一、大綱
- 一階段送出
- 二階段送出
- 三階段送出
- 組送出總結
二、一階段送出
2.1 什麼是一階段送出
先了解下含義,其實官方并沒有定義啥是一階段,這裡隻是我為了上下文和好了解,自己定義的一階段commit流程。
好了,這裡的一階段,其實是針對MySQL沒有開啟binlog為前提的,因為沒有binlog,是以MySQL commit的時候就相對簡單很多。
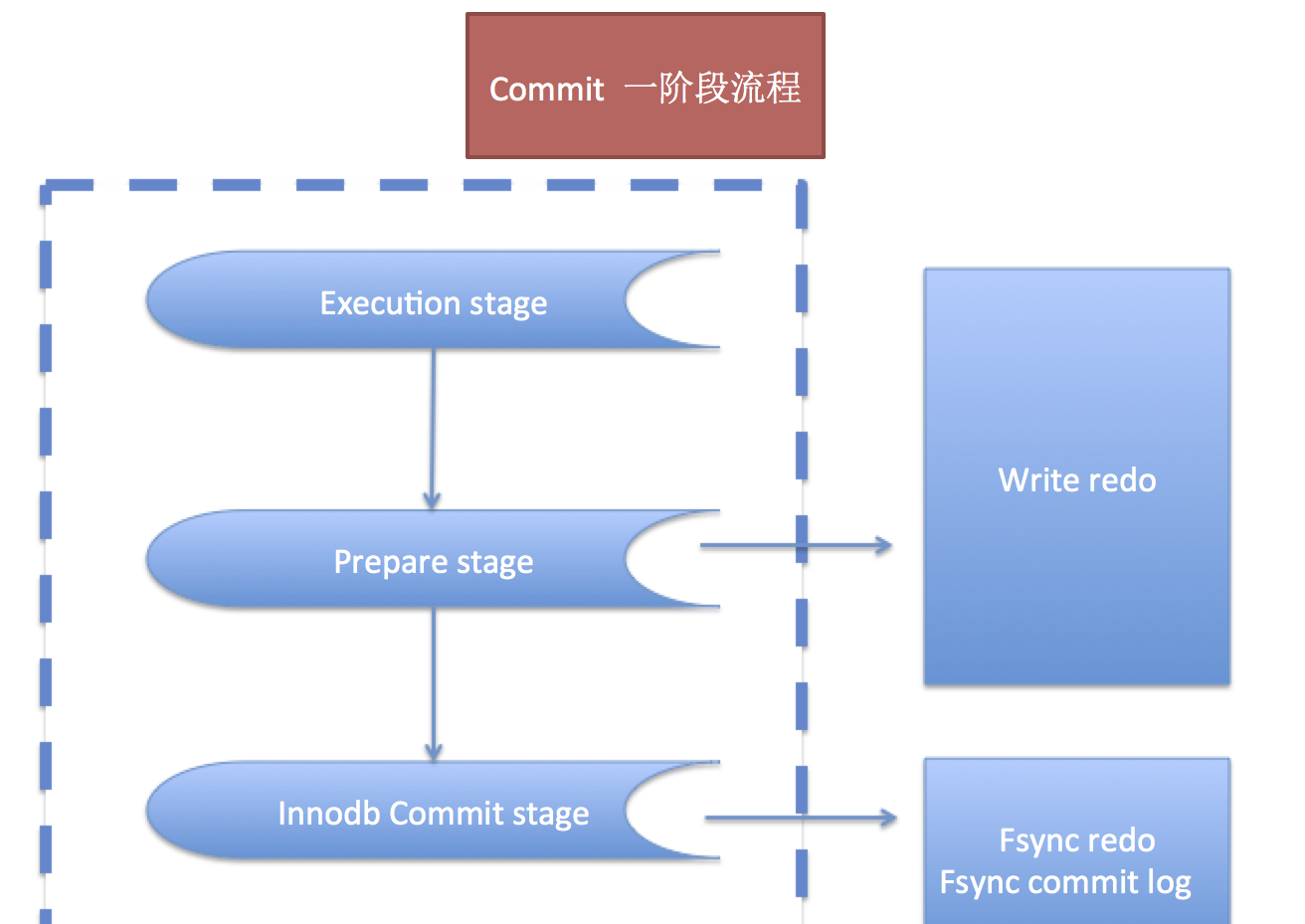
解釋幾個概念:
- execution state做什麼事情呢
在記憶體修改相關資料,比如:DML的修改 - prepare stage做什麼事情呢
1. write() redo 日志
1.1 最重要的操作,記住這個時候就開始重新整理redo了(依賴作業系統sync到磁盤),很多同學在這個地方都不太清楚,以為flush redo在最後commit階段才開始
1.2 這一步可以進行多事務的prepare,也就意味着可以多redo的flush,sync到磁盤,這裡是redo的組送出. 在此說明MySQL5.6+ redo是可以進行組送出的,之後我們讨論的重點是binlog,就不在提及redo的組送出了
2. 更新undo狀态
3. 等等
- innodb commit stage做什麼事情呢
1. 更新undo的狀态
2. fsync redo & undo(強制sync到磁盤)
3. 寫入最終的commit log,代表事務結束
4. 等等 由于這裡面隻對應到redo日志,是以我們稱之為一階段commit
2.2 為什麼要有一階段送出
一階段送出,主要是為了crash safe。
- 如果在 execution stage mysql crash
當MySQL重新開機後,因為沒有記錄redo,此事務復原
當MySQL重新開機後,因為沒有記錄redo,此事務復原
- 如果 prepare stage
1. redo log write()了,但是還沒有fsync()到磁盤前,mysqld crash了
此時:事務復原
2. redo log write()了,fsync()也落盤了,mysqld crash了
此時:事務還是復原
- 如果 commit stage
