計算機視覺領域最全彙總 (第1部分)
7、紋理生成(Texture
Synthesis)與風格遷移(Style Transform)
紋理生成用于生成包含相同紋理的較大圖像。給定正常圖像和包含特定風格的圖像,然後通過風格遷移不僅保留圖像的原始内容,而且将該圖像轉換為指定的風格。
7.1:特征反演(Feature Inversion)
特征反演是紋理生成和風格遷移背後的核心概念。給定一個中間層特征,我們希望疊代來建立與給定特征類似圖像。特征反演還可以告訴我們在中間層特征中包含多少圖像資訊。
給定DxHxW的深度卷積特征,我們将它們轉換為Dx(HW)矩陣X,是以我們可以将對應Gram矩陣定義為:G = XX ^ T
通過外積,Gram矩陣捕獲不同特征之間的關系。
7.2:紋理生成的概念
它對給定紋理圖案的Gram矩陣進行特征逆向工程。使生成圖像的各層特征的Gram矩陣接近給定紋理圖像的各層Gram。低層特征傾向于捕獲細節資訊,而高層特征可以捕獲更大面積的特征。
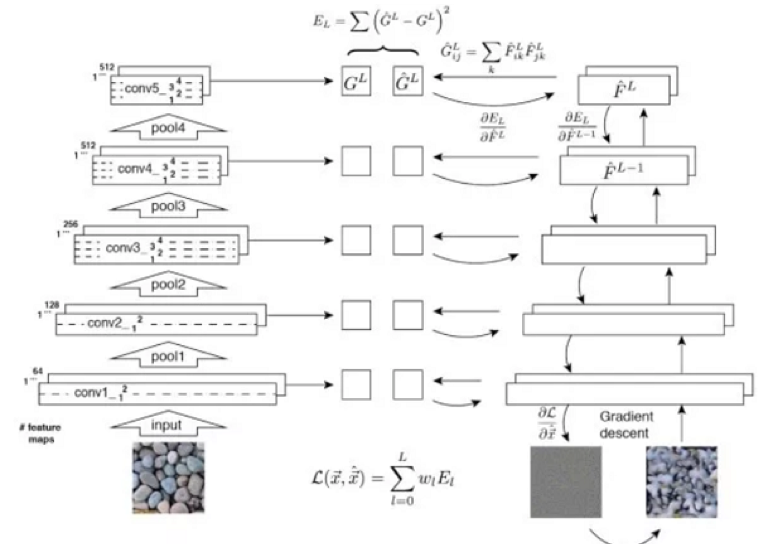
7.3:風格遷移的概念
此優化有兩個主要目标:第一個是使生成的圖像的内容更接近原始圖像的内容,而第二個是使生成的圖像的風格與指定的風格比對。風格由Gram矩陣展現,而内容直接由神經元的激活值展現。

7.4:直接生成風格遷移的圖像
上面直接生成風格遷移的圖像的方法的缺點是需要多次疊代才能收斂。解決該問題的方案是訓練一個神經網絡來直接生成風格遷移的圖像。一旦訓練結束,進行風格遷移隻需前饋網絡一次,十分高效。在訓練時,将生成圖像、原始圖像、風格圖像三者前饋一固定網絡以提取不同層特征用于計算損失函數。
實驗證明,通過使用執行個體歸一化,風格變換網絡可以移除與圖像相關的比較資訊以簡化生成過程。
7.5:條件示例規範化
上述方法的一個問題是我們必須為每種不同的風格訓練一個單獨的模型。由于不同的風格有時包含相似性,是以可以通過在不同風格的風格變換網絡之間共享參數來完成這項工作。具體來說,它更改了風格轉換網絡的示例規範化,使其具有N組縮放和平移參數,每個組對應于特定風格。這樣我們就可以從單個前饋過程中獲得N個風格的變換圖像。
8、面部驗證/識别
人臉驗證/識别可以認為是一種更加精細的細粒度圖像識别任務。人臉驗證是給定兩張圖像、判斷其是否屬于同一個人,而人臉識别是回答圖像中的人是誰。一個人臉驗證/識别系統通常包括三大步:檢測圖像中的人臉,特征點定位、及對人臉進行驗證/識别。人臉驗證/識别的難題在于需要進行小樣本學習。通常情況下,資料集中每人隻有對應的一張圖像,這稱為一次性學習(one-shot learning)。
8.1:面部識别系統背後的概念
作為分類問題(非常多的類别數),或作為度量學習的問題。如果兩個圖像屬于同一個人,那麼我們希望它們的深層特征非常相似。否則,它們的特征應該不同。之後,根據深度特征之間的距離進行驗證或識别(k最近鄰居分類)。
8.2:DeepFace
第一個成功将深度神經網絡應用于面部驗證/識别模型的系統。DeepFace使用非共享參數局部性連接配接。這是因為人臉的不同部分具有不同的特征(例如眼睛和嘴唇具有不同的特征),是以傳統卷積層的經典“共享參數”不适用于面部驗證。是以,面部識别網絡使用非共享參數局部性連接配接。它使用的孿生(Siamese network)網絡用于面部驗證。當兩個圖像的深度特征小于給定門檻值時,它們被認為是同一個人。
8.3:FaceNet
FaceNet通過三因子輸入,希望負樣本之間的距離大于正樣本之間的距離給定量。此外,三個輸入因子并不是随機的,否則,因為負樣本的差異樣本太大,網絡将無法學習。選擇最具挑戰性的三個元素組(例如最遠的正樣本和最接近的負樣本)會使該網絡陷入局部最優。FaceNet使用半困難政策,選擇比正樣本更遠的負樣本。
8.4:大區間交叉熵損失
