What
Java序列化是指把Java對象儲存為二進制位元組碼的過程,Java反序列化是指把二進制碼重新轉換成Java對象的過程。
那麼為什麼需要序列化呢?
第一種情況是:一般情況下Java對象的聲明周期都比Java虛拟機的要短,實際應用中我們希望在JVM停止運作之後能夠持久化指定的對象,這時候就需要把對象進行序列化之後儲存。
第二種情況是:需要把Java對象通過網絡進行傳輸的時候。因為資料隻能夠以二進制的形式在網絡中進行傳輸,是以當把對象通過網絡發送出去之前需要先序列化成二進制資料,在接收端讀到二進制資料之後反序列化成Java對象。
How
本部分以序列化到檔案為例講解Java序列化的基本用法。
package test;
import java.io.*;
/**
* @author v_shishusheng
* @date 2018/2/7
*/
public class SerializableTest {
public static void main(String[] args) throws Exception {
FileOutputStream fos = new FileOutputStream("temp.out");
ObjectOutputStream oos = new ObjectOutputStream(fos);
TestObject testObject = new TestObject();
oos.writeObject(testObject);
oos.flush();
oos.close();
FileInputStream fis = new FileInputStream("temp.out");
ObjectInputStream ois = new ObjectInputStream(fis);
TestObject deTest = (TestObject) ois.readObject();
System.out.println(deTest.testValue);
System.out.println(deTest.parentValue);
System.out.println(deTest.innerObject.innerValue);
}
}
class Parent implements Serializable {
private static final long serialVersionUID = -4963266899668807475L;
public int parentValue = 100;
}
class InnerObject implements Serializable {
private static final long serialVersionUID = 5704957411985783570L;
public int innerValue = 200;
}
class TestObject extends Parent implements Serializable {
private static final long serialVersionUID = -3186721026267206914L;
public int testValue = 300;
public InnerObject innerObject = new InnerObject();
}
程式執行完用sublime打開temp.out檔案,可以看到
aced 0005 7372 0017 636f 6d2e 7373 732e
7465 7374 2e54 6573 744f 626a 6563 74d3
c67e 1c4f 132a fe02 0002 4900 0974 6573
7456 616c 7565 4c00 0b69 6e6e 6572 4f62
6a65 6374 7400 1a4c 636f 6d2f 7373 732f
7465 7374 2f49 6e6e 6572 4f62 6a65 6374
3b78 7200 1363 6f6d 2e73 7373 2e74 6573
742e 5061 7265 6e74 bb1e ef0d 1fc9 50cd
0200 0149 000b 7061 7265 6e74 5661 6c75
6578 7000 0000 6400 0001 2c73 7200 1863
6f6d 2e73 7373 2e74 6573 742e 496e 6e65
724f 626a 6563 744f 2c14 8a40 24fb 1202
0001 4900 0a69 6e6e 6572 5661 6c75 6578
7000 0000 c8
Why
調用ObjectOutputStream.writeObject()和ObjectInputStream.readObject()之後究竟做了什麼?temp.out檔案中的二進制分别代表什麼意思?
1. ObjectStreamClass類
方文檔對這個類的介紹如下
Serialization’s descriptor for classes. It contains the name and serialVersionUID of the class. The ObjectStreamClass for a specific class loaded in this Java VM can be found/created using the lookup method.
可以看到是類的序列化描述符,這個類可以描述需要被序列化的類的中繼資料,包括被序列化的類的名字以及序列号。可以通過lookup()方法來查找/建立在這個JVM中加載的特定的ObjectStreamClass對象。
2.序列化:writeObject()
調用wroteObject()進行序列化之前會先調用ObjectOutputStream的構造函數生成一個ObjectOutputStream對象,構造函數如下:
public ObjectOutputStream(OutputStream out) throws IOException {
verifySubclass();
// bout表示底層的位元組資料容器
bout = new BlockDataOutputStream(out);
handles = new HandleTable(10, (float) 3.00);
subs = new ReplaceTable(10, (float) 3.00);
enableOverride = false;
writeStreamHeader(); // 寫入檔案頭
bout.setBlockDataMode(true); // flush資料
if (extendedDebugInfo) {
debugInfoStack = new DebugTraceInfoStack();
} else {
debugInfoStack = null;
}
}
構造函數中首先會把bout綁定到底層的位元組資料容器,接着會調用writeStreamHeader()方法,該方法實作如下:
protected void writeStreamHeader() throws IOException {
bout.writeShort(STREAM_MAGIC);
bout.writeShort(STREAM_VERSION);
}
在writeStreamHeader()方法中首先會往底層位元組容器中寫入表示序列化的Magic Number以及版本号,定義為
/**
* Magic number that is written to the stream header.
