本文需要有相關spring boot 或spring cloud 相關微服務架構的基礎,如果您具備相關基礎可以很容易的實作下述過程!!!!!!!
希望本文的所說對需要的您有所幫助
從這裡我們開始進入閑聊階段。
大家都知道 spring boot整合了很多很多的第三方架構,我們這裡就簡單讨論和使用 性能監控和JVM監控相關的東西。其他的本文不讨論雖然有些關聯,是以開篇有說需要有相關spring boot架構基礎說了這麼多廢話,下面真正進入主題。
這裡首先給大家看下整體的資料流程圖,其中兩條主線一條是接口或方法性能監控資料收集,還有一條是spring boot 微服務JVM相關名額資料采集,最後都彙總到InfluxDB時序資料庫中在用資料展示工具Grafara進行資料展示或報警。
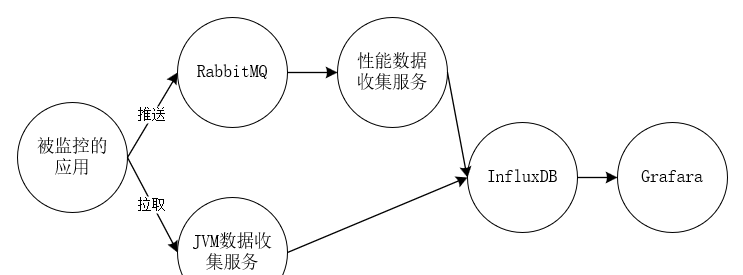
〇、基礎服務
基礎服務比較多,其中包括RabbitMQ,Eureka注冊中心,influxDB,Grafara(不知道這些東西 請百度或谷歌一下了解相關知識),下面簡單說下各基礎服務的功能:
RabbitMQ 一款很流行的消息中間件,主要用它來收集spring boot應用監控性能相關資訊,為什麼是RabbitMQ而不是什麼别的 kafka等等,因為測試友善性能也夠用,spring boot整合的夠完善。
Eureka 注冊中心,一般看過或用過spring cloud相關架構的都知道spring cloud注冊中心主要推薦使用Eureka!至于為什麼不做過多讨論不是本文主要讨論的關注點。本文主要用來同步和擷取注冊到注冊中心的應用的相關資訊。
InfluxDB和Grafara為什麼選這兩個,其他方案如 ElasticSearch 、Logstash 、Kibana,ELK的組合等!原因很顯然 influxDB是時序資料庫資料的壓縮比率比其他(ElasticSearch )好的很多(當然本人沒有實際測試過都是看一些文檔)。同時InfluxDB使用SQL非常類似mysql等關系型資料庫入門友善,Grafara工具可預警。等等!!!!!!!!!!!
好了工具就簡單介紹到這裡,至于這些工具怎麼部署搭建請搭建先自行找資料學習,還是因為不是本文重點介紹的内容,不深入讨論。如果有docker相關基礎的童鞋可以直接下載下傳個鏡像啟動起來做測試使用(本人就是使用docker啟動的上面的基礎應用(Eureka除外))
一、被監控的應用
這裡不多說被監控應用肯定是spring boot項目但是要引用一下相關包和相關注解以及修改相關配置檔案
包引用,這些包是必須引用的
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-sleuth-zipkin-stream</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-rabbit</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-hystrix</artifactId>
</dependency>
簡單說下呢相關包的功能spring-cloud-starter-netflix-eureka-client用于注冊中心使用的包,spring-cloud-starter-stream-rabbit 發送RabbitMQ相關包,spring-boot-starter-actuator釋出監控相關rest接口包,
spring-cloud-starter-hystrix熔斷性能監控相關包。
相關注解 @EnableHystrix//開啟性能監控
@RefreshScope//重新整理配置檔案 與本章無關
@EnableAutoConfiguration
@EnableFeignClients//RPC調用與本章無關
@RestController
@SpringBootApplication
public class ServerTestApplication {
protected final static Logger logger = LoggerFactory.getLogger(ServerTestApplication.class);
public static void main(String[] args) {
SpringApplication.run(ServerTestApplication.class, args);
}
} 配置檔案相關

hystrix.command.default.execution.isolation.thread.timeoutInMilliseconds: 60000
hystrix.threadpool.default.coreSize: 100
spring:
application:
name: spring-cloud-server2-test
rabbitmq:
host: 10.10.12.21
port: 5672
username: user
password: password
encrypt:
failOnError: false
server:
port: 8081
eureka:
instance:
appname: spring-cloud-server2-test
prefer-ip-address: true
client:
serviceUrl:
defaultZone: http://IP:PORT/eureka/#注冊中心位址
eureka-server-total-connections-per-host: 500
endpoints:
refresh:
sensitive: false
metrics:
sensitive: false
dump:
sensitive: false
auditevents:
sensitive: false
features:
sensitive: false
mappings:
sensitive: false
trace:
sensitive: false
autoconfig:
sensitive: false
loggers:
sensitive: false View Code
簡單解釋一下endpoints下面相關配置,主要就是 原來這些路徑是需要授權通路的,通過配置讓這些路徑接口不再是敏感的需要授權通路的接口這應我們就可以輕松的通路注冊到注冊中心的每個服務的響應的接口。這裡插一句接口性能需要在方法上面加上如下類似相關注解,然後才會有相關性能資料輸出
@Value("${name}")
private String name;
@HystrixCommand(commandProperties = {
@HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds", value = "20000") }, threadPoolProperties = {
@HystrixProperty(name = "coreSize", value = "64") }, threadPoolKey = "test1")
@GetMapping("/testpro1")
public String getStringtest1(){
return name;
