演變與redis-cluster群集讀寫方案
導言
redis-cluster是近年來redis架構不斷改進中的相對較好的redis高可用方案。本文涉及到近年來redis多執行個體架構的演變過程,包括普通主從架構(Master、slave可進行寫讀分離)、哨兵模式下的主從架構、redis-cluster高可用架構(redis官方預設cluster下不進行讀寫分離)的簡介。同時還介紹使用Java的兩大redis用戶端:Jedis與Lettuce用于讀寫redis-cluster的資料的一般方法。再通過官方文檔以及網際網路的相關技術文檔,給出redis-cluster架構下的讀寫能力的優化方案,包括官方的推薦的擴充redis-cluster下的Master數量以及非官方預設的redis-cluster的讀寫分離方案,案例中使用Lettuce的特定方法進行redis-cluster架構下的資料讀寫分離。
近年來redis多執行個體用架構的演變過程
redis是基于記憶體的高性能key-value資料庫,若要讓redis的資料更穩定安全,需要引入多執行個體以及相關的高可用架構。而近年來redis的高可用架構亦不斷改進,先後出現了本地持久化、主從備份、哨兵模式、redis-cluster群集高可用架構等等方案。
1、redis普通主從模式
通過持久化功能,Redis保證了即使在伺服器重新開機的情況下也不會損失(或少量損失)資料,因為持久化會把記憶體中資料儲存到硬碟上,重新開機會從硬碟上加載資料。 。但是由于資料是存儲在一台伺服器上的,如果這台伺服器出現硬碟故障等問題,也會導緻資料丢失。為了避免單點故障,通常的做法是将資料庫複制多個副本以部署在不同的伺服器上,這樣即使有一台伺服器出現故障,其他伺服器依然可以繼續提供服務。為此, Redis 提供了複制(replication)功能,可以實作當一台資料庫中的資料更新後,自動将更新的資料同步到其他資料庫上。
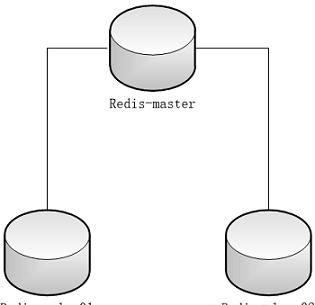
在複制的概念中,資料庫分為兩類,一類是主資料庫(master),另一類是從資料庫(slave)。主資料庫可以進行讀寫操作,當寫操作導緻資料變化時會自動将資料同步給從資料庫。而從資料庫一般是隻讀的,并接受主資料庫同步過來的資料。一個主資料庫可以擁有多個從資料庫,而一個從資料庫隻能擁有一個主資料庫。
主從模式的配置,一般隻需要再作為slave的redis節點的conf檔案上加入“slaveof masterip masterport”, 或者作為slave的redis節點啟動時使用如下參考指令:
redis-server --port 6380 --slaveof masterIp masterPort redis的普通主從模式,能較好地避免單獨故障問題,以及提出了讀寫分離,降低了Master節點的壓力。網際網路上大多數的對redis讀寫分離的教程,都是基于這一模式或架構下進行的。但實際上這一架構并非是目前最好的redis高可用架構。
2、redis哨兵模式高可用架構
當主資料庫遇到異常中斷服務後,開發者可以通過手動的方式選擇一個從資料庫來升格為主資料庫,以使得系統能夠繼續提供服務。然而整個過程相對麻煩且需要人工介入,難以實作自動化。 為此,Redis 2.8開始提供了哨兵工具來實作自動化的系統監控和故障恢複功能。 哨兵的作用就是監控redis主、從資料庫是否正常運作,主出現故障自動将從資料庫轉換為主資料庫。
顧名思義,哨兵的作用就是監控Redis系統的運作狀況。它的功能包括以下兩個。
(1)監控主資料庫和從資料庫是否正常運作。
(2)主資料庫出現故障時自動将從資料庫轉換為主資料庫。

可以用info replication檢視主從情況 例子: 1主2從 1哨兵,可以用指令起也可以用配置檔案裡 可以使用雙哨兵,更安全,參考指令如下:
redis-server --port 6379
redis-server --port 6380 --slaveof 192.168.0.167 6379
redis-server --port 6381 --slaveof 192.168.0.167 6379
redis-sentinel sentinel.conf 其中,哨兵配置檔案sentinel.conf參考如下:
sentinel monitor mymaster 192.168.0.167 6379 1 其中mymaster表示要監控的主資料庫的名字。配置哨兵監控一個系統時,隻需要配置其監控主資料庫即可,哨兵會自動發現所有複制該主資料庫的從資料庫。
Master與slave的切換過程:
(1)slave leader更新為master
(2)其他slave修改為新master的slave
(3)用戶端修改連接配接
(4)老的master如果重新開機成功,變為新master的slave
3、redis-cluster群集高可用架構
即使使用哨兵,redis每個執行個體也是全量存儲,每個redis存儲的内容都是完整的資料,浪費記憶體且有木桶效應。為了最大化利用記憶體,可以采用cluster群集,就是分布式存儲。即每台redis存儲不同的内容。
采用redis-cluster架構正是滿足這種分布式存儲要求的叢集的一種展現。redis-cluster架構中,被設計成共有16384個hash slot。每個master分得一部分slot,其算法為:hash_slot = crc16(key) mod 16384 ,這就找到對應slot。采用hash slot的算法,實際上是解決了redis-cluster架構下,有多個master節點的時候,資料如何分布到這些節點上去。key是可用key,如果有{}則取{}内的作為可用key,否則整個可以是可用key。群集至少需要3主3從,且每個執行個體使用不同的配置檔案。