*/
final static short STREAM_MAGIC = (short)0xaced;
/**
* Version number that is written to the stream header.
*/
final static short STREAM_VERSION = 5;
接下來會調用writeObject()方法進行序列化,實作如下:
public final void writeObject(Object obj) throws IOException {
if (enableOverride) {
writeObjectOverride(obj);
return; }
try {
// 調用writeObject0()方法序列化
writeObject0(obj, false);
} catch (IOException ex) {
if (depth == 0) {
writeFatalException(ex);
}
throw ex;
}
}
正常情況下會調用writeObject0()進行序列化操作,該方法實作如下:
private void writeObject0(Object obj, boolean unshared)
throws IOException
{
boolean oldMode = bout.setBlockDataMode(false);
depth++;
try {
// handle previously written and non-replaceable objects
int h;
if ((obj = subs.lookup(obj)) == null) {
writeNull();
return;
} else if (!unshared && (h = handles.lookup(obj)) != -1) {
writeHandle(h);
return;
} else if (obj instanceof Class) {
writeClass((Class) obj, unshared);
return;
} else if (obj instanceof ObjectStreamClass) {
writeClassDesc((ObjectStreamClass) obj, unshared);
return;
}
// check for replacement object
Object orig = obj;
// 擷取要序列化的對象的Class對象
Class<?> cl = obj.getClass();
ObjectStreamClass desc;
for (;;) {
// REMIND: skip this check for strings/arrays?
Class<?> repCl;
// 建立描述cl的ObjectStreamClass對象
desc = ObjectStreamClass.lookup(cl, true);
if (!desc.hasWriteReplaceMethod() ||
(obj = desc.invokeWriteReplace(obj)) == null ||
(repCl = obj.getClass()) == cl)
{
break;
}
cl = repCl;
}
if (enableReplace) {
Object rep = replaceObject(obj);
if (rep != obj && rep != null) {
cl = rep.getClass();
desc = ObjectStreamClass.lookup(cl, true);
}
obj = rep;
}
// if object replaced, run through original checks a second time
if (obj != orig) {
subs.assign(orig, obj);
if (obj == null) {
writeNull();
return;
} else if (!unshared && (h = handles.lookup(obj)) != -1) {
writeHandle(h);
return;
} else if (obj instanceof Class) {
writeClass((Class) obj, unshared);
return;
} else if (obj instanceof ObjectStreamClass) {
writeClassDesc((ObjectStreamClass) obj, unshared);
return;
}
}
// 根據實際的類型進行不同的寫入操作
// remaining cases
if (obj instanceof String) {
writeString((String) obj, unshared);
} else if (cl.isArray()) {
writeArray(obj, desc, unshared);
} else if (obj instanceof Enum) {
writeEnum((Enum<?>) obj, desc, unshared);
} else if (obj instanceof Serializable) {
// 被序列化對象實作了Serializable接口
writeOrdinaryObject(obj, desc, unshared);
} else {
if (extendedDebugInfo) {
throw new NotSerializableException(
cl.getName() + "\n" + debugInfoStack.toString());
} else {
throw new NotSerializableException(cl.getName());
}
}
} finally {
depth--;
bout.setBlockDataMode(oldMode);
}
}
從代碼裡面可以看到,程式會
- 生成一個描述被序列化對象類的類元資訊的ObjectStreamClass對象
- 根據傳入的需要序列化的對象的實際類型進行不同的序列化操作。從代碼裡面可以很明顯的看到,
- 對于String類型、數組類型和Enum可以直接進行序列化
-
如果被序列化對象實作了Serializable對象,則會調用writeOrdinaryObject()方法進行序列化
這裡可以解釋一個問題:Serializbale接口是個空的接口,并沒有定義任何方法,為什麼需要序列化的接口隻要實作Serializbale接口就能夠進行序列化。
答案是:Serializable接口這是一個辨別,告訴程式所有實作了”我”的對象都需要進行序列化。
是以,序列化過程接下來會執行到writeOrdinaryObject()這個方法中,該方法實作如下:
private void writeOrdinaryObject(Object obj,
ObjectStreamClass desc,
boolean unshared)
throws IOException
{
if (extendedDebugInfo) {
debugInfoStack.push(
(depth == 1 ? "root " : "") + "object (class \"" +
obj.getClass().getName() + "\", " + obj.toString() + ")");
}
try {
desc.checkSerialize();
// 寫入Object标志位
bout.writeByte(TC_OBJECT);
// 寫入類中繼資料
writeClassDesc(desc, false);
handles.assign(unshared ? null : obj);
if (desc.isExternalizable() && !desc.isProxy()) {
writeExternalData((Externalizable) obj); // 寫入被序列化的對象的執行個體資料
} else {
writeSerialData(obj, desc);
}
} finally {
if (extendedDebugInfo) {
debugInfoStack.pop();
}
}
}
在這個方法中首先會往底層位元組容器中寫入TC_OBJECT,表示這是一個新的Object
/**
* new Object.
