本文向您詳細介紹如何通過使用DataWorks資料同步功能,将Hadoop資料遷移到阿裡雲MaxCompute大資料計算服務上。
1. 環境準備
1.1 Hadoop叢集搭建
進行資料遷移前,您需要保證自己的Hadoop叢集環境正常。本文使用阿裡雲EMR服務自動化搭建Hadoop叢集,詳細過程請參見
https://help.aliyun.com/document_detail/35223.html?spm=a2c4g.11186623.6.557.20e219306ZJC9i。
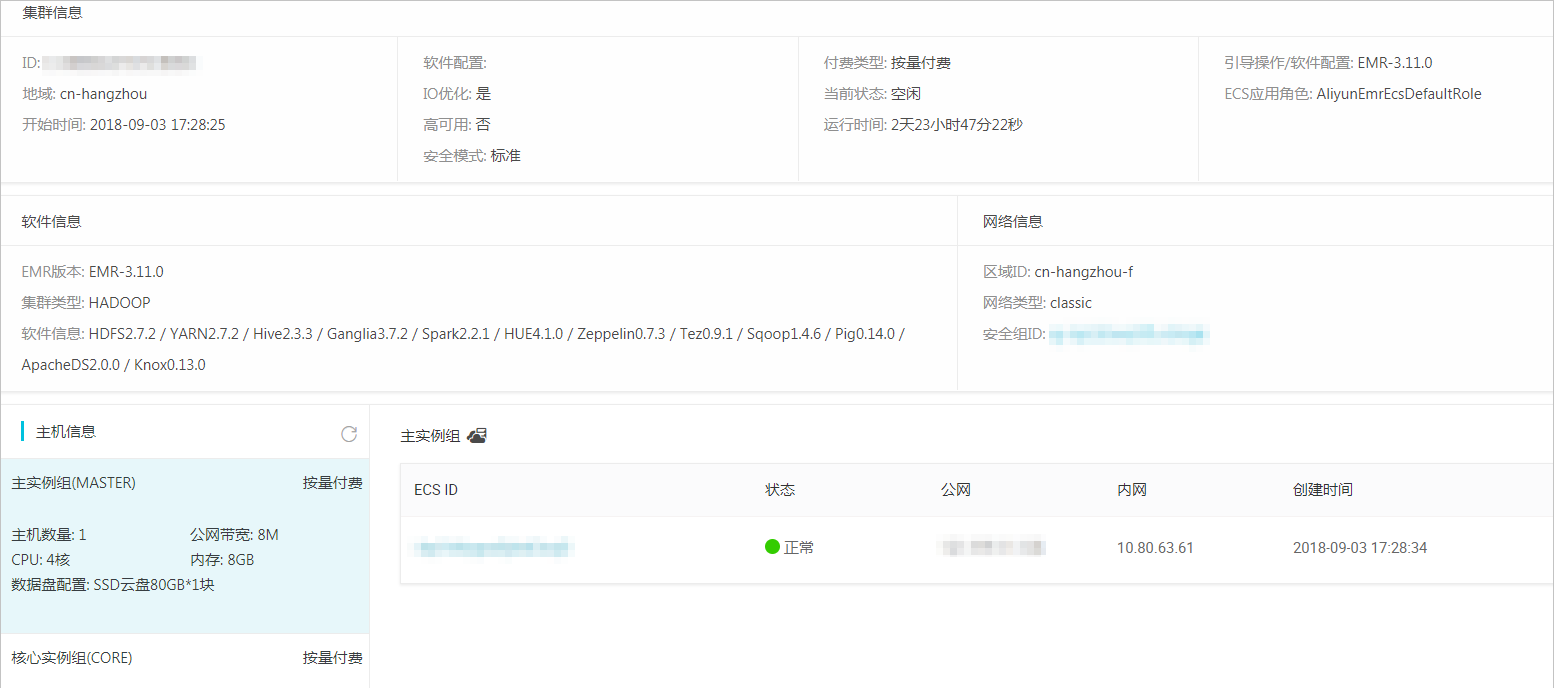
本文使用的EMR Hadoop版本資訊如下:
EMR版本: EMR-3.11.0
叢集類型: HADOOP
軟體資訊: HDFS2.7.2 / YARN2.7.2 / Hive2.3.3 / Ganglia3.7.2 / Spark2.2.1 / HUE4.1.0 / Zeppelin0.7.3 / Tez0.9.1 / Sqoop1.4.6 / Pig0.14.0 / ApacheDS2.0.0 / Knox0.13.0
Hadoop叢集使用經典網絡,區域為華東1(杭州),主執行個體組ECS計算資源配置公網及内網IP,高可用選擇為否(非HA模式),具體配置如下所示。
1.2 MaxCompute
請參考
https://help.aliyun.com/document_detail/58226.html?spm=a2c4g.11174283.6.570.64d4590eaIbcxH開通MaxCompute服務并建立好項目,本文中在華東1(杭州)區域建立項目bigdata_DOC,同時啟動DataWorks相關服務,如下所示。

2. 資料準備
2.1 Hadoop叢集建立測試資料
進入EMR Hadoop叢集控制台界面,使用互動式工作台,建立互動式任務doc。本例中HIVE建表語句:
CREATE TABLE IF NOT EXISTS hive_doc_good_sale(
create_time timestamp,
category STRING,
brand STRING,
buyer_id STRING,
trans_num BIGINT,
trans_amount DOUBLE,
click_cnt BIGINT
)
PARTITIONED BY (pt string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' lines terminated by '\n'
選擇運作,觀察到Query executed successfully提示則說明成功在EMR Hadoop叢集上建立了測試用表格hive_doc_good_sale,如下圖所示。
插入測試資料,您可以選擇從OSS或其他資料源導入測試資料,也可以手動插入少量的測試資料。本文中手動插入資料如下:
insert into hive_doc_good_sale PARTITION(pt =1 ) values('2018-08-21','外套','品牌A','lilei',3,500.6,7),('2018-08-22','生鮮','品牌B','lilei',1,303,8),('2018-08-22','外套','品牌C','hanmeimei',2,510,2),(2018-08-22,'衛浴','品牌A','hanmeimei',1,442.5,1),('2018-08-22','生鮮','品牌D','hanmeimei',2,234,3),('2018-08-23','外套','品牌B','jimmy',9,2000,7),('2018-08-23','生鮮','品牌A','jimmy',5,45.1,5),('2018-08-23','外套','品牌E','jimmy',5,100.2,4),('2018-08-24','生鮮','品牌G','peiqi',10,5560,7),('2018-08-24','衛浴','品牌F','peiqi',1,445.6,2),('2018-08-24','外套','品牌A','ray',3,777,3),('2018-08-24','衛浴','品牌G','ray',3,122,3),('2018-08-24','外套','品牌C','ray',1,62,7) ;
