了解圖像分割中的卷積(Understand Convolution for Semantic Segmentation) Conclusion
了解圖像分割中的卷積(Understand Convolution for Semantic Segmentation) Conclusion  了解圖像分割中的卷積(Understand Convolution for Semantic Segmentation) Conclusion
了解圖像分割中的卷積(Understand Convolution for Semantic Segmentation) Conclusion 了解圖像分割中的卷積(Understand Convolution for Semantic Segmentation) Conclusion 了解圖像分割中的卷積(Understand Convolution for Semantic Segmentation) Conclusion 了解圖像分割中的卷積(Understand Convolution for Semantic Segmentation) Conclusion 了解圖像分割中的卷積(Understand Convolution for Semantic Segmentation) Conclusion 了解圖像分割中的卷積(Understand Convolution for Semantic Segmentation) Conclusion 了解圖像分割中的卷積(Understand Convolution for Semantic Segmentation) Conclusion 了解圖像分割中的卷積(Understand Convolution for Semantic Segmentation) Conclusion 了解圖像分割中的卷積(Understand Convolution for Semantic Segmentation) Conclusion 了解圖像分割中的卷積(Understand Convolution for Semantic Segmentation) Conclusion 了解圖像分割中的卷積(Understand Convolution for Semantic Segmentation) Conclusion 了解圖像分割中的卷積(Understand Convolution for Semantic Segmentation) Conclusion 了解圖像分割中的卷積(Understand Convolution for Semantic Segmentation) Conclusion 了解圖像分割中的卷積(Understand Convolution for Semantic Segmentation) Conclusion 了解圖像分割中的卷積(Understand Convolution for Semantic Segmentation) Conclusion 以最佳的101 layer的ResNet-DUC為基礎,添加HDC,實驗探究了幾種變體:
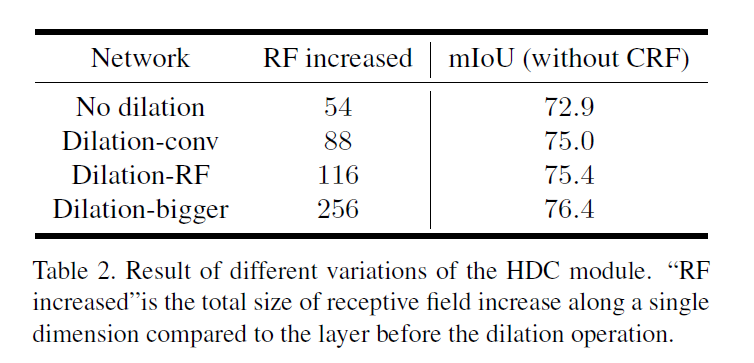
- 無擴張卷積(no dilation):對于所有包含擴張卷積,設定r=1r=1
- 擴張卷積(dilation Conv ):對于所有包含擴張卷積,将2個block和為一組,設定第一個block的r=2r=2,第二個block的r=1r=1
- Dilation-RF:對于res4bres4b包含了23個blocks,使用的r=2r=2,設定3個block一組,r=1,2,3r=1,2,3.對于最後兩個block,設定r=2r=2;對于res5bres5b,包含3個block,使用r=4r=4,設定為r=3,4,5r=3,4,5.