在redis-cluster架構中,redis-master節點一般用于接收讀寫,而redis-slave節點則一般隻用于備份,其與對應的master擁有相同的slot集合,若某個redis-master意外失效,則再将其對應的slave進行更新為臨時redis-master。
在redis的官方文檔中,對redis-cluster架構上,有這樣的說明:在cluster架構下,預設的,一般redis-master用于接收讀寫,而redis-slave則用于備份,當有請求是在向slave發起時,會直接重定向到對應key所在的master來處理。但如果不介意讀取的是redis-cluster中有可能過期的資料并且對寫請求不感興趣時,則亦可通過readonly指令,将slave設定成可讀,然後通過slave擷取相關的key,達到讀寫分離。具體可以參閱redis官方文檔(
https://redis.io/commands/readonly)等相關内容:
Enables read queries for a connection to a Redis Cluster slave node.
Normally slave nodes will redirect clients to the authoritative master for the hash slot involved in a given command, however clients can use slaves in order to scale reads using the READONLY command.
READONLY tells a Redis Cluster slave node that the client is willing to read possibly stale data and is not interested in running write queries.
When the connection is in readonly mode, the cluster will send a redirection to the client only if the operation involves keys not served by the slave's master node. This may happen because:
The client sent a command about hash slots never served by the master of this slave.
The cluster was reconfigured (for example resharded) and the slave is no longer able to serve commands for a given hash slot. 例如,我們假設已經建立了一個三主三從的redis-cluster架構,其中A、B、C節點都是redis-master節點,A1、B1、C1節點都是對應的redis-slave節點。在我們隻有master節點A,B,C的情況下,對應redis-cluster如果節點B失敗,則群集無法繼續,因為我們沒有辦法再在節點B的所具有的約三分之一的hash slot集合範圍内提供相對應的slot。然而,如果我們為每個主伺服器節點添加一個從伺服器節點,以便最終叢集由作為主伺服器節點的A,B,C以及作為從伺服器節點的A1,B1,C1組成,那麼如果節點B發生故障,系統能夠繼續運作。節點B1複制B,并且B失效時,則redis-cluster将促使B的從節點B1作為新的主伺服器節點并且将繼續正确地操作。但請注意,如果節點B和B1在同一時間發生故障,則Redis群集無法繼續運作。
Redis群集配置參數:在繼續之前,讓我們介紹一下Redis Cluster在redis.conf檔案中引入的配置參數。有些指令的意思是顯而易見的,有些指令在你閱讀下面的解釋後才會更加清晰。
(1)cluster-enabled :如果想在特定的Redis執行個體中啟用Redis群集支援就設定為yes。 否則,執行個體通常作為獨立執行個體啟動。
(2)cluster-config-file :請注意,盡管有此選項的名稱,但這不是使用者可編輯的配置檔案,而是Redis群集節點每次發生更改時自動保留群集配置(基本上為狀态)的檔案。
(3)cluster-node-timeout :Redis群集節點可以不可用的最長時間,而不會将其視為失敗。 如果主節點超過指定的時間不可達,它将由其從屬裝置進行故障切換。
(4)cluster-slave-validity-factor :如果設定為0,無論主裝置和從裝置之間的鍊路保持斷開連接配接的時間長短,從裝置都将嘗試故障切換主裝置。 如果該值為正值,則計算最大斷開時間作為節點逾時值乘以此選項提供的系數,如果該節點是從節點,則在主鍊路斷開連接配接的時間超過指定的逾時值時,它不會嘗試啟動故障切換。
(5)cluster-migration-barrier :主裝置将保持連接配接的最小從裝置數量,以便另一個從裝置遷移到不受任何從裝置覆寫的主裝置。有關更多資訊,請參閱本教程中有關副本遷移的相應部分。