完成插入資料後,您可以使用select * from hive_doc_good_sale where pt =1;語句檢查Hadoop叢集表中是否已存在資料可用于遷移。
2.2 利用DataWorks建立目标表
在管理控制台,選擇對應的MaxCompute項目,點選進入資料開發頁面,點選建立表,如下所示。
在彈框中輸入SQL建表語句,本例中使用的建表語句如下:
create_time string,
PARTITIONED BY (pt string) ;
在建表過程中,需要考慮到HIVE資料類型與MaxCompute資料類型的映射,目前資料映射關系可參見
https://help.aliyun.com/document_detail/54081.html?spm=a2c4e.11153940.blogcont630231.16.587919b0KIgCfQ由于本文使用DataWorks進行資料遷移,而DataWorks資料同步功能目前暫不支援timestamp類型資料,是以在DataWorks建表語句中,将create_time設定為string類型。
上述步驟同樣可通過odpscmd指令行工具完成,指令行工具安裝和配置請參考
https://help.aliyun.com/document_detail/27804.html?spm=a2c4g.11186623.6.572.e66b5a41WP2nyj,執行過程如下所示。
注意:考慮到部分HIVE與MaxCompute資料類型的相容問題,建議在odpscmd用戶端上執行以下指令。
set odps.sql.type.system.odps2=true;set odps.sql.hive.compatible=true;
完成建表後,可在DataWorks資料開發>表查詢一欄檢視到目前建立的MaxCompute上的表,如下所示。
3. 資料同步
3.1 建立自定義資源組
由于MaxCompute項目所處的網絡環境與Hadoop叢集中的資料節點(data node)網絡通常不可達,我們可通過自定義資源組的方式,将DataWorks的同步任務運作在Hadoop叢集的Master節點上(Hadoop叢集内Master節點和資料節點通常可達)。
3.1.1 檢視Hadoop叢集datanode
在EMR控制台上首頁/叢集管理/叢集/主機清單頁檢視,如下圖所示,通常非HA模式的EMR上Hadoop叢集的master節點主機名為 emr-header-1,datanode主機名為emr-worker-X。
您也可以通過點選上圖中Master節點的ECS ID,進入ECS執行個體詳情頁,通過點選遠端連接配接進入ECS,通過 hadoop dfsadmin –report指令檢視datenode,如下圖所示。
由上圖可以看到,在本例中,datanode隻具有内網位址,很難與DataWorks預設資源組互通,是以我們需要設定自定義資源組,将master node設定為執行DataWorks資料同步任務的節點。
3.1.2 建立自定義資源組
進入DataWorks資料內建頁面,選擇資源組,點選新增資源組,如下圖所示。關于新增排程資源組的詳細資訊,請參考
新增排程資源 在添加伺服器步驟中,需要輸入ECS UUID和機器IP等資訊(對于經典網絡類型,需輸入伺服器名稱,對于專有網絡類型,需輸入伺服器UUID。目前僅DataWorks V2.0 華東2區支援經典網絡類型的排程資源添加,對于其他區域,無論您使用的是經典網絡還是專有網絡類型,在添加排程資源組時都請選擇專有網絡類型),機器IP需填寫master node公網IP(内網IP可能不可達)。ECS的UUID需要進入master node管理終端,通過指令dmidecode | grep UUID擷取(如果您的hadoop叢集并非搭建在EMR環境上,也可以通過該指令擷取),如下所示。
完成添加伺服器後,需保證master node與DataWorks網絡可達,如果您使用的是ECS伺服器,需設定伺服器安全組。如果您使用的内網IP互通,可參考