- Dilation-Bigger:對于res4bres4b子產品,設定4個block為一組,設定r=1,2,5,9r=1,2,5,9.最後3個block設定為1,2,51,2,5;對于res5bres5b子產品,設定r=5,9,17r=5,9,17
了解圖像分割中的卷積(Understand Convolution for Semantic Segmentation) Conclusion 可以看到增加接收野大小會獲得較高的精度。如下圖所示:
了解圖像分割中的卷積(Understand Convolution for Semantic Segmentation) Conclusion ResNet-DUC-HDC在較大的目标物上表現較好。下圖是局部放大:
了解圖像分割中的卷積(Understand Convolution for Semantic Segmentation) Conclusion 可以看到HDC有效的消除”gridding”産生的影響。
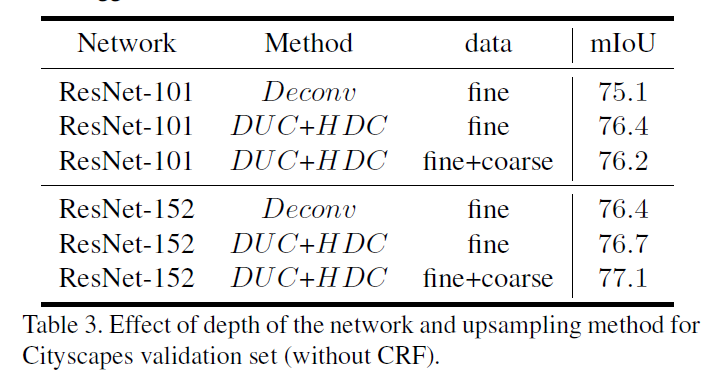
Deeper Networks: 同樣嘗試了将ResNet-101切換為ResNet-152,使用ResNet152先跑了10個epoch學習了BN層參數,再固定BN層,跑了20個epochs.結果如下:
了解圖像分割中的卷積(Understand Convolution for Semantic Segmentation) Conclusion ResNet152為基礎層的有1%的提升。
Test Set Results: 論文将ResNet101開始的7×77×7卷積拆分為3個3×33×3的卷積,再不帶CRF的情況下達到了80.1%mIoU.與其他先進模型相比如下:
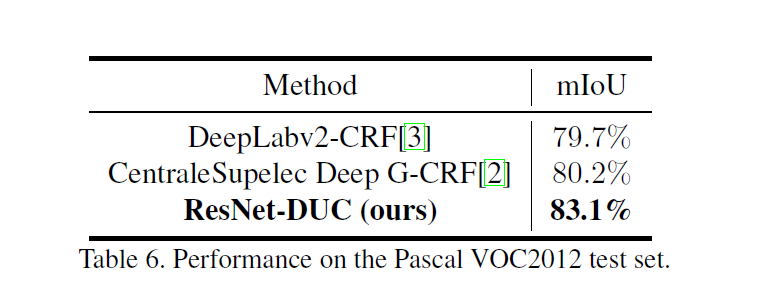
了解圖像分割中的卷積(Understand Convolution for Semantic Segmentation) Conclusion 模型同時在coarse labels跑了一圈,與同樣以deliated convolution為主的DeepLabv2相比,提升了9.7%.
KITTI Road Segmentaiton
KITTI有289的訓練圖檔和290個測試圖檔。示例如下:
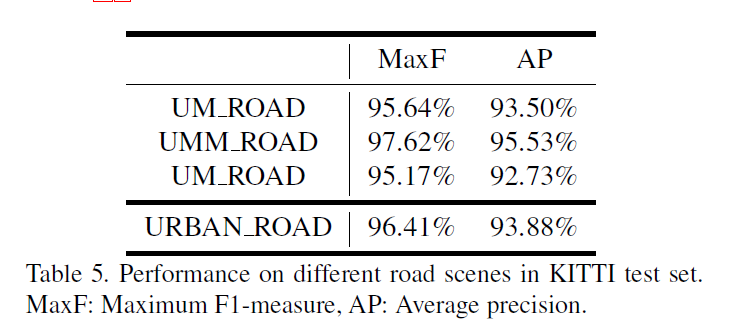
了解圖像分割中的卷積(Understand Convolution for Semantic Segmentation) Conclusion 因為資料集有限,為了避免過拟合。論文以100的步長在資料集中裁剪320×320320×320的patch. 使用預訓練模型,結果如下:
了解圖像分割中的卷積(Understand Convolution for Semantic Segmentation) Conclusion 結果達到了state-of-the-art水準.
PASCAL VOC2012 dataset
先用VOC2012訓練集和MS-COCO資料集對ResNet-DUC做預訓練。再使用VOC2012做fine-tune。使用的圖檔大小為512×512512×512。達到了state-of-the-art水準:
了解圖像分割中的卷積(Understand Convolution for Semantic Segmentation) Conclusion 可視化結果如下:
了解圖像分割中的卷積(Understand Convolution for Semantic Segmentation) Conclusion Conclusion
論文提出了簡單有效的卷積操作改進語義分割系統。使用DUC恢複上采樣丢失的資訊,使用HDC在解決”gridding”的影響的同時擴大感受野。實驗證明我們的架構對各種語義分割任務的有效性。