*/
final static byte TC_OBJECT = (byte)0x73;
接下來會調用writeClassDesc()方法寫入被序列化對象的類的類中繼資料,writeClassDesc()方法實作如下:
private void writeClassDesc(ObjectStreamClass desc, boolean unshared)
throws IOException
{
int handle;
if (desc == null) {
// 如果desc為null
writeNull();
} else if (!unshared && (handle = handles.lookup(desc)) != -1) {
writeHandle(handle);
} else if (desc.isProxy()) {
writeProxyDesc(desc, unshared);
} else {
writeNonProxyDesc(desc, unshared);
}
}
在這個方法中會先判斷傳入的desc是否為null,如果為null則調用writeNull()方法
private void writeNull() throws IOException {
// TC_NULL = (byte)0x70;
// 表示對一個Object引用的描述的結束
bout.writeByte(TC_NULL);
}
如果不為null,則一般情況下接下來會調用writeNonProxyDesc()方法,該方法實作如下:
private void writeNonProxyDesc(ObjectStreamClass desc, boolean unshared)
throws IOException
{
// TC_CLASSDESC = (byte)0x72;
// 表示一個新的Class描述符
bout.writeByte(TC_CLASSDESC);
handles.assign(unshared ? null : desc);
if (protocol == PROTOCOL_VERSION_1) {
// do not invoke class descriptor write hook with old protocol
desc.writeNonProxy(this);
} else {
writeClassDescriptor(desc);
}
Class cl = desc.forClass();
bout.setBlockDataMode(true);
if (cl != null && isCustomSubclass()) {
ReflectUtil.checkPackageAccess(cl);
}
annotateClass(cl);
bout.setBlockDataMode(false);
bout.writeByte(TC_ENDBLOCKDATA);
writeClassDesc(desc.getSuperDesc(), false);
}
在這個方法中首先會寫入一個位元組的TC_CLASSDESC,這個位元組表示接下來的資料是一個新的Class描述符,接着會調用writeNonProxy()方法寫入實際的類元資訊,writeNonProxy()實作如下:
void writeNonProxy(ObjectOutputStream out) throws IOException {
out.writeUTF(name); // 寫入類的名字
out.writeLong(getSerialVersionUID()); // 寫入類的序列号
byte flags = 0;
// 擷取類的辨別
if (externalizable) {
flags |= ObjectStreamConstants.SC_EXTERNALIZABLE;
int protocol = out.getProtocolVersion();
if (protocol != ObjectStreamConstants.PROTOCOL_VERSION_1) {
flags |= ObjectStreamConstants.SC_BLOCK_DATA;
}
} else if (serializable) {
flags |= ObjectStreamConstants.SC_SERIALIZABLE;
}
if (hasWriteObjectData) {
flags |= ObjectStreamConstants.SC_WRITE_METHOD;
}
if (isEnum) {
flags |= ObjectStreamConstants.SC_ENUM;
}
out.writeByte(flags); // 寫入類的flag
out.writeShort(fields.length); // 寫入對象的字段的個數
for (int i = 0; i < fields.length; i++) {
ObjectStreamField f = fields[i];
out.writeByte(f.getTypeCode());
out.writeUTF(f.getName());
if (!f.isPrimitive()) {
// 如果不是原始類型,即是對象或者Interface