https://help.aliyun.com/document_detail/72978.html?spm=a2c4g.11186623.6.580.6a294f79DmqM6f設定。如果您使用的是公網IP,可直接設定安全組公網出入方向規則,本文中設定公網入方向放通所有端口(實際應用場景中,為了您的資料安全,強烈建議設定詳細的放通規則),如下圖所示。
完成上述步驟後,按照提示安裝自定義資源組agent,觀察到目前狀态為可用,說明新增自定義資源組成功。
如果狀态為不可用,您可以登入master node,使用tail –f/home/admin/alisatasknode/logs/heartbeat.log指令檢視DataWorks與master node之間心跳封包是否逾時,如下圖所示。
3.2 建立資料源
關于DataWorks建立資料源詳細步驟,請參見
https://help.aliyun.com/knowledge_list/72788.html?spm=a2c4g.11186623.6.573.7d882b59eqdXhiDataWorks建立項目後,預設設定自己為資料源odps_first。是以我們隻需添加Hadoop叢集資料源:在DataWorks資料內建頁面,點選資料源>新增資料源,在彈框中選擇HDFS類型的資料源。
在彈出視窗中填寫資料源名稱及defaultFS。對于EMR Hadoop叢集而言,如果Hadoop叢集為HA叢集,則此處位址為hdfs://emr-header-1的IP:8020,如果Hadoop叢集為非HA叢集,則此處位址為hdfs://emr-header-1的IP:9000。在本文中,emr-header-1與DataWorks通過公網連接配接,是以此處填寫公網IP并放通安全組。
完成配置後,點選測試連通性,如果提示“測試連通性成功”,則說明資料源添加正常。
注意:如果EMR Hadoop叢集設定網絡類型為專有網絡,則不支援連通性測試。
3.3 配置資料同步任務
在DataWorks資料內建頁面點選同步任務,選擇建立>腳本模式,在導入模闆彈窗選擇資料源類型如下:
完成導入模闆後,同步任務會轉入腳本模式,本文中配置腳本如下,相關解釋請參見
https://help.aliyun.com/document_detail/74304.html?spm=a2c4g.11186631.6.576.2c506aaczJB2i7 在配置資料同步任務腳本時,需注意DataWorks同步任務和HIVE表中資料類型的轉換如下:
| 在Hive表中的資料類型 | DataX/DataWorks 内部類型 |
| TINYINT,SMALLINT,INT,BIGINT | Long |
| FLOAT,DOUBLE,DECIMAL | Double |
| String,CHAR,VARCHAR | String |
| BOOLEAN | Boolean |
| Date,TIMESTAMP | Date |
| Binary |
詳細代碼如下:
{
"configuration": {
"reader": {
"plugin": "hdfs",
"parameter": {
"path": "/user/hive/warehouse/hive_doc_good_sale/",
"datasource": "HDFS1",
"column": [
{
"index": 0,
"type": "string"
},
"index": 1,
"index": 2,
"index": 3,
"index": 4,
"type": "long"
"index": 5,
"type": "double"
"index": 6,
}
],
"defaultFS": "hdfs://121.199.11.138:9000",
"fieldDelimiter": ",",
"encoding": "UTF-8",
"fileType": "text"
}
},
"writer": {
"plugin": "odps",
"partition": "pt=1",
"truncate": false,
"datasource": "odps_first",
"create_time",
"category",
"brand",
"buyer_id",
"trans_num",
"trans_amount",
"click_cnt"
