一、logback和log4j2壓測比較
1、logback壓測資料
logback壓測資料,50個線程,500萬條日志寫入時間。
logback:messageSize = 5000000,threadSize = 50,costTime = 27383ms
logback:messageSize = 5000000,threadSize = 50,costTime = 26391ms
logback:messageSize = 5000000,threadSize = 50,costTime = 25373ms
logback:messageSize = 5000000,threadSize = 50,costTime = 25636ms
logback:messageSize = 5000000,threadSize = 50,costTime = 25525ms
logback:messageSize = 5000000,threadSize = 50,costTime = 25775ms
logback:messageSize = 5000000,threadSize = 50,costTime = 27056ms
logback:messageSize = 5000000,threadSize = 50,costTime = 25741ms
logback:messageSize = 5000000,threadSize = 50,costTime = 25707ms
logback:messageSize = 5000000,threadSize = 50,costTime = 25619ms
說明:
這個是logback日志的壓測資料,在開發機(雙核四線程),高配開發機(四核八線程)和伺服器(32核)壓測的效率都差不多,而且線程開多的時候,性能反而有下降,壓測資料如下:
logback:messageSize = 5000000,threadSize = 100,costTime = 33376ms 這個是在32核機器上壓測的平均值,高于開發機。
2、log4j2壓測資料
log4j2壓測資料,因測試資料會占用一些篇幅,這裡僅取中位數,但上下差距并不大
log4j2:messageSize = 5000000,threadSize = 100,costTime = 15509ms ---開發機
log4j2:messageSize = 5000000,threadSize = 100,costTime = 5042ms ---高配開發機
log4j2:messageSize = 5000000,threadSize = 100,costTime = 3832ms ---伺服器
本次壓測,基本上與log4j2官網資料吻合,經過驗證異步日志确實可以極大的提高IO效率
下圖為同步、異步、隻異步appender的性能對比
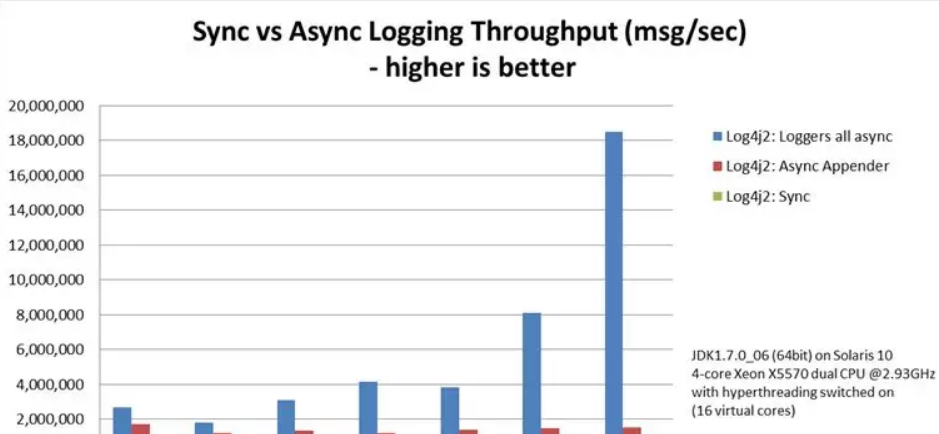
Async loggers have much higher throughput than sync loggers.
和其他日志架構的對比:

Async loggers have the highest throughput.
