1. 引言
Yarn在Hadoop的生态系統中擔任了資源管理和任務排程的角色。在讨論其構造器之前先簡單了解一下Yarn的架構。
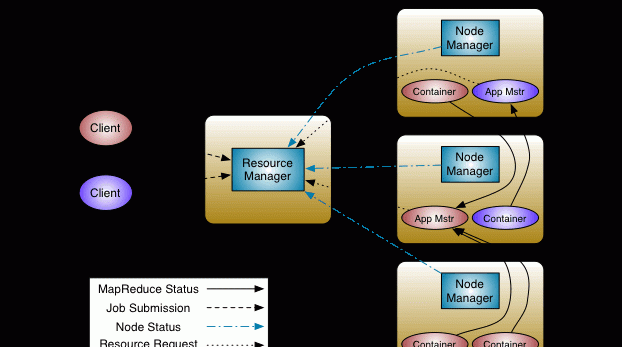
上圖是Yarn的基本架構,其中 ResourceManager 是整個架構的核心元件,負責叢集上的資源管理,包括記憶體、CPU以及叢集上的其他資; ApplicationMaster 負責在生命周期内的應用程式排程; NodeManager 負責本節點上資源的供給和隔離;Container 可以抽象的看成是運作任務的一個容器。本文讨論的排程器是在 ResourceManager 進行排程,接下來在了解一下 FIFO 排程器、Capacity 排程器、Fair 排程器三個排程器。
http://smartsi.club/2018/05/07/hadoop-scheduler-of-yarn/#2-FIFO%E8%B0%83%E5%BA%A6%E5%99%A8 2. FIFO排程器
上圖顯示了 FIFO 排程器的實作(執行過程示意圖)。FIFO 排程器是先進先出(First In First Out)排程器。FIFO 排程器是 Hadoop 使用最早的一種排程政策,可以簡單的将其了解為一個 Java 隊列,這就意味着在叢集中同時隻能有一個作業運作。所有的應用程式按照送出順序來執行,在上一個 Job 執行完成之後,下一個 Job 按照隊列中的順序執行。FIFO排程器以獨占叢集全部資源的方式來運作作業,這樣的好處是 Job 可以充分利用叢集的全部資源,但是對于運作時間短,優先級高或者互動式查詢類的MR Job 需要等待它之前的 Job 完成才能被執行,這也就導緻了如果前面有一個比較大的 Job 在運作,那麼後面的 Job 将會被阻塞。是以,雖然 FIFO 排程器實作簡單,但是并不能滿足很多實際場景的要求。這也就促使 Capacity 排程器和 Fair 排程器的誕生。
增加作業優先級的功能後,可以通過設定屬性或 JobClinet 的mapred.job.priority
方法來設定優先級。在作業排程器選擇要運作的下一個作業時,FIFO 排程器中不支援優先級搶占,是以高優先級的作業會受阻于前面已經開始,長時間運作的低優先級的作業。setJobPriority
http://smartsi.club/2018/05/07/hadoop-scheduler-of-yarn/#3-Capacity%E8%B0%83%E5%BA%A6%E5%99%A8 3. Capacity排程器
上圖顯示了 Capacity 排程器的實作(執行過程示意圖)。Capacity 排程器也稱之為容器排程器。可以将它了解為一個資源隊列。資源隊列需要使用者自己配置設定。例如因為 Job 需要要把整個叢集分成了AB兩個隊列,A隊列又可以繼續分,比如将A隊列再分為1和2兩個子隊列。那麼隊列的配置設定就可以參考下面的樹形結構:
|
上述的樹形結構可以了解為A隊列占用叢集全部資源的60%,B隊列占用40%。A隊列又分為1,2兩個子隊列,A.1占據40%,A.2占據60%,也就是說此時A.1和A.2分别占用A隊列的40%和60%的資源。雖然此時已經對叢集的資源進行了配置設定,但并不是說A送出了任務之後隻能使用叢集資源的60%,而B隊列的40%的資源處于空閑。隻要是其它隊列中的資源處于空閑狀态,那麼有任務送出的隊列就可以使用配置設定給空閑隊列的那些資源,使用的多少依據具體配置。參數的配置會在後文中提到。
http://smartsi.club/2018/05/07/hadoop-scheduler-of-yarn/#3-1-Capacity%E8%B0%83%E5%BA%A6%E5%99%A8%E7%9A%84%E7%89%B9%E6%80%A7 3.1 Capacity排程器的特性
(1) 階層化的隊列設計,這種階層化的隊列設計保證了子隊列可以使用父隊列的全部資源。這樣通過階層化的管理可以更容易配置設定和限制資源的使用。
(2) 容量,給隊列設定一個容量(資源占比),確定每個隊列不會占用叢集的全部資源。
(3) 安全,每個隊列都有嚴格的通路控制。使用者隻能向自己的隊列送出任務,不能修改或者通路其他隊列的任務。
(4) 彈性配置設定,可以将空閑資源配置設定給任何隊列。當多個隊列出現競争的時候,則會按照比例進行平衡。
