什麼是大資料平台 有三個疑問:
1.使用Cloudera或Hortonworks之類的Hadoop發行版本公司的提供的Hadoop套件,配置些參數,找幾台伺服器部署起來就算是一套大資料平台嗎?
2.資料開發人員平時的工作是不是寫些MR或者SQL任務,使用原生的指令行送出任務就可以了嗎?
3.平台開發人員日常的工作是不是處理下叢集的故障,給業務方掃盲,糾正各種架構元件使用姿勢呢?
大資料平台個人了解:
是基于開源或自研元件的基礎上創造更多的附件價值,提供給使用者一個
完整的大資料業務解決方案,而不僅僅是做一個叢集的維護者
大資料平台的價值
1.資料開發角度
一.降低資料開發門檻
二.提升資料開發人員效率
2.運維角度
一.降低運維門檻
二.提升運維效率
3.公司角度
一.資料統一管理(OneData理念),降低成本
大資料平台架構選型
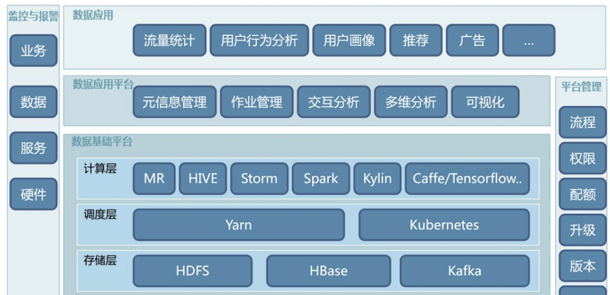
離線計算:
1.Spark+SparkSQL
2.MR(Hadoop)+HiveSQL
離線資料同步:
1.DataX(Alibaba,開源支援單機版本)
- FlinkX(Dtstack,開源支援單機,standalone,yarn 模式)
- Sqoop(隻能做Hadoop和關系型資料庫之間的資料同步)
- Kettle
實時計算:
1.Flink
2.SparkStreaming
- Storm
- JStorm(Alibaba)
- StreamCQL(華為)
實時資料同步:
1.Flume
- Logstash(Elastic)
- JLogstash(Dtstack)
多元分析(即席查詢):
1.Kylin
- SparkSQL+CarbonData
- Impala+Kudu 或Parquet
機器學習:
1.Spark MLib
- Flink MLib
- XGBoost
深度學習:
1.TensorFlow
- Caffe
- Keras
資料總管:
1.Yarn
- Mesos
- Kubernetes+Docker
叢集管理:
1.Cloudera
2.星環
- Hortonworks
- Ambari
![SQL語言基礎:常用的資料查詢語句[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)