近年來,這一直是一個熱門的研究課題。由于類内波動大而類間相似度高,有研究工作旨在提升經典的交叉熵損失對深度特征的判斷能力。例如,L-Softmax加強優化目标,使對應類别的參數向量和深度特征夾角增大。
A-Softmax進一步限制L-Softmax的參數向量長度為1,使訓練更集中到優化深度特征和夾角上。實際中,L-Softmax和A-Softmax都很難收斂,訓練時采用了退火方法,從标準softmax逐漸退火至L-Softmax或A-Softmax。
8.5:實時檢測
該系統确定面部圖像是來自真人還是來自照片,這是面部驗證/識别任務的關鍵障礙。目前在業界流行的一些方法是讀取人的面部表情,紋理資訊,眨眼或要求使用者完成一系列動作的變化。
9、圖像搜尋和檢索
給定一個包含特定執行個體(例如特定目标,場景或建築物)的圖像,圖像搜尋用于在資料庫中查找包含與給定執行個體類似的元素的圖像。然而,由于兩個圖像中的角度,光照和障礙物通常不相同,是以建立能夠處理圖像類别中的這些差異的搜尋算法的問題對研究人員構成了重大挑戰。
9.1:經典圖像搜尋的過程
首先,我們必須從圖像中提取适當的代表性矢量。其次,将歐氏距離或餘弦距離應用于這些矢量以執行最近鄰居搜尋并找到最相似的圖像。最後,我們使用特定的處理技術對搜尋結果進行小幅調整。我們可以看到圖像搜尋引擎性能的限制因素是圖像的表示:
9.2:無監督的圖像搜尋
無監督圖像搜尋使用預先訓練的ImageNet模型,沒有外部資訊作為特征提取引擎來提取圖像的表示。
- 直覺的思路:因為深度全連接配接特征提供了圖像的進階描述,并且是一個“自然”矢量,直覺的思維過程是直接提取深度全連接配接特征作為圖像的代表矢量。但是,由于圖像分類中使用完全連接配接的特征缺乏對圖像的較長的描述,是以該思維過程僅産生平均準确度。
- 使用深度卷積特征:因為深度卷積具有更好的詳細資訊,并且可以用于處理任何大小的圖像,目前流行的方法是提取深度卷積特征,然後使用權重全局搜尋和求和池來獲得圖像的代表向量。權重表示不同位置的特征的必要性,并且可以采用空間矢量權重或信道矢量權重的形式。
- CroW:深度卷積特征是一種分布式表示。盡管來自神經元的響應值在确定區域是否有目标方面不是非常有用,但如果多個神經元同時具有大量反應,那麼該區域很可能包含目标。是以,CroW沿着通道添加了特征圖以獲得二維合成圖,對其進行标準化,并根據數量标準化的結果将其用作空間權重。CroW的通道權重由特征圖的稀疏性決定,類似于TF-IDF中的IDF特征,自然語言進行中的特征可用于提升不常見但具有高度确定性的特征。
- 類權重特征:該方法嘗試利用圖像內建網絡的類别預測資訊使空間權重更具确定性。具體地,它使用CAM來獲得預訓練網絡中每個類别的最具代表性的區域的語義資訊;然後它使用标準化的CAM結果作為空間權重。
- PWA:PWA發現,深度卷積特征的不同通道對應于目标上不同區域的響應。是以,PWA可以選擇一系列确定性特征映射,并将其标準化結果用作收斂的空間權重。然後系統級聯結果以形成最終圖像的表示。
9.3:有監督圖像搜尋
有監督圖像搜尋首先采用預先訓練的ImageNet模型并将其調整到另一個訓練資料集上。然後,它從這個調整的模型中提取圖像表示。為了獲得更好的結果,用于優化模型的訓練資料集通常類似于搜尋資料集。此外,我們可以使用候選區域網絡從可能包含目标的圖像中提取前景區域。
孿生網絡:類似于人臉識别的思想,該系統使用兩個元素或三個元素輸入(++ -)來訓練模型,以最小化兩個樣本之間的距離,并最大化兩個不同樣本之間的距離。
9.4:對象跟蹤
對象跟蹤的目标是跟蹤視訊中目标的移動。通常,目标位于視訊的第一幀中并由框标記。我們需要預測框在下一幀中的位置。對象跟蹤與目标測試類似。然而,對象跟蹤的難點在于我們不知道我們跟蹤哪個目标。是以,我們無法在任務之前收集足夠的訓練資料并訓練專門的測試。
9.5:孿生網絡