"table": "hive_doc_good_sale"
"setting": {
"errorLimit": {
"record": "1000"
},
"speed": {
"throttle": false,
"concurrent": 1,
"mbps": "1",
"dmu": 1
}
},
"type": "job",
"version": "1.0"
}
其中,path參數為資料在Hadoop叢集中存放的位置,您可以在登入master node後,使用hdfs dfs –ls /user/hive/warehouse/hive_doc_good_sale指令确認。對于分區表,您可以不指定分區,DataWorks資料同步會自動遞歸到分區路徑,如下圖所示。
完成配置後,點選運作。如果提示任務運作成功,則說明同步任務已完成。如果運作失敗,可通過複制日志進行進一步排查。
4. 驗證結果
在DataWorks資料開發/表查詢頁面,選擇表hive_doc_good_sale後,點選資料預覽可檢視HIVE資料是否已同步到MaxCompute。您也可以通過建立一個table查詢任務,在任務中輸入腳本select * FROM hive_doc_good_sale where pt =1;後,點選運作來檢視表結果,如下圖所示。
當然,您也可以通過在odpscmd指令行工具中輸入select * FROM hive_doc_good_sale where pt =1;查詢表結果。
5. MaxCompute資料遷移到Hadoop
如果您想實作MaxCompute資料遷移到Hadoop。步驟與上述步驟類似,不同的是同步腳本内的reader和writer對象需要對調,具體實作腳本舉例如下。
{
"configuration": {
"reader": {
"plugin": "odps",
"parameter": {
"partition": "pt=1",
"isCompress": false,
"datasource": "odps_first",
"column": [
"create_time",
"category",
"brand",
"buyer_id",
"trans_num",
"trans_amount",
"click_cnt"
],
"table": "hive_doc_good_sale"
}
},
"writer": {
"plugin": "hdfs",
"parameter": {
"path": "/user/hive/warehouse/hive_doc_good_sale",
"fileName": "pt=1",
"datasource": "HDFS_data_source",
"column": [
{
"name": "create_time",
"type": "string"
},
{
"name": "category",
"type": "string"
},
{
"name": "brand",
"type": "string"
},
{
"name": "buyer_id",
"type": "string"
},
{
"name": "trans_num",
"type": "BIGINT"
},
{
"name": "trans_amount",
"type": "DOUBLE"
},
{
"name": "click_cnt",
"type": "BIGINT"
}
],
"defaultFS": "hdfs://47.99.162.100:9000",
"writeMode": "append",
"fieldDelimiter": ",",
"encoding": "UTF-8",
"fileType": "text"
}
},
"setting": {
"errorLimit": {
"record": "1000"
},
"speed": {
"throttle": false,
"concurrent": 1,
"mbps": "1",
"dmu": 1
}
}
},
"type": "job",
"version": "1.0"
} 您需要參考
配置HDFS Writer在運作上述同步任務前對Hadoop叢集進行設定,在運作同步任務後手動拷貝同步過去的檔案。