(6)cluster-require-full-coverage :如果将其設定為yes,則預設情況下,如果key的空間的某個百分比未被任何節點覆寫,則叢集停止接受寫入。 如果該選項設定為no,則即使隻處理關于keys子集的請求,群集仍将提供查詢。
以下是最小的Redis叢集配置檔案:
port 7000
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes 注意:
(1)redis-cluster最小配置為三主三從,當1個主故障,大家會給對應的從投票,把從立為主,若沒有從資料庫可以恢複則redis群集就down了。
(2)在這個redis cluster中,如果你要在slave讀取資料,那麼需要帶上readonly指令。redis cluster的核心的理念,主要是用slave做高可用的,每個master挂一兩個slave,主要是做資料的熱備,當master故障時的作為主備切換,實作高可用的。redis cluster預設是不支援slave節點讀或者寫的,跟我們手動基于replication搭建的主從架構不一樣的。slave node要設定readonly,然後再get,這個時候才能在slave node進行讀取。對于redis -cluster主從架構,若要進行讀寫分離,官方其實是不建議的,但也能做,隻是會複雜一些。具體見下面的章節。
(3)redis-cluster的架構下,實際上本身master就是可以任意擴充的,你如果要支撐更大的讀吞吐量,或者寫吞吐量,或者資料量,都可以直接對master進行橫向擴充就可以了。也擴容master,跟之前擴容slave進行讀寫分離,效果是一樣的或者說更好。
(4)可以使用自帶用戶端連接配接:使用redis-cli -c -p cluster中任意一個端口,進行資料擷取測試。
Java中對redis-cluster資料的一般讀取方法簡介
使用Jedis讀寫redis-cluster的資料
由于Jedis類一般隻能對一台redis-master進行資料操作,是以面對redis-cluster多台master與slave的群集,Jedis類就不能滿足了。這個時候我們需要引用另外一個操作類:JedisCluster類。
例如我們有6台機器組成的redis-cluster:
172.20.52.85:7000、 172.20.52.85:7001、172.20.52.85:7002、172.20.52.85:7003、172.20.52.85:7004、172.20.52.85:7005
其中master機器對應端口:7000、7004、7005
slave對應端口:7001、7002、7003
使用JedisCluster對redis-cluster進行資料操作的參考代碼如下:
// 添加nodes服務節點到Set集合
Set<HostAndPort> hostAndPortsSet = new HashSet<HostAndPort>();
// 添加節點
hostAndPortsSet.add(new HostAndPort("172.20.52.85", 7000));
hostAndPortsSet.add(new HostAndPort("172.20.52.85", 7001));
hostAndPortsSet.add(new HostAndPort("172.20.52.85", 7002));
hostAndPortsSet.add(new HostAndPort("172.20.52.85", 7003));
hostAndPortsSet.add(new HostAndPort("172.20.52.85", 7004));
hostAndPortsSet.add(new HostAndPort("172.20.52.85", 7005));
// Jedis連接配接池配置
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
jedisPoolConfig.setMaxIdle(100);
jedisPoolConfig.setMaxTotal(500);
jedisPoolConfig.setMinIdle(0);
jedisPoolConfig.setMaxWaitMillis(2000); // 設定2秒
jedisPoolConfig.setTestOnBorrow(true);
JedisCluster jedisCluster = new JedisCluster(hostAndPortsSet ,jedisPoolConfig);
String result = jedisCluster.get("event:10");
System.out.println(result); 運作結果截圖如下圖所示:
第一節中我們已經介紹了redis-cluster架構下master提供讀寫功能,而slave一般隻作為對應master機器的資料備份不提供讀寫。如果我們隻在hostAndPortsSet中隻配置slave,而不配置master,實際上還是可以讀到資料,但其内部操作實際是通過slave重定向到相關的master主機上,然後再将結果擷取和輸出。
上面是普通項目使用JedisCluster的簡單過程,若在spring boot項目中,可以定義JedisConfig類,使用@Configuration、@Value、@Bean等一些列注解完成JedisCluster的配置,然後再注入該JedisCluster到相關service邏輯中引用,這裡介紹略。