(5) 多租戶租用,通過隊列的容量限制,多個使用者可以共享同一個叢集,colleagues 保證每個隊列配置設定到自己的容量,并且提高使用率。
(6) 可操作性,Yarn支援動态修改容量、權限等的配置設定,這些可以在運作時直接修改。還提供管理者界面,來顯示目前的隊列狀态。管理者可以在運作時添加隊列;但是不能删除隊列。管理者還可以在運作時暫停某個隊列,這樣可以保證目前隊列在執行期間不會接收其他任務。如果一個隊列被設定成了stopped,那麼就不能向他或者子隊列送出任務。
(7) 基于資源的排程,以協調不同資源需求的應用程式,比如記憶體、CPU、磁盤等等。
http://smartsi.club/2018/05/07/hadoop-scheduler-of-yarn/#3-2-Capacity%E8%B0%83%E5%BA%A6%E5%99%A8%E7%9A%84%E5%8F%82%E6%95%B0%E9%85%8D%E7%BD%AE 3.2 Capacity排程器的參數配置
(1)
capacity
:隊列的資源容量(百分比)。當系統非常繁忙時,應保證每個隊列的容量得到滿足,如果每個隊列應用程式較少,可與其他隊列共享剩餘資源。注意,所有隊列的容量之和應小于100。
(2)
maximum-capacity
:隊列的資源使用上限(百分比)。由于資源共享,是以一個隊列使用的資源量可能超過其容量,可以通過該參數來限制最多使用資源量。(這也是前文提到的隊列可以占用資源的最大百分比)
(3)
user-limit-factor
:每個使用者最多可使用的資源量(百分比)。比如,如果該值為30,那麼在任何時候每個使用者使用的資源量都不能超過該隊列容量的30%。
(4)
maximum-applications
:叢集中或者隊列中同時處于等待和運作狀态的應用程式數目上限(cluster or at the same time in a waiting in the queue and application number of the running condition limit),這是一個強限制,一旦叢集中應用程式數目超過該上限,後續送出的應用程式将被拒絕,預設值為 10000。所有隊列的數目上限可通過參數
yarn.scheduler.capacity.maximum-applications
設定(可看做預設值),而單個隊列可通過參數
yarn.scheduler.capacity.<queue-path>.maximum-applications
設定。
(5)
maximum-am-resource-percent
:叢集中用于運作應用程式 ApplicationMaster 的最大資源比例,該參數通常用于限制處于活動狀态的應用程式數目。該參數類型為浮點型,預設是0.1,表示10%。所有隊列的 ApplicationMaster 資源比例上限可通過參數
yarn.scheduler.capacity. maximum-am-resource-percent
yarn.scheduler.capacity.<queue-path>.maximum-am-resource-percent
(6)
state
:隊列狀态可以為 STOPPED 或者 RUNNING,如果一個隊列處于 STOPPED 狀态,使用者不可以将應用程式送出到該隊列或者它的子隊列中,類似的,如果 ROOT 隊列處于 STOPPED 狀态,使用者不可以向叢集中送出應用程式,但是處于 RUNNING 狀态的應用程式仍可以正常運作,以便隊列可以優雅地退出。
(7)
acl_submit_applications
:指定哪些Linux使用者/使用者組可向隊列送出應用程式。需要注意的是,該屬性具有繼承性,即如果一個使用者可以向某個隊列送出應用程式,那麼它可以向它的所有子隊列送出應用程式。配置該屬性時,使用者之間或使用者組之間用
,
分割,使用者和使用者組之間用空格分割,比如
user1,user2 group1,group2
。
(8)
acl_administer_queue
:指定隊列的管理者,管理者可控制該隊列的所有應用程式,例如殺死任意一個應用程式等。同樣,該屬性具有繼承性,如果一個使用者可以向某個隊列送出應用程式,則它可以向它的所有子隊列送出應用程式。
http://smartsi.club/2018/05/07/hadoop-scheduler-of-yarn/#4-Fair%E8%B0%83%E5%BA%A6%E5%99%A8 4. Fair排程器