從本次壓測中,也得知确實在同步日志寫到一定程度下,會大大的影響伺服器的吞吐率,各位同學可以根據自己項目的情況,做日志上的優化。
下圖為并發量大時,日志架構對系統吞吐率産生的影響,這裡看logback和log4j确實影響很大,但實際情況中,感受到的要遠遠小于此圖。
二、壓測配置
log4j2的效率可以在多線程時,線上程數量大的情況下,超過logback10倍左右!500萬資料大概0.25G,隻需3秒左右就可以寫進磁盤。
在配置上,首先第一條建議是如果做異步,那麼所有的日志都是異步寫,這樣的性能指數的增長是量級的。當然也可以混合部署,但是性能影響就沒有全部異步這麼明顯。
配置上,優化一定的屬性,對性能也有一定的影響。
log4j2本身提供了20多種appender供使用者選用,但一般開發中采用的就是RollingRandomAccessFile,該元件有多個屬性配置,常用的做一下說明(其他配置對性能意義不大,有興趣的同學可自己去官網檢視)
一般采用預設值,除非系統寫日志的IO影響了主線程的運作,可以調大該配置。
本次壓測采用的日志配置
在asyncRoot中可以添加includeLocation="true"屬性,該屬性如果為true,可以攜帶類名和行号等資訊,但是抽取這些資訊,會有一些性能損耗
log4j2改版以後,元件和功能極大豐富,有興趣的同學可以去官網http://logging.apache.org/log4j/2.x/manual/index.html或找我來一起交流。
三、disruptor隊列
檢視底層代碼,log4j2之是以能在異步寫日志時性能提高這麼多,離不開優秀的mq元件disruptor。
目前使用該隊列的知名軟體包括但不限于Apache Storm、Camel、Log4j 2。
由于時間有限,本篇着重講解底層隊列的實作,因為這個對性能的影響是最大的。
以此圖為例:
同步性能最差,異步全局異步的性能接近異步appender的10倍,同樣是異步實作的,為何性能有如此大的差距?
去看源碼:
以上是異步Appender的實作,可以看到,内部内置了一個BlockingQueue隊列,具體實作采用了ArrayBlockingQueue
接着是全局異步loggers的實作方式,可見内部的隊列使用的是disruptor。
性能上的優劣,絕大部分原因都是資料模型的問題,往下我們分析一下BlockingQueue和disruptor的實作方式,由于篇幅有限,從JDK源碼來看:
1、ArrayBlockingQueue
可以看到ArrayBlockingQueue采用的是加鎖的方式來處理線程安全問題的。
加鎖的問題,雖然曆代JDK一直投入大量的精力去解決問題,比如優化Sync關鍵字的實作方式、添加讀寫鎖等,但是由于結構特性的問題,一直無法從根本上解決性能開銷問題。
題外話 _ 除了鎖的問題,還牽涉到底層CPU在計算時讀取記憶體資料的問題。
舉個例子:當你周遊一個數組時(數組在CPU計算時,是簡單資料結構),你讀取到第一個元素時,其他元素也會相應的放入1級緩存(距離CPU最近),是以你周遊資料的方式是最快的,這就是簡單資料結構的優勢。
但是如果你在操作一個Queue時,一般會涉及幾個變量,這裡以ArrayBlockingQueue為例:
這裡有三個變量,分别代表了下一個要出的元素下标,要進的元素下标和長度
當然,這幾個簡單類型是非常容易放入1級緩存并進行高速計算的,但是問題是,這個Queue是一個生産者和消費者的模型,牽涉到兩端操作,于是當生産者寫入元素時,takeIndex和putIndex數值發生改變,消費者在消費時要拿的takeIndex也跟着改變,這時就需要去主存中重新去取takeIndex,而無法利用1級緩存進行高速計算。
以上大緻解釋了ArrayBlockingQueue的性能劣勢,接下來就看disputor如果解決這些問題。
2、Disputor
引入官網的一段話(首先要明白背景和訴求):
這裡的表述和我們的目标一緻,都是要解決鎖和緩存缺失帶來的性能開銷問題。
引用幾張官網的截圖(風格還比較有趣):
https://www.slideshare.net/trishagee/introduction-to-the-disruptor?from=new_upload_email 這是該PPT的位址,有興趣的同學可以關注下。
他們采用了環形資料結構來解決這個問題(他們稱之為魔法圓環,或魔法圓圈之類的),此種資料結構的有點是,不需要記錄額外的下标,直接由JNI傳回可以操作的位址,然後當多線程并發讀寫的時候,使用的也是CAS方式。
這樣,不能使用1級緩存和加鎖操作的問題就解決了(關于CAS大家可自行谷歌,有非常多的文章來介紹)。
由于篇幅和經曆有限,本次分享先寫到這裡,如果之後對disruptor有需要的話,可以再次深入研究。
原文釋出時間為:2018-08-15
本文作者:詹嵩
本文來自雲栖社群合作夥伴“
中生代技術”,了解相關資訊可以關注“
”。