// 則會寫入表示對象或者類的類型字元串
out.writeTypeString(f.getTypeString());
}
}
}
writeNonProxy()方法中會按照以下幾個過程來寫入資料:
-
- 調用writeUTF()方法寫入對象所屬類的名字,對于本例中name = com.sss.test.對于writeUTF()這個方法,在寫入實際的資料之前會先寫入name的位元組數,代碼如下:
void writeUTF(String s, long utflen) throws IOException {
if (utflen > 0xFFFFL) {
throw new UTFDataFormatException();
}
// 寫入兩個位元組的s的長度
writeShort((int) utflen);
if (utflen == (long) s.length()) {
writeBytes(s);
} else {
writeUTFBody(s);
}
}
-
- 接下來會調用writeLong()方法寫入類的序列号UID,UID是通過getSerialVersionUID()方法來擷取。
-
- 接着會判斷被序列化的對象所屬類的flag,并寫入底層位元組容器中(占用兩個位元組)。類的flag分為以下幾類:
- final static byte SC_EXTERNALIZABLE = 0×04;表示該類為Externalizable類,即實作了Externalizable接口。
- final static byte SC_SERIALIZABLE = 0×02;表示該類實作了Serializable接口。
- final static byte SC_WRITE_METHOD = 0×01;表示該類實作了Serializable接口且自定義了writeObject()方法。
-
final static byte SC_ENUM = 0×10;表示該類是個Enum類型。
對于本例中flag = 0×02表示隻是Serializable類型。
-
-
依次寫入被序列化對象的字段的中繼資料。
<1> 首先會寫入被序列化對象的字段的個數,占用兩個位元組。本例中為2,因為TestObject類中隻有兩個字段,一個是int類型的testValue,一個是InnerObject類型的innerValue。
<2> 依次寫入每個字段的中繼資料。每個單獨的字段由ObjectStreamField類來表示。
-
1.寫入字段的類型碼,占一個位元組。 類型碼的映射關系如下
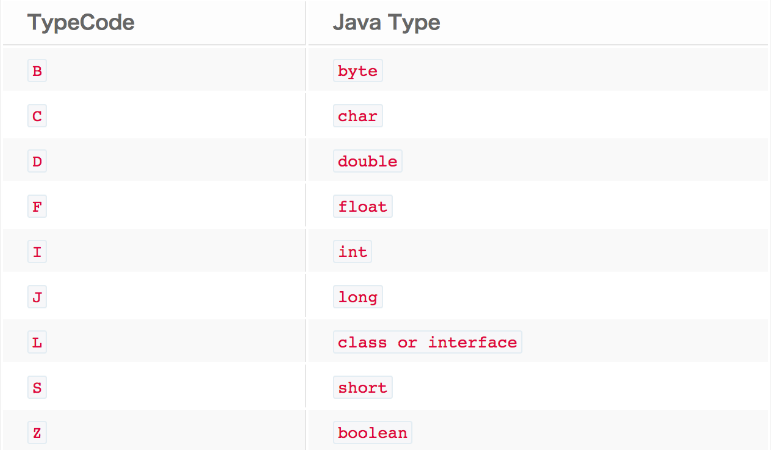
類型碼的映射關系
2.調用writeUTF()方法寫入每個字段的名字。注意,writeUTF()方法會先寫入名字占用的位元組數。
3.如果被寫入的字段不是基本類型,則會接着調用writeTypeString()方法寫入代表對象或者類的類型字元串,該方法需要一個參數,表示對應的類或者接口的字元串,最終調用的還是writeString()方法,實作如下
private void writeString(String str, boolean unshared) throws IOException {
handles.assign(unshared ? null : str);
long utflen = bout.getUTFLength(str);
if (utflen <= 0xFFFF) {
// final static byte TC_STRING = (byte)0x74;
// 表示接下來的位元組表示一個字元串
bout.writeByte(TC_STRING);
bout.writeUTF(str, utflen);
} else {
bout.writeByte(TC_LONGSTRING);
bout.writeLongUTF(str, utflen);
}
}
在這個方法中會先寫入一個标志位TC_STRING表示接下來的資料是一個字元串,接着會調用writeUTF()寫入字元串。
執行完上面的過程之後,程式流程重新回到writeNonProxyDesc()方法中
private void writeNonProxyDesc(ObjectStreamClass desc, boolean unshared)
throws IOException
{
// 其他省略代碼
// TC_ENDBLOCKDATA = (byte)0x78;
// 表示對一個object的描述塊的結束
bout.writeByte(TC_ENDBLOCKDATA);
writeClassDesc(desc.getSuperDesc(), false); // 尾遞歸調用,寫入父類的類中繼資料
}
接下來會寫入一個位元組的标志位TC_ENDBLOCKDATA表示對一個object的描述塊的結束。
然後會調用writeClassDesc()方法,傳入父類的ObjectStreamClass對象,寫入父類的類中繼資料。
需要注意的是writeClassDesc()這個方法是個遞歸調用,調用結束傳回的條件是沒有了父類,即傳入的ObjectStreamClass對象為null,這個時候會寫入一個位元組的辨別位TC_NULL.