使用Lettuce讀寫redis-cluster資料
Lettuce 和 Jedis 的定位都是Redis的client。Jedis在實作上是直接連接配接的redis server,如果在多線程環境下是非線程安全的,這個時候隻有使用連接配接池,為每個Jedis執行個體增加實體連接配接,每個線程都去拿自己的 Jedis 執行個體,當連接配接數量增多時,實體連接配接成本就較高了。
Lettuce的連接配接是基于Netty的,連接配接執行個體(StatefulRedisConnection)可以在多個線程間并發通路,應為StatefulRedisConnection是線程安全的,是以一個連接配接執行個體(StatefulRedisConnection)就可以滿足多線程環境下的并發通路,當然這個也是可伸縮的設計,一個連接配接執行個體不夠的情況也可以按需增加連接配接執行個體。
其中spring boot 2.X版本中,依賴的spring-session-data-redis已經預設替換成Lettuce了。
同樣,例如我們有6台機器組成的redis-cluster:
在spring boot 2.X版本中使用Lettuce操作redis-cluster資料的方法參考如下:
(1)pom檔案參考如下:
parent中指出spring boot的版本,要求2.X以上:
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.0.4.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent> 依賴中需要加入spring-boot-starter-data-redis,參考如下:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency> (2)springboot的配置檔案要包含如下内容:
spring.redis.database=0
spring.redis.lettuce.pool.max-idle=10
spring.redis.lettuce.pool.max-wait=500
spring.redis.cluster.timeout=1000
spring.redis.cluster.max-redirects=3
spring.redis.cluster.nodes=172.20.52.85:7000,172.20.52.85:7001,172.20.52.85:7002,172.20.52.85:7003,172.20.52.85:7004,172.20.52.85:7005 (3)建立RedisConfiguration類,參考代碼如下:
@Configuration
public class RedisConfiguration {
[@Resource](https://my.oschina.net/u/929718)
private LettuceConnectionFactory myLettuceConnectionFactory;
@Bean
public RedisTemplate<String, Serializable> redisTemplate() {
RedisTemplate<String, Serializable> template = new RedisTemplate<>();
template.setKeySerializer(new StringRedisSerializer());
//template.setValueSerializer(new GenericJackson2JsonRedisSerializer());
template.setValueSerializer(new StringRedisSerializer());
template.setConnectionFactory(myLettuceConnectionFactory);
return template;
}
} (4)建立RedisFactoryConfig類,參考代碼如下:
@Configuration
public class RedisFactoryConfig {
@Autowired
private Environment environment;
@Bean
public RedisConnectionFactory myLettuceConnectionFactory() {
Map<String, Object> source = new HashMap<String, Object>();
source.put("spring.redis.cluster.nodes", environment.getProperty("spring.redis.cluster.nodes"));
source.put("spring.redis.cluster.timeout", environment.getProperty("spring.redis.cluster.timeout"));
source.put("spring.redis.cluster.max-redirects", environment.getProperty("spring.redis.cluster.max-redirects"));