1. commit log fsync到磁盤了
此時:事務送出成功,否則事務復原
2.3 一階段送出的弊端
缺點也很明顯:
- 缺點一
1. 為什麼redo fsync到磁盤後,還是要復原呢?
- 缺點二
1. 沒有開啟binlog,性能非常高,但是binlog是用來搭建slave的,否則就是單節點,不适合生産環境
三、二階段送出
3.1 什麼是二階段送出

繼續解釋幾個概念:
在記憶體修改相關資料,比如:DML的修改 1. write() redo 日志 --最重要的操作,記住這個時候就開始重新整理redo了(依賴作業系統sync到磁盤),很多同學在這個地方都不太清楚,以為flush redo在最後commit階段才開始
2. 更新undo狀态
3. 等等
- binlog stage做什麼事情呢
1. write binlog
flush binlog 記憶體日志到磁盤緩存
2. fsync binlog
sync磁盤緩存的binlog日志到磁盤持久化 1. 更新undo的狀态
2. fsync redo & undo(強制sync到磁盤)
3. 寫入最終的commit log,代表事務結束
4. 等等 由于這裡的流程中包含了binlog和redo日志重新整理的協調一緻性,我們稱之為二階段
3.2 為什麼要有二階段送出
當binlog開啟的情況下,我們需要引入另一套流程來保證redo和binlog的一緻性 , 以及crash safe,是以我們用這套二階段來實作
- 在prepare階段,如果mysqld crash,由于事務未寫入binlog且innodb 存儲引擎未送出,是以将該事務復原掉
- 當binlog階段
1. binlog flush 到磁盤緩存,但是沒有永久fsync到磁盤
如果mysqld crash,此事務復原
2. binlog永久fsync到磁盤,但是innodb commit log還未送出
如果mysqld crash,MySQL 進行recover,從binlog的xid提取送出的事務進行重做并commit,來保證binlog和redo保持一緻
- 當commit階段
如果innodb commit log已經送出,事務成功結束
那為什麼要保證redo和binlog的一緻性呢?