在遞歸調用完成寫入類的類中繼資料之後,程式執行流程回到wriyeOrdinaryObject()方法中,
private void writeOrdinaryObject(Object obj,
ObjectStreamClass desc,
boolean unshared) throws IOException
{
// 其他省略代碼
try {
desc.checkSerialize();
// 其他省略代碼
if (desc.isExternalizable() && !desc.isProxy()) {
writeExternalData((Externalizable) obj);
} else {
writeSerialData(obj, desc); // 寫入被序列化的對象的執行個體資料
}
} finally {
if (extendedDebugInfo) {
debugInfoStack.pop();
}
}
}
從上面的分析中我們可以知道,當寫入類的中繼資料的時候,是先寫子類的類中繼資料,然後遞歸調用的寫入父類的類中繼資料。
接下來會調用writeSerialData()方法寫入被序列化的對象的字段的資料,方法實作如下:
private void writeSerialData(Object obj, ObjectStreamClass desc)
throws IOException
{
// 擷取表示被序列化對象的資料的布局的ClassDataSlot數組,父類在前
ObjectStreamClass.ClassDataSlot[] slots = desc.getClassDataLayout();
for (int i = 0; i < slots.length; i++) {
ObjectStreamClass slotDesc = slots[i].desc;
if (slotDesc.hasWriteObjectMethod()) {
// 如果被序列化對象自己實作了writeObject()方法,則執行if塊裡的代碼
// 一些省略代碼
} else {
// 調用預設的方法寫入執行個體資料
defaultWriteFields(obj, slotDesc);
}
}
}
在這個方法中首先會調用getClassDataSlot()方法擷取被序列化對象的資料的布局,關于這個方法官方文檔中說明如下:
/**
* Returns array of ClassDataSlot instances representing the data layout
* (including superclass data) for serialized objects described by this
* class descriptor. ClassDataSlots are ordered by inheritance with those
* containing "higher" superclasses appearing first. The final
* ClassDataSlot contains a reference to this descriptor.
*/
ClassDataSlot[] getClassDataLayout() throws InvalidClassException;
需要注意的是這個方法會把從父類繼承的資料一并傳回,并且表示從父類繼承的資料的ClassDataSlot對象在數組的最前面。
對于沒有自定義writeObject()方法的對象來說,接下來會調用defaultWriteFields()方法寫入資料,該方法實作如下:
private void defaultWriteFields(Object obj, ObjectStreamClass desc)
throws IOException
{
// 其他一些省略代碼
int primDataSize = desc.getPrimDataSize();
if (primVals == null || primVals.length < primDataSize) {
primVals = new byte[primDataSize];
}
// 擷取對應類中的基本資料類型的資料并儲存在primVals位元組數組中
desc.getPrimFieldValues(obj, primVals);
// 把基本資料類型的資料寫入底層位元組容器中
bout.write(primVals, 0, primDataSize, false);
// 擷取對應類的所有的字段對象
ObjectStreamField[] fields = desc.getFields(false);
Object[] objVals = new Object[desc.getNumObjFields()];
int numPrimFields = fields.length - objVals.length;
// 把對應類的Object類型(非原始類型)的對象儲存到objVals數組中
desc.getObjFieldValues(obj, objVals);
for (int i = 0; i < objVals.length; i++) {
// 一些省略的代碼
try {
// 對所有Object類型的字段遞歸調用writeObject0()方法寫入對應的資料
writeObject0(objVals[i],
fields[numPrimFields + i].isUnshared());
} finally {
if (extendedDebugInfo) {
debugInfoStack.pop();
}
}
}
}
可以看到,在這個方法中會做下面幾件事情:
<1> 擷取對應類的基本類型的字段的資料,并寫入到底層的位元組容器中。
<2> 擷取對應類的Object類型(非基本類型)的字段成員,遞歸調用writeObject0()方法寫入相應的資料。