RedisClusterConfiguration redisClusterConfiguration;
redisClusterConfiguration = new RedisClusterConfiguration(new MapPropertySource("RedisClusterConfiguration", source));
return new LettuceConnectionFactory(redisClusterConfiguration);
}
} (5)在業務類service中注入Lettuce相關的RedisTemplate,進行相關操作。以下是我化簡到了springbootstarter中進行,參考代碼如下:
@SpringBootApplication
public class NewRedisClientApplication {
public static void main(String[] args) {
ApplicationContext context = SpringApplication.run(NewRedisClientApplication.class, args);
RedisTemplate redisTemplate = (RedisTemplate)context.getBean("redisTemplate");
String rtnValue = (String)redisTemplate.opsForValue().get("event:10");
System.out.println(rtnValue);
}
} 運作結果的截圖如下:
以上的介紹,是采用Jedis以及Lettuce對redis-cluster資料的簡單讀取。Jedis也好,Lettuce也好,其對于redis-cluster架構下的資料的讀取,都是預設是按照redis官方對redis-cluster的設計,自動進行重定向到master節點中進行的,哪怕是我們在配置中列出了所有的master節點和slave節點。查閱了Jedis以及Lettuce的github上的源碼,預設不支援redis-cluster下的讀寫分離,可以看出Jedis若要支援redis-cluster架構下的讀寫分離,需要自己改寫和建構多一些包裝類,定義好Master和slave節點的邏輯;而Lettuce的源碼中,實際上預留了方法(setReadForm(ReadFrom.SLAVE))進行redis-cluster架構下的讀寫分離,相對來說修改會簡單一些,具體可以參考後面的章節。
redis-cluster架構下的讀寫能力的優化方案
在上面的一些章節中,已經有講到redis近年來的高可用架構的演變,以及在redis-cluster架構下,官方對redis-master、redis-slave的其實有使用上的建議,即redis-master節點一般用于接收讀寫,而redis-slave節點則一般隻用于備份,其與對應的master擁有相同的slot集合,若某個redis-master意外失效,則再将其對應的slave進行更新為臨時redis-master。但如果不介意讀取的是redis-cluster中有可能過期的資料并且對寫請求不感興趣時,則亦可通過readonly指令,将slave設定成可讀,然後通過slave擷取相關的key,達到讀寫分離。
具體可以參閱redis官方文檔(
),以下是reids線上文檔中,對slave的readonly說明内容:
實際上本身master就是可以任意擴充的,是以如果要支撐更大的讀吞吐量,或者寫吞吐量,或者資料量,都可以直接對master進行橫向水準擴充就可以了。也就是說,擴容master,跟之前擴容slave并進行讀寫分離,效果是一樣的或者說更好。
是以下面我們将按照redis-cluster架構下分别進行水準擴充Master,以及在redis-cluster架構下對master、slave進行讀寫分離兩套方案進行講解。
(一)水準擴充Master執行個體來進行redis-cluster性能的提升
redis官方線上文檔以及一些網際網路的參考資料都表明,在redis-cluster架構下,實際上不建議做實體的讀寫分離。那麼如果我們真的不做讀寫分離的話,能否通過簡單的方法進行redis-cluster下的性能的提升?我們可以通過master的水準擴充,來橫向擴充讀寫吞吐量,并且能支撐更多的海量資料。
對master進行水準擴充有兩種方法,一種是單機上面進行master執行個體的增加(建議每新增一個master,也新增一個對應的slave),另一種是新增機器部署新的master執行個體(同樣建議每新增一個master,也新增一個對應的slave)。當然,我們也可以進行這兩種方法的有效結合。
(1)單機上通過多線程建立新redis-master執行個體,即邏輯上的水準擴充:
一般的,對于redis單機,單線程的讀吞吐是4w/s~5W/s,寫吞吐為2w/s。
單機合理開啟redis多線程情況下(一般線程數為CPU核數的倍數),總吞吐量會有所上升,但每個線程的平均處理能力會有所下降。例如一個2核CPU,開啟2線程的時候,總讀吞吐能上升是6W/s~7W/s,即每個線程平均約3W/s再多一些。但過多的redis線程反而會限制了總吞吐量。
(2)擴充更多的機器,部署新redis-master執行個體,即實體上的水準擴充:
