上,RDD的每一個Partition對應的就是一個資料塊Block,Block可以存儲在記憶體中,當記憶體不夠時可以存儲在磁盤上。

資料集分區存儲在節點的記憶體中,減少疊代過程(如機器學習算法)反複的I/O操作進而提高性能。而Hadoop将Mapreduce計算的結果寫入磁盤。
【工作機制】
【應用執行的機制】
Spark應用(Application)是使用者送出的應用程式,執行模式有Local、Standalone、YARN、Mesos。
根據Application的Driver Program(或者YARN的AppMaster)是否在叢集中運作
Spark應用的運作方式又可以分為Cluster模式和Client模式。
【yarn-Cluster模式和yarn-Client模式的差別】
client的driver運作在本地 AppMaster運作在yarn的一個節點上
AM隻負責資源申請和釋放,遠端通信,等待driver完成;
cluster的driver運作在AM所在的container裡,driver和AM是同一個程序的不同線程,會通信,AM同樣等待driver的完成,進而釋放資源。
【spark-yarn】
【shuffle】
定義:對無規則的資料進行重組排序等過程
必要性:分布式計算中資料時分布在各節點上計算的,而彙總統計等操作需要在所有資料上執行
在運作job時,spark是一個stage一個stage執行的
每個Stage由多個Task組成,同一Stage的各Task并行執行互不影響,但是後一個(Stage 1)需要等待前一個(Stage 0)執行結束才能開始執行,更為詳細的執行過程如下圖。
在Stage 0 和Stage 1之間存在資料交換,Stage 0 的Task無法确定其所産生的結果最終需要傳遞給Stage 1的哪個Task,是以資料需要按照一定的規則(Partitioner)重新打亂,這個過程稱為Shuffle
【寬窄依賴】RDD 的 Transformation 函數中,又分為窄依賴(narrow dependency)和寬依賴(wide dependency)的操作.窄依賴跟寬依賴的差別是是否發生 shuffle(洗牌) 操作.
寬依賴會發生 shuffle 操作.
窄依賴是子 RDD的各個分片(partition)不依賴于其他分片,能夠獨立計算得到結果
寬依賴指子 RDD 的各個分片會依賴于父RDD 的多個分片,是以會造成父 RDD 的各個分片在叢集中重新分片
【Hash based shuffle 】Hash based shuffle的每個mapper都需要為每個reducer寫一個檔案,供reducer讀取,即需要産生M*R個數量的檔案,如果mapper和reducer的數量比較大,産生的檔案數會非常多。
Hadoop Map Reduce被人诟病的地方,很多不需要sort的地方的sort導緻了不必要的開銷,于是Spark的Hash based shuffle設計的目标之一就是避免不需要的排序,
但是它在處理超大規模資料集的時候,産生了大量的磁盤IO和記憶體的消耗,很影響性能。
【Sort based shuffle】為了解決hash based shuffle性能差的問題,Spark 1.1 引入了Sort based shuffle,完全借鑒map reduce實作,每個Shuffle Map Task隻産生一個檔案,不再為每個Reducer生成一個單獨的檔案,将所有的結果隻寫到一個Data檔案裡,同時生成一個index檔案,index檔案存儲了Data中的資料是如何進行分類的。Reducer可以通過這個index檔案取得它需要處理的資料。 下一個Stage中的Task就是根據這個Index檔案來擷取自己所要抓取的上一個Stage中的Shuffle Map Task的輸出資料。
Shuffle Map Task産生的結果隻寫到一個Data檔案裡, 避免産生大量的檔案,進而節省了記憶體的使用和順序Disk IO帶來的低延時。節省記憶體的使用可以減少GC的風險和頻率。
而減少檔案的數量可以避免同時寫多個檔案對系統帶來的壓力。
Sort based shuffle在速度和記憶體使用方面也優于Hash based shuffle。
【Tungsten-sort Based Shuffle】Tungsten-sort是對普通sort的一種優化,排序的不是内容本身,而是内容序列化後位元組數組的指針(中繼資料),把資料的排序轉變為了指針數組的排序,實作了直接對序列化後的二進制資料進行排序。由于直接基于二進制資料進行操作,是以在這裡面沒有序列化和反序列化的過程。記憶體的消耗降低,相應的也會減少gc的開銷。
Tungsten-sort優化點主要在三個方面:
1)直接在serialized binary data上進行sort而不是java objects,減少了memory的開銷和GC的overhead。
2)提供cache-efficient sorter,使用一個8 bytes的指針,把排序轉化成了一個指針數組的排序。
3)spill的merge過程也無需反序列化即可完成。
這些優化的實作導緻引入了一個新的記憶體管理模型,類似OS的Page,Page是由MemoryBlock組成的, 支援off-heap(用NIO或者Tachyon管理) 以及 on-heap 兩種模式。為了能夠對Record 在這些MemoryBlock進行定位,又引入了Pointer的概念。