從上面對寫入資料的分析可以知道,寫入資料是是按照先父類後子類的順序來寫的。
至此,Java序列化過程分析完畢,總結一下,在本例中序列化過程如下:

現在可以來分析下第二步中寫入的temp.out檔案的内容了。
aced Stream Magic
0005 序列化版本号
73 标志位:TC_OBJECT,表示接下來是個新的Object
72 标志位:TC_CLASSDESC,表示接下來是對Class的描述
0020 類名的長度為32
636f 6d2e 6265 6175 7479 626f 7373 2e73 com.beautyboss.s
6c6f 6765 6e2e 5465 7374 4f62 6a65 6374 logen.TestObject
d3c6 7e1c 4f13 2afe 序列号
02 flag,可序列化
00 02 TestObject的字段的個數,為2
49 TypeCode,I,表示int類型
0009 字段名長度,占9個位元組
7465 7374 5661 6c75 65 字段名:testValue
4c TypeCode:L,表示是個Class或者Interface
000b 字段名長度,占11個位元組
696e 6e65 724f 626a 6563 74 字段名:innerObject
74 标志位:TC_STRING,表示後面的資料是個字元串
0023 類名長度,占35個位元組
4c63 6f6d 2f62 6561 7574 7962 6f73 732f Lcom/beautyboss/
736c 6f67 656e 2f49 6e6e 6572 4f62 6a65 slogen/InnerObje
6374 3b ct;
78 标志位:TC_ENDBLOCKDATA,對象的資料塊描述的結束
接下來開始寫入資料,從父類Parent開始
0000 0064 parentValue的值:100
0000 012c testValue的值:300
接下來是寫入InnerObject的類元資訊
73 标志位,TC_OBJECT:表示接下來是個新的Object
72 标志位,TC_CLASSDESC:表示接下來是對Class的描述
0021 類名的長度,為33
636f 6d2e 6265 6175 7479 626f 7373 com.beautyboss
2e73 6c6f 6765 6e2e 496e 6e65 724f .slogen.InnerO
626a 6563 74 bject
4f2c 148a 4024 fb12 序列号
02 flag,表示可序列化
0001 字段個數,1個
49 TypeCode,I,表示int類型
00 0a 字段名長度,10個位元組
69 6e6e 6572 5661 6c75 65 innerValue
78 标志位:TC_ENDBLOCKDATA,對象的資料塊描述的結束
70 标志位:TC_NULL,Null object reference.
0000 00c8 innervalue的值:200
3. 反序列化:readObject()
反序列化過程就是按照前面介紹的序列化算法來解析二進制資料。
有一個需要注意的問題就是,如果子類實作了Serializable接口,但是父類沒有實作Serializable接口,這個時候進行反序列化會發生什麼情況?
答:如果父類有預設構造函數的話,即使沒有實作Serializable接口也不會有問題,反序列化的時候會調用預設構造函數進行初始化,否則的話反序列化的時候會抛出.InvalidClassException:異常,異常原因為no valid constructor。
Other
1. static和transient字段不能被序列化。
序列化的時候所有的資料都是來自于ObejctStreamClass對象,在生成ObjectStreamClass的構造函數中會調用fields = getSerialFields(cl);這句代碼來擷取需要被序列化的字段,getSerialFields()方法實際上是調用getDefaultSerialFields()方法的,getDefaultSerialFields()實作如下:
private static ObjectStreamField[] getDefaultSerialFields(Class<?> cl) {
Field[] clFields = cl.getDeclaredFields();
ArrayList<ObjectStreamField> list = new ArrayList<>();
int mask = Modifier.STATIC | Modifier.TRANSIENT;
for (int i = 0; i < clFields.length; i++) {
if ((clFields[i].getModifiers() & mask) == 0) {
// 如果字段既不是static也不是transient的才會被加入到需要被序列化字段清單中去
list.add(new ObjectStreamField(clFields[i], false, true));
}
}
int size = list.size();
return (size == 0) ? NO_FIELDS :
list.toArray(new ObjectStreamField[size]);
}
從上面的代碼中可以很明顯的看到,在計算需要被序列化的字段的時候會把被static和transient修飾的字段給過濾掉。
在進行反序列化的時候會給預設值。
2. 如何實作自定義序列化和反序列化?
隻需要被序列化的對象所屬的類定義了void writeObject(ObjectOutputStream oos)和void readObject(ObjectInputStream ois)方法即可,Java序列化和反序列化的時候會調用這兩個方法,那麼這個功能是怎麼實作的呢?