例如,我們可以再原來隻有3台master的基礎上,連入新機器繼續新執行個體的部署,最終水準擴充為6台master(建議每新增一個master,也新增一個對應的slave)。例如之前每台master的處理能力假設是讀吞吐5W/s,寫吞吐2W/s,擴充前一共的處理能力是:15W/s讀,6W/s寫。如果我們水準擴充到6台master,讀吞吐可以達到總量30W/s,寫可以達到12w/s,性能能夠成倍增加。
(3)若原本每台部署redis-master執行個體的機器都性能良好,則可以通過上述兩者的結合,進行一個更優的組合。
使用該方案進行redis-cluster性能的提升的優點有:
(1)符合redis官方要求和資料的準确性。
(2)真正達到更大吞吐量的性能擴充。
(3)無需代碼的大量更改,隻需在配置檔案中重新配置新的節點資訊。
當然缺點也是有的:
(1)需要新增機器,提升性能,即成本會增加。
(2)若不新增機器,則需要原來的執行個體所運作的機器性能較好,能進行以多線程的方式部署新執行個體。但随着線程的增多,而機器的能力不足以支撐的時候,實際上總體能力會提升不太明顯。
(3)redis-cluster進行新的水準擴容後,需要對master進行新的hash slot重新配置設定,這相當于需要重新加載所有的key,并按算法平均配置設定到各個Master的slot當中。
(二)引入Lettuce以及修改相關方法,達到對redis-cluster的讀寫分離
通過上面的一些章節,我們已經可以了解到Lettuce用戶端讀取redis的一些操作,使用Lettuce能展現出了簡單,安全,高效。實際上,查閱了Lettuce對redis的讀寫,許多地方都進行了redis的讀寫分離。但這些都是基于上述redis架構中最普通的主從分離架構下的讀寫分離,而對于redis-cluster架構下,Lettuce可能是遵循了redis官方的意見,在該架構下,Lettuce在源碼中直接設定了隻由master上進行讀寫(具體參見gitHub的Lettuce項目):
那麼如果真的需要讓Lettuce改為能夠讀取redis-cluster的slave,進行讀寫分離,是否可行?實際上還是可以的。這就需要我們自己在項目中進行二次加工,即不使用spring-boot中的預設Lettuce初始化方法,而是自己去寫一個屬于自己的Lettuce的新RedisClusterClient的連接配接,并且對該RedisClusterClient的連接配接進行一個比較重要的設定,那就是由connection.setReadFrom(ReadFrom.MASTER)改為connection.setReadFrom(ReadFrom.SLAVE)。
下面我們開始對之前章節中的Lettuce讀取redis-cluster資料的例子,進行改寫,讓Lettuce能夠支援該架構下的讀寫分離:
spring boot 2.X版本中,依賴的spring-session-data-redis已經預設替換成Lettuce了。
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.0.4.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent> <dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency> spring.redis.database=0
spring.redis.lettuce.pool.max-idle=10
spring.redis.lettuce.pool.max-wait=500
spring.redis.cluster.timeout=1000
spring.redis.cluster.max-redirects=3
spring.redis.cluster.nodes=172.20.52.85:7000,172.20.52.85:7001,172.20.52.85:7002,172.20.52.85:7003,172.20.52.85:7004,172.20.52.85:7005 (3)我們回到RedisConfiguration類中,删除或屏蔽之前的RedisTemplate方法,新增自定義的redisClusterConnection方法,并且設定好讀寫分離,參考代碼如下:
@Configuration
public class RedisConfiguration {
@Autowired
private Environment environment;
@Bean
public StatefulRedisClusterConnection redisClusterConnection(){
String strRedisClusterNodes = environment.getProperty("spring.redis.cluster.nodes");
String[] listNodesInfos = strRedisClusterNodes.split(",");
List<RedisURI> listRedisURIs = new ArrayList<RedisURI>();
for(String tmpNodeInfo : listNodesInfos){
String[] tmpInfo = tmpNodeInfo.split(":");
listRedisURIs.add(new RedisURI(tmpInfo[0],Integer.parseInt(tmpInfo[1]),Duration.ofDays(10)));
