在2018年Elastic Meetup 南京交流會中,來自雲利來科技的塗海波為現場的聽衆帶來了題為《南京雲利來基于ELK的大資料平台》的精彩分享。在本次分享中,他首先進行了公司簡介,然後介紹了資料分類,包括資料采集及資料類型等;然後重點闡述了運維之路,最後進行了告警分析。 阿裡雲Elasticsearch 1核2G首月免費試用,開始雲上實踐吧 直播視訊請點選 PPT下載下傳請點選
以下内容根據現場分享整理而成。
南京雲利來有限公司主要專注于以下三個方面:實時網絡使用分析,具備世界領先20Gbps分析能力;為資料中心搭建大資料分析平台,資料中心主要是給運維團隊、安全團隊和開發團隊做跨部門協作;提供智能運維、網絡安全和預警分析能力。産品主要應用的行業包括電商、政府、證券等。
資料分類
資料采集
資料采集主要分為網絡類和日志類。網絡類主要為旁路部署,用小盒子部署在機房内不同的點,包括出口入口。日志類主要包括Nagios (filebeat)和Zabbix (mysqlexporter)。
資料類型
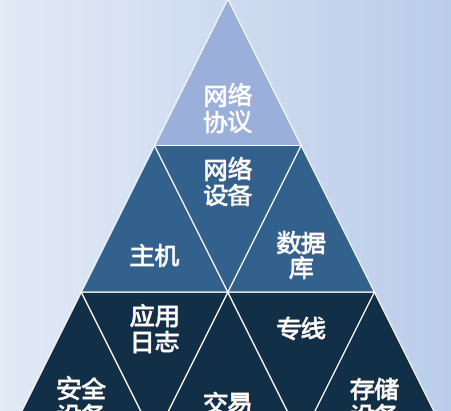
上圖為主要資料類型,網絡協定裡也有資料庫,是一些協定解析,還有一些交易的解析。可以從網絡層面和日志層面分開來比對。
資料量
每天資料量至少2TB,記錄數22億,不含副本;高峰資料量每秒6萬條記錄;單個索引最快處理12萬條記錄每秒。
使用場景
主要有三個使用場景:查詢聚合;大屏分析,預測告警;網絡名額,業務名額安全名額。
網絡業務安全是基于一些不同的團隊,定制個性化的名額,進行一些對比分析。
運維之路
叢集演變
在使用ELK的整個過程中,我們使用過Vmware、Docker,跟美國的第三方公司的一些合作。我們自己用的最多的是單節點單執行個體和單節點雙執行個體。基本是用于功能測試小公司一些測試部署。
冷熱分離
我們做的冷熱分離,開始采用的是flashcache模式,每台實體機上面都配備了一個SSD的小盤,主要是為了抵消傳統的機械式硬碟尋到的一個LPS。LPS比較慢,延遲比較高,是以分布式叢集每一塊都配備一個小盤。在這種模式下,磁盤IO連續小塊讀,負載高,IOwait高,分析發現存在抖動。采用單機雙執行個體冷熱分離模式,充分利用1.6TB的SSD,隻儲存每天的熱資料,隔夜遷移到HDD Raid0。
更新的主要目的有兩個:記憶體隔離,當天和曆史JAVA對象分離在不同的JVM裡;IO隔離,當天和曆史資料的磁盤IO分離在不同的磁盤上。

上圖為運維前後對比效果圖。左邊是運維之前,右邊是運維之後。更新後,有效減少了cpu wait和磁盤讀,降低了系統負載,有效提升了查詢和寫入性能。
上圖為在單個索引上做的測試。之前做了許多積壓,可以發現索引的速度是上升的。單個索引最高速度從之前的60000條每秒提升到120000條記錄每秒,平均10萬條每秒。聚合查詢性能提升1倍。
重要選型
重要選型首先從cpu介紹,我們推薦使用Xeon E5-2600 V4系列。官方測試顯示,它比V3系列提升JAVA性能60%,我們進行了一些設定,包括指令預取,cache line預取,Numa Set。結合雙路cpu,它的記憶體和節點有一個就近讀取的原則。我們根據單個機器的執行個體進行cpu的綁定。設定以後可以提高cpu的命中率,減少記憶體的切換。
在記憶體方面,每台實體機配備的是128TB,SSD是1.6TB,HDD是40TB~48TB。具有大記憶體的特點,我們還進行了Cache加速,寫負載高的時候上SSD,定期做Trim優化,利用SSD,SAS和SATA盤分級存儲。
OS file system用的最多的是xfs。針對HDD、SSD 4k對齊優化,確定每個分區的start Address能被8整除,解決跨扇區通路,減少讀寫次數和延遲。
Shard和Replica個數是基于測試的經驗,可以作為參考,還基于負載、性能等。節點數設定為1.5。Shard size 控制在30GB以内,Shard docs 控制在5百萬記錄以内,Replica至少為1。
可靠性
由上圖可以看到每個角色都有A、B、C三個點,然後做了冷熱分離,Client多個點做了負載均衡。
性能分析
-
高負載
高負載主要采用IO負載型,主要關注Sar,Vmstat,IOstat,Dstat和Systemtap,Perf。
-
線程池
線程池這裡主要關注Index,Query,Merge,Bulk,包括Thread,Queue Size和Active,Queue。
-
記憶體占用
記憶體占用主要看各個節點的記憶體占用大小,Fielddata設定為10%,也有的設定為1%,大部分場景都是精确查詢。
-
查詢
用慢查詢作為告警,然後進行請求、響應、延時、峰值統計。随着資源使用率的提升,我們會發現在80%的點位,延時會特别大,于是會有多個監工。單個監工是沒問題的,但是多個監工可能是有問題的。Query profile用來定位各個階段的時間。Cache filling用來觀看命中率如何,可以做一些cache的設定。然後會進行日志埋點采集,query replay,做一些測試。
-
叢集健康
叢集健康這裡主要是對以下幾項進行名額監控。 _cluster/health:active, reallocating, initializing,unassigned;Ping timeout;Shard allocation,recover latency。
-
GC效率
GC效率主要關注以下幾點:GC時長占比,GC回收量占比;記憶體增長速率,記憶體回收速率;各代回收耗時,頻率;Dump profile;Jstack,Jmap,Jstat。
存儲規劃
上圖為基于不同業務做的存儲規劃。
性能提升
-
合理設計
首先我們會考慮每個域的意義,沒有意義的域是不允許插進來的。然後要考慮需要存儲搜尋還是聚合,思考每一個域的價值所在。它是字元串型的還是數值型的?然後我們會對模闆進行動态的設定。當字元串過長的時候,我們是否要做一個截取?是否要做一個Hash?
-
批處理
适當調大處理時間,Translog适當把頻率降低。
上圖做了一個按需隔離,分表分級分組。
-
規劃計算
提前聚合後插入;因為空間不夠,是以超過生命周期後隻保留基線,然後做壓縮,做合并;随後可以做Pipeline拆分。
叢集監控
監控這裡用了一些工具。Netdata用來做一些系統資源的更新, _cat api是官方自帶的,Cerebro是用的比較多的一個插件,Prometheus可以開箱即用。
告警分析
用Sql文法做一些包裝、抽象,告警模型基于從工作日開始的疊代、同比環比、平均值及标準差,基線學習。
我們發現問題,解決問題,需要不停的去思考。不斷疊代,嚴苛細節,最終性能是否滿足?是否可接受?這些都是需要思考的問題。