類似于面部驗證的概念,利用孿生網絡可以在一條線上的目标框内輸入圖像,并且在另一條線上輸入候選圖像區域,然後輸出兩個圖像之間的相似度。我們不需要周遊不同幀中的所有其他候選區域;相反,我們可以使用卷積網絡,隻需要将每個圖像前饋一次,通過卷積,我們可以獲得二維的響應圖,其中最重要的響應位置确定了框的位置。基于孿生網絡的方法非常快并且能夠處理任何大小的圖像。
9.6:CFNet
相關濾波器訓練線性模闆以區分圖像區域和它們周圍的區域,然後使用傅立葉變換。CFNet與離線訓練的孿生網絡和相關的線上濾波模闆相結合,能夠提高權重網絡的跟蹤性能。
10、生成式模型(generative
models)
這種類型的模型用于學習資料(圖像)的分布或從其分布中采樣新圖像。生成模型可用于超分辨率重建、圖像着色、圖像轉換、從文本生成圖像、學習隐藏的圖像表示、半監督學習等。此外,生成式模型可以與強化學習相結合,用于模拟和逆強化學習。
10.1:顯式模組化
使用條件機率的公式來對圖像的分布進行最大似然估計并從中學習。該方法的缺點在于,由于每個圖像中的像素取決于先前的像素,是以必須在一個角開始并以有序的方式進行,是以生成圖像的過程将稍微緩慢。例如,WaveNet可以産生類似于人類建立的語音,但由于它不能同時産生,一秒鐘的語音需要2分鐘來計算,并且實時生成是不可能的。
10.2:變分自編碼器
為了避免顯式模組化的缺陷,變分自編碼器對資料分布進行了隐式模組化。它認為生成圖像受隐藏變量控制的影響,并假設隐藏變量受到對角高斯分布的影響。
變分自編碼器使用解碼網絡根據隐藏變量生成圖像。由于我們無法直接應用最大似然估計,是以在訓練時,類似于EM算法,變分自編碼器構造似然函數的下界函數,然後使用該下界函數進行優化。變分自編碼器的好處是因為每個次元的獨立性;我們可以通過控制隐藏變量來控制影響輸出圖像變化的因素。
10.3:生成對抗式網絡(GAN)
由于學習資料分布極其困難,生成對抗式網絡完全避免了這一步驟并立即生成圖像。生成對抗式網絡使用生成網絡G從随機噪聲建立圖像,并使用判别網絡D來确定輸入圖像是真實的還是僞造的。
在訓練期間,判别網絡D的目标是确定圖像是真實的還是僞造的,并且生成式網絡G的目的是使判别網絡D傾向于确定其輸出圖像是真實的。在實踐中,訓練生成式對抗網絡會帶來模型崩潰的問題,其中生成對抗式網絡無法學習完整的資料分布。這在LS-GAN和W-GAN中産生了改進,與變分自編碼器一樣,生成對抗式網絡提供更好的詳細資訊。
11、視訊分類
上述大多數任務都可以用于視訊分類,這裡我們将以視訊分類為例來說明處理視訊資料的一些基本方法。
11.1:多幀圖像特征彙合
這類方法将視訊視為一系列幀圖像,網絡接收屬于視訊的一組多幀圖像(例如15幀),然後從這些圖像中提取深度特征,并最終內建這些圖像特征以獲得視訊的該部分的特征以對其進行分類。實驗表明,使用“慢速融合(slow fusion)”效果最佳。此外,獨立組織單個幀也可以得到非常有競争力的結果,這意味着來自單個幀的圖像包含大量相關資訊。
11.2:三維卷積
将标準的二維卷積擴充為三維卷積,以在時間次元上連接配接局部。例如,系統可以采用VGG 3x3卷積并将其擴充為3x3x3卷積或2x2收斂擴充為2x2x2收斂。
11.3:圖像+序列兩個分支結構
這種類型的方法使用兩個獨立的網絡來區分從視訊捕獲的圖像資訊和時間資訊。圖像資訊可以從單幀中的靜止圖像獲得,并且是圖像分類的經典問題。然後通過光流獲得運動資訊,跟蹤目标在相鄰幀上的運動。
11.4:CNN + RNN捕獲遠端依賴關系
先前的方法僅能夠捕獲幾幀圖像之間的依賴關系。此方法使用CNN從單個幀中提取圖像特征,然後使用RNN捕獲幀之間的依賴關系。
此外,研究人員已嘗試将CNN和RNN結合起來,以便每個卷積層能夠捕獲遠距離依賴性。
以上為譯文。
本文由
阿裡雲雲栖社群組織翻譯。
文章原标題《deep-dive-into-computer-vision-with-neural-network-2》,
作者:
Leona Zhang譯者:虎說八道,審校:。
文章為簡譯,更為詳細的内容,請檢視
原文。