- 在ObjectClassStream類的構造函數中有下面幾行代碼:
cons = getSerializableConstructor(cl);
writeObjectMethod = getPrivateMethod(cl, "writeObject",
new Class<?>[] { ObjectOutputStream.class },
Void.TYPE);
readObjectMethod = getPrivateMethod(cl, "readObject",
new Class<?>[] { ObjectInputStream.class },
Void.TYPE);
readObjectNoDataMethod = getPrivateMethod(
cl, "readObjectNoData", null, Void.TYPE);
hasWriteObjectData = (writeObjectMethod != null);
cons = getSerializableConstructor(cl);
writeObjectMethod = getPrivateMethod(cl, "writeObject",
new Class<?>[] { ObjectOutputStream.class },
Void.TYPE);
readObjectMethod = getPrivateMethod(cl, "readObject",
new Class<?>[] { ObjectInputStream.class },
Void.TYPE);
readObjectNoDataMethod = getPrivateMethod(
cl, "readObjectNoData", null, Void.TYPE);
hasWriteObjectData = (writeObjectMethod != null);
cons = getSerializableConstructor(cl);
writeObjectMethod = getPrivateMethod(cl, "writeObject",
new Class<?>[] { ObjectOutputStream.class },
Void.TYPE);
readObjectMethod = getPrivateMethod(cl, "readObject",
new Class<?>[] { ObjectInputStream.class },
Void.TYPE);
readObjectNoDataMethod = getPrivateMethod(
cl, "readObjectNoData", null, Void.TYPE);
hasWriteObjectData = (writeObjectMethod != null);
getPrivateMethod()方法實作如下:
private static Method getPrivateMethod(Class<?> cl, String name,
Class<?>[] argTypes,
Class<?> returnType)
{
try {
Method meth = cl.getDeclaredMethod(name, argTypes);
meth.setAccessible(true);
int mods = meth.getModifiers();
return ((meth.getReturnType() == returnType) &&
((mods & Modifier.STATIC) == 0) &&
((mods & Modifier.PRIVATE) != 0)) ? meth : null;
} catch (NoSuchMethodException ex) {
return null;
}
}
可以看到在ObejctStreamClass的構造函數中會查找被序列化類中有沒有定義為void writeObject(ObjectOutputStream oos) 的函數,如果找到的話,則會把找到的方法指派給writeObjectMethod這個變量,如果沒有找到的話則為null。
- 在調用writeSerialData()方法寫入序列化資料的時候有
private void writeSerialData(Object obj, ObjectStreamClass desc)
throws IOException
{
ObjectStreamClass.ClassDataSlot[] slots = desc.getClassDataLayout();
for (int i = 0; i < slots.length; i++) {
ObjectStreamClass slotDesc = slots[i].desc;
if (slotDesc.hasWriteObjectMethod()) {
// 其他一些省略代碼
try {
curContext = new SerialCallbackContext(obj, slotDesc);
bout.setBlockDataMode(true);
// 在這裡調用使用者自定義的方法
slotDesc.invokeWriteObject(obj, this);
bout.setBlockDataMode(false);
bout.writeByte(TC_ENDBLOCKDATA);
} finally {
curContext.setUsed();
curContext = oldContext;
if (extendedDebugInfo) {
debugInfoStack.pop();
}
}
curPut = oldPut;
} else {
defaultWriteFields(obj, slotDesc);
}
}
}
首先會調用hasWriteObjectMethod()方法判斷有沒有自定義的writeObject(),代碼如下
boolean hasWriteObjectMethod() {
return (writeObjectMethod != null);
}
hasWriteObjectMethod()這個方法僅僅是判斷writeObjectMethod是不是等于null,而上面說了,如果使用者自定義了void writeObject(ObjectOutputStream oos)這麼個方法,則writeObjectMethod不為null,在if()代碼塊中會調用slotDesc.invokeWriteObject(obj, this);方法,該方法中會調用使用者自定義的writeObject()方法。
Java程式設計思想相關知識點
當程式運作時,有關對象的資訊就存儲在了記憶體當中,但是當程式終止時,對象将不再繼續存在。我們需要一種儲存對象資訊的方法,使我們的程式關閉之後他還繼續存在,當我們再次打開程式時,可以輕易的還原當時的狀态。這就是對象序列化的目的。
java的對象序列化将那些實作了Serializable接口的對象轉換成一個位元組序列,并且能夠在以後将這個位元組序列完全恢複為原來的對象,甚至可以通過網絡傳播。 這意味着序列化機制自動彌補了不同OS之間的差異.