}
RedisClusterClient clusterClient = RedisClusterClient.create(listRedisURIs);
StatefulRedisClusterConnection<String, String> connection = clusterClient.connect();
connection.setReadFrom(ReadFrom.SLAVE);
return connection;
}
} 其中,這三行代碼是能進行redis-cluster架構下讀寫分離的核心:
RedisClusterClient clusterClient = RedisClusterClient.create(listRedisURIs);
StatefulRedisClusterConnection<String, String> connection = clusterClient.connect();
connection.setReadFrom(ReadFrom.SLAVE); 在業務類service中注入Lettuce相關的redisClusterConnection,進行相關讀寫操作。以下是我直接化簡到了springbootstarter中進行,參考代碼如下:
@SpringBootApplication
public class NewRedisClientApplication {
public static void main(String[] args) {
ApplicationContext context = SpringApplication.run(NewRedisClientApplication.class, args);
StatefulRedisClusterConnection<String, String> redisClusterConnection = (StatefulRedisClusterConnection)context.getBean("redisClusterConnection");
System.out.println(redisClusterConnection.sync().get("event:10"));
}
} 運作的結果如下圖所示:
可以看到,經過改寫的redisClusterConnection的确能讀取到redis-cluster的資料。但這一個資料我們還需要驗證一下到底是不是通過slave讀取到的,又或者還是通過slave重定向給master才擷取到的?
帶着疑問,我們可以開通debug模式,在redisClusterConnection.sync().get("event:10")等類似的擷取資料的代碼行上面打上斷點。通過代碼的走查,我們可以看到,在ReadFromImpl類中,最終會select到key所在的slave節點,進行傳回,并在該slave中進行資料的讀取:
ReadFromImpl顯示:
另外我們通過connectFuture中的顯示也驗證了對于slave的readonly生效了:
這樣,就達到了通過Lettuce用戶端對redis-cluster的讀寫分離了。
(1)直接通過代碼級更改,而不需要配置新的redis-cluster環境。
(2)無需增加機器或更新硬體裝置。
但同時,該方案也有缺點:
(1)非官方對redis-cluster的推薦方案,因為在redis-cluster架構下,進行讀寫分離,有可能會讀到過期的資料。
(2)需對項目進行全面的替換,将Jedis用戶端變為Lettuce用戶端,對代碼的改動較大,而且使用Lettuce時,使用的并非spring boot的自帶內建Lettuce的redisTemplate配置方法,而是自己配置讀寫分離的 redisClusterConnetcion,日後遇到問題的時候,可能官方文檔的支援率或支撐能力會比較低。
(3)需修改redis-cluster的master、slave配置,在各個節點中都需要加入slave-read-only yes。
(4)性能的提升沒有水準擴充master主機和執行個體來得直接幹脆。
總結
總體上來說,redis-cluster高可用架構方案是目前最好的redis架構方案,redis的官方對redis-cluster架構是建議redis-master用于接收讀寫,而redis-slave則用于備份(備用),預設不建議讀寫分離。但如果不介意讀取的是redis-cluster中有可能過期的資料并且對寫請求不感興趣時,則亦可通過readonly指令,将slave設定成可讀,然後通過slave擷取相關的key,達到讀寫分離。Jedis、Lettuce都可以進行redis-cluster的讀寫操作,而且預設隻針對Master進行讀寫,若要對redis-cluster架構下進行讀寫分離,則Jedis需要進行源碼的較大改動,而Lettuce開放了setReadFrom()方法,可以進行二次封裝成讀寫分離的用戶端,相對簡單,而且Lettuce比Jedis更安全。redis-cluster架構下可以直接通過水準擴充master來達到性能的提升。
文章來源:
https://my.oschina.net/u/2600078/blog/1923696推薦閱讀:
https://www.roncoo.com/course/view/af7d501667fe4a19a60e9467e6d2b3d9