上圖顯示了 Fair 排程器的實作(執行過程示意圖)。Fair 排程器也稱之為公平排程器。Fair 排程器是一種隊列資源配置設定方式,在整個時間線上,所有的 Job 平分資源。預設情況下,Fair 排程器隻是對記憶體資源做公平的排程和配置設定。當叢集中隻有一個任務在運作時,那麼此任務會占用叢集的全部資源。當有其他的任務送出後,那些釋放的資源将會被配置設定給新的 Job,是以每個任務最終都能擷取幾乎一樣多的資源。
Fair 排程器也可以在多個隊列上工作,如上圖所示,例如有兩個使用者A和B,他們分别擁有一個隊列。當A啟動一個 Job 而B沒有送出任何任務時,A會獲得叢集全部資源;當B啟動一個 Job 後,A的任務會繼續運作,不過隊列A會慢慢釋放它的一些資源,一會兒之後兩個任務會各自獲得叢集一半的資源。如果此時B再啟動第二個 Job 并且其它任務也還在運作時,那麼它将會和B隊列中的的第一個 Job 共享隊列B的資源,也就是隊列B的兩個 Job 會分别使用叢集四分之一的資源,而隊列A的 Job 仍然會使用叢集一半的資源,結果就是叢集的資源最終在兩個使用者之間平等的共享。
http://smartsi.club/2018/05/07/hadoop-scheduler-of-yarn/#4-1-Fair%E8%B0%83%E5%BA%A6%E5%99%A8%E5%8F%82%E6%95%B0%E9%85%8D%E7%BD%AE 4.1 Fair排程器參數配置
yarn.scheduler.fair.allocation.file
:
allocation
檔案的位置,
allocation
檔案是一個用來描述隊列以及它們屬性的配置檔案。這個檔案必須為格式嚴格的xml檔案。如果為相對路徑,那麼将會在classpath下查找此檔案(conf目錄下)。預設值為
fair-scheduler.xml
yarn.scheduler.fair.user-as-default-queue
:如果沒有指定隊列名稱時,是否将與
allocation
有關的 username 作為預設的隊列名稱。如果設定成 false(且沒有指定隊列名稱) 或者沒有設定,所有的 jobs 将共享
default
隊列。預設值為 true。
yarn.scheduler.fair.preemption
:是否使用搶占模式(優先權,搶占),預設為 fasle,在此版本中此功能為測試性的。
yarn.scheduler.fair.assignmultiple
:是在允許在一個心跳中發送多個容器配置設定資訊。預設值為 false。
yarn.scheduler.fair.max.assign
:如果
yarn.scheduler.fair.assignmultiple
為true,那麼在一次心跳中最多發送配置設定容器的個數。預設為-1,無限制。
yarn.scheduler.fair.locality.threshold.node
:0~1之間一個float值,表示在等待擷取滿足
node-local
條件的容器時,最多放棄不滿足
node-local
的容器機會次數,放棄的nodes個數為叢集的大小的比例。預設值為-1.0表示不放棄任何排程的機會。
yarn.scheduler.fair.locality.threashod.rack
:同上,滿足
rack-local
yarn.scheduler.fair.sizebaseweight
:是否根據應用程式的大小(Job的個數)作為權重。預設為 false,如果為 true,那麼複雜的應用程式會擷取更多的資源。
http://smartsi.club/2018/05/07/hadoop-scheduler-of-yarn/#5-%E6%80%BB%E7%BB%93 5. 總結
如果業務邏輯比較簡單或者剛接觸 Hadoop 的時建議使用 FIFO 排程器;如果需要控制部分應用程式的優先級,同時又想要充分利用叢集資源的情況下,建議使用 Capacity 排程器;如果想要多使用者或者多隊列公平的共享叢集資源,那麼就選用Fair排程器。希望大家能夠根據業務所需選擇合适的排程器。
原文:http://smartsi.club/2018/05/07/hadoop-scheduler-of-yarn/
![Ambari介紹和架構原理[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)