如此,java實作了“輕量級持久性”,為啥是輕量級,因為在java中我們還不能直接通過一個類似public這樣的關鍵字直接使一個對象序列化,并讓系統自動維護其他細節問題。是以我們隻能在程式中顯示地序列化與反序列化
對象序列化的概念加入到語言中是為了支援兩種主要特性:
- java的遠端方法調用(RMI),它使存活于其他計算機上的對象使用起來就像存活于本機上一樣。當遠端對象發送消息時,需要通過對象序列化來傳輸參數和傳回值。
- 對于Java Bean來說,對象序列化是必須的。使用一個Bean時,一般情況下是在設計階段對它的狀态資訊進行配置。這種狀态資訊必須儲存下來,并在程式啟動的時候進行後期恢複,這種具體工作就是由對象序列化完成的。
使用——對象實作Serializable接口(僅僅是一個标記接口,沒有任何方法)。
序列化一個對象:
1. 建立某些OutputStream對象
2. 将其封裝在一個ObjectOutputStream對象内
3. 隻需調用writeObject()即可将對象序列化
注:也可以為一個String調用writeObject();也可以用與DataOutputStream相同的方法寫入所有基本資料類型(它們具有同樣的接口)
反序列化
将一個InputStream封裝在ObjectInputStream内,然後調用readObject()。最後獲得的是一個引用,它指向一個向上轉型的Object,是以必須向下轉型才能直接設定它們
對象序列化不僅儲存了對象的“全景圖”,而且能夠追蹤對象内所包含的所有引用,并儲存這些對象;接着又能對對象内包含的每個這樣的引用進行追蹤;以此類推。這種情況有時被稱為“對象網”。
例子:
ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream("worm.out");
out.writeObject(w);
out.close();
ObjectInputStream in = new ObjectInputStream(new FileInputStream("worm.out");
String s = (String)in.readObject();
在對一個Serializable對象進行還原的過程中,沒有調用任何構造器,包括預設的構造器。
整個對象都是通過InputStream中取得資料恢複而來的。
尋找類:必須保證java虛拟機能夠找到相關的.class檔案。找不到就會得到一個ClassNotFOundExcption的異常。
序列化的控制——通過實作Externalizable接口——代替實作Serializable接口——來對序列化過程進行控制。
1. Externalizable接口繼承了Serializable接口,增加了兩個方法,writeExternal()和readExternal(),這兩個方法會在序列化和反序列化還原的過程中被自動調用。
2. Externalizable對象,在還原的時候所有普通的預設構造器都會被調用(包括在字段定義時的初始化)(隻有這樣才能使Externalizable對象産生正确的行為),然後調用readExternal().
3. 如果我們從一個Externalizable對象繼承,通常需要調用基類版本的writeExternal()和readExternal()來為基類元件提供恰當的存儲和恢複功能。
4. 為了正常運作,我們不僅需要在writeExternal()方法中将來自對象的重要資訊寫入,還必須在readExternal()中恢複資料
防止對象的敏感部分被序列化,兩種方式:
1. 将類實作Externalizable,在writeExternal()内部隻對所需部分進行顯示的序列化
2. 實作Serializable,用transient(瞬時)關鍵字(隻能和Serializable一起使用)逐個字段的關閉序列化,他的意思:不用麻煩你儲存或恢複資料——我自己會處理。
Externalizable的替代方法
1. 實作Serializable接口,并添加名為writeObject()和readObject()的方法,這樣一旦對象被序列化或者被反序列化還原,就會自動的分别調用writeObject()和readObject()的方法(它們不是接口的一部分,接口的所有東西都是public的)。隻要提供這兩個方法,就會使用它們而不是預設的序列化機制。
2. 這兩個方法必須具有準确的方法特征簽名,但是這兩個方法并不在這個類中的其他方法中調用,而是在ObjectOutputStream和ObjectInputStream對象的writeObject()和readObject()方法
[圖檔上傳失敗...(image-c92672-1517928660769)]
3. 技巧:在你的writeObject()和readObject()内部調用defaultWriteObject()和defaultReadObject來選擇執行預設的writeObject()和readObject();如果打算使用預設機制寫入對象的非transient部分,那麼必須調用defaultwriteObject()和defaultReadObject(),且作為writeObject()和readObject()的第一個操作。
使用“持久性”
1. 隻要将任何對象序列化到單一流中,就可以恢複出與我們寫出時一樣的對象網,并且沒有任何意外重複複制出的對象。當然,我們可以在寫出第一個對象和寫出最後一個對象期間改變這些對象的狀态,但是這是我們自己的事;無論對象在被序列化時處于什麼狀态(無論它們和其他對象有什麼樣的連接配接關系),我們都可以被寫出。
2. Class是Serializable的,是以隻需要直接對Class對象序列化,就可以很容易的儲存static字段,任何情況下,這都是一種明智的做法。但是必須自己動手去實作序列化static的值。
使用serializeStaticState()和deserializeStaticState()兩個static方法,它們是作為存儲和讀取過程的一部分被顯示的調用的
3. 安全問題:序列化會将private資料儲存下來,對于你關心的安全問題,應将其标記為transient。但是這之後,你還必須設計一種安全的儲存資訊的方法,以便在執行恢複時可以複位那些private變量。