- 實體熱備的問題
- 多事務中,如果無法保證多事務的redo和binlog一緻性,則會有如下問題
commit送出階段包含的事情:
1. prepare
2. write binlog & fsync binlog
3. commit
T1 (---prepare-----write 100[pos1]-------fsync 100--------------------------------------online-backup[pos3:因為熱備取的是最近的送出事務位置]-------commit)
T2 (------prepare------write 200[pos2]---------fsync 200------commit)
T3 (-----------prepare-------write 300[pos3]--------fsync 300--------commit)
解析:
事務的開始順序: T1 -》T2 -》T3
事務的送出結束順序: T2 -》T3 -》T1
binlog的寫入順序: T1 -》 T2 -》T3
結論:
T2 , T3 引擎層送出結束,T1 fsync binlog 100 也已經結束,但是T1引擎成沒有送出成功,是以這時候online-backup記錄的binlog位置是pos3(也就是T3送出後的位置)
如果拿着備份重新恢複slave,由于熱備是不會備份binlog的,是以事務T1會復原掉,那麼change master to pos3的時候,因為T1的位置是pos1(在pos3之前),是以T1事務被slave完美的漏掉了 - 多事務中,可以通過三階段送出(下面一節講)保證redo和binlog的一緻性,則備份無問題. 接下來看一個多事務中,事務日志和binlog日志一緻的情況
commit送出階段包含的事情:
1. prepare
2. write binlog & fsync binlog
3. commit
T1 (---prepare-----write 100[pos1]-------fsync 100-------------commit)
T2 (------prepare------write 200[pos2]---------fsync 200----------------online-backup[pos2:因為熱備取的是最近的送出事務位置]---commit)
T3 (-----------prepare-------write 300[pos3]--------fsync 300----------------------------------------------------------------------------commit)
解析:
事務的開始順序: T1 -》T2 -》T3
事務的送出結束順序: T1 -》T2 -》T3
binlog的寫入順序: T1 -》 T2 -》T3
ps:以上的事務和binlog完全按照順序一緻運作
結論:
T1 引擎層送出結束,T2 fsync binlog 200 也已經結束,但是T2引擎成沒有送出成功,是以這時候online-backup記錄的binlog位置是pos1(也就是T1送出後的位置)
如果拿着備份重新恢複slave,由于熱備是不會備份binlog的,是以事務T2會復原掉,那麼change master to pos1的時候,因為T1的位置是pos1(在pos2之前),是以T2、T3事務會被重做,最終保持一緻
總結:
以上的問題,主要原因是熱備份工具無法備份binlog導緻的根據備份恢複的slave復原導緻的,産生這樣的原因最後還是要歸結于最後引擎層的日志沒有送出導緻
是以,xtrabackup意識到了這一點,最後多了這一步flush no_write_to_binlog engine logs,表示将innodb層的redo全部持久化到磁盤後再進行備份,在通俗的說,就是圖例上的T2一定成功後,才會再繼續進行拷貝備份
那麼如果是這樣,圖例上的T2在恢複的時候,就不會被復原了,是以就自然不會丢失事務啦
- 主從資料不一緻問題
如果redo和binlog不是一緻的,那麼有可能就是master執行事務的順序和slave執行事務順序不一樣,那麼不一樣會導緻什麼問題呢?
在一些依賴事務順序的場景,尤其重要,比如我們看一個例子
master節點送出T1和T2事務按照以下順序
1. State0: x= 1, y= 1 --初始值
2. T1: { x:= Read(y);
3. x:= x+1;
4. Write(x);
5. Commit; }
State1: x= 2, y= 1
7. T2: { y:= Read(x);
8. y:=y+1;
9. Write(y);
10. Commit; }
State2: x= 2, y= 3
以上兩個事務順序在master為 T1 -> T2
最終結果為
State1: x= 2, y= 1
State2: x= 2, y= 3 如果slave的事務執行順序與master相反,會怎麼樣呢?
1. State0: x= 1, y= 1 --初始值
2. T2: { y:= Read(x);
3. y:= y+1;
4. Write(y);
5. Commit; }
6.
State1: x= 1, y= 2
7. T1: { x:= Read(y);
8. x:=x+1;
9. Write(x);
10. Commit; }
11.
State2: x= 3, y= 2
以上兩個事務順序在master為 T2 -> T1
最終結果為
State1: x= 1, y= 2
State2: x= 3, y= 2
結論:
- 為了保證主備資料一緻性,slave節點必須按照同樣的順序執行,如果順序不一緻容易造成主備庫資料不一緻的風險。
- 而redo 和 binlog的一緻性,在單線程複制下是master和slave資料一緻性的另一個保證, 多線程複制需要依賴MTS的設定
- 是以,MySQL必須要保證redo 和 binlog的一緻性,也就是:引擎層送出的順序和server層binlog fsync的順序必須一緻,那麼二階段送出就是這樣的機制
3.3 二階段送出的弊端
二階段送出能夠保證同一個事務的redo和binlog的順序一緻性問題,但是無法解決多個事務送出順序一緻性的問題
四、三階段送出
4.1 什麼是三階段送出
在記憶體修改相關資料,比如:DML的修改 1. write() redo 日志 --最重要的操作,記住這個時候就開始重新整理redo了(依賴作業系統sync到磁盤),很多同學在這個地方都不太清楚,以為flush redo在最後commit階段才開始
2. 更新undo狀态
3. 等等
1. write binlog --一組有序的binlog
flush binlog 記憶體日志到磁盤緩存
2. fsync binlog --一組有序的binlog
sync磁盤緩存的binlog日志到磁盤持久化 1. 更新undo的狀态
2. fsync redo & undo(強制sync到磁盤)
3. 寫入最終的commit log,代表事務結束 --一組有序的commit日志,按序送出
4. 等等 這裡将整個事務送出的過程分為了三個大階段
InnoDB, Prepare
SQL已經成功執行并生成了相應的redo日志
Binlog, Flush Stage(group) -- 一階段
寫入binlog緩存;
Binlog, Sync Stage(group) -- 二階段
binlog緩存将sync到磁盤
InnoDB, Commit stage(group) -- 三階段
leader根據順序調用存儲引擎送出事務;
重要參數:
binlog_group_commit_sync_delay=N : 等待N us後,開始刷盤binlog
binlog_group_commit_sync_no_delay_count=N : 如果隊列的事務數達到N個後,就開始刷盤binlog
4.2 為什麼要有三階段送出
目的就是保證多事務之間的redo和binlog順序一緻性問題, 以及加入組送出機制,讓redo和binlog都可以以組的形式(有序集合)進行fsync來提高并發性能
4.3 再來聊聊MySQL組送出
隊列相關
組送出舉例
(一)、T1事務第一個進入第一階段 FLUSH , 由于是第一個,是以是leader,然後再等待(按照具體算法)
(二)、T2事務第二個進行第一階段 FLUSH , 由于是第二個,是以是follower,然後等待leader排程
(三)、FLUSH隊列等待結束後,開始進入下一階段SYNC階段,此時T1帶領T2進行一次fsync操作,之後進入commit階段,按序送出完成,這就是一次組送出的簡要過程了
(四)、prepare可以并行,說明兩個事務沒有任何沖突。有沖突的prepare無法進行進入同一隊列
(五)、每個隊列之間都是可以并行運作的
五、總結
- 組送出的核心思想就是:一次fsync()調用,可以重新整理N個事務的redo log(redo的組送出) & binlog(binlog的組送出)
- 組送出的最終目的就是為了減少IO的頻繁刷盤,來提高并發性能,當然也是之後多線程複制的基礎
- 組送出中:sync_binlog=1 & innodb_trx_at_commit=1 代表的不再是1個事務,而是一組事務和一個事務組的binlog
- 組送出中:binlog是順序fsync的,事務也是按照順序進行送出的,這都是有序的,MySQL5.7 并對這些有序的事務進行打好标記(last_committed,sequence_number )
六、思考問題
- 如何保證slave執行的同一組binlog的事務順序跟master的一緻
如果slave上同一組事務中的後面的事務先執行,那麼slave的gtid該如何表示 如何保證slave上同一組事務中的事務是按照順序執行的 - 如果slave突然挂了,那麼執行到一半的一組事務,是全部復原?還是部分復原?
如果是部分復原,那麼如何知道哪些復原了,哪些沒有復原,mysql如何自動修複掉復原的那部分事務