} 好了到這裡你的應用基本上就具備相關性能輸出的能力了。你可以通路 如果是上圖的接口 你的應用基本OK,為什麼是基本因為你截圖沒有展現性能資訊發送RabbitMQ的相關資訊。這個需要看日志,加入你失敗了評論區在讨論。我們先關注主線。
好的spring boot 應用就先說道這裡。開始下一主題
二、性能名額資料采集
剛才通路http://IP:port/hystrix.stream這個顯示出來的資訊就是借口或方法性能相關資訊的輸出,如果上面都沒有問題的話資料應該發送到了RabbitMQ上面了我們直接去RabbitMQ上面接收相關資料就可以了。
性能名額資料的采集服務主要應用以下包
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
<!-- https://mvnrepository.com/artifact/com.github.miwurster/spring-data-influxdb -->
<dependency>
<groupId>org.influxdb</groupId>
<artifactId>influxdb-java</artifactId>
<version>2.8</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-autoconfigure</artifactId>
</dependency> 直接貼代碼
package application;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
/**
*
* @author zyg
*
*/
@SpringBootApplication
public class RabbitMQApplication {
public static void main(String[] args) {
SpringApplication.run(RabbitMQApplication.class, args);
}
} package application;
import org.springframework.amqp.core.Binding;
import org.springframework.amqp.core.BindingBuilder;
import org.springframework.amqp.core.Queue;
import org.springframework.amqp.core.TopicExchange;
import org.springframework.amqp.rabbit.connection.CachingConnectionFactory;
import org.springframework.amqp.rabbit.connection.ConnectionFactory;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
*
* @author zyg
*
*/
@Configuration
public class RabbitMQConfig {
public final static String QUEUE_NAME = "spring-boot-queue";
public final static String EXCHANGE_NAME = "springCloudHystrixStream";
public final static String ROUTING_KEY = "#";
// 建立隊列
@Bean
public Queue queue() {
return new Queue(QUEUE_NAME);
}
// 建立一個 topic 類型的交換器
@Bean
public TopicExchange exchange() {
return new TopicExchange(EXCHANGE_NAME);
}
// 使用路由鍵(routingKey)把隊列(Queue)綁定到交換器(Exchange)
@Bean
public Binding binding(Queue queue, TopicExchange exchange) {
return BindingBuilder.bind(queue).to(exchange).with(ROUTING_KEY);
}
@Bean
public ConnectionFactory connectionFactory() {
//rabbitmq IP 端口号
CachingConnectionFactory connectionFactory = new CachingConnectionFactory("IP", 5672);
connectionFactory.setUsername("user");
connectionFactory.setPassword("password");
return connectionFactory;
}
@Bean
public RabbitTemplate rabbitTemplate(ConnectionFactory connectionFactory) {
return new RabbitTemplate(connectionFactory);
}
} package application;
import java.util.Map;
import java.util.concurrent.TimeUnit;
import org.influxdb.InfluxDB;
import org.influxdb.InfluxDBFactory;
import org.influxdb.dto.Point;
import org.influxdb.dto.Point.Builder;
import org.influxdb.dto.Query;
import org.influxdb.dto.QueryResult;
/**
*
* @author zyg
*
*/
public class InfluxDBConnect {
private String username;// 使用者名
private String password;// 密碼
private String openurl;// 連接配接位址
private String database;// 資料庫
private InfluxDB influxDB;
public InfluxDBConnect(String username, String password, String openurl, String database) {
this.username = username;
this.password = password;
this.openurl = openurl;
this.database = database;
}
/** 連接配接時序資料庫;獲得InfluxDB **/
public InfluxDB influxDbBuild() {
if (influxDB == null) {
influxDB = InfluxDBFactory.connect(openurl, username, password);
influxDB.createDatabase(database);
}
return influxDB;
}
/**
* 設定資料儲存政策 defalut 政策名 /database 資料庫名/ 30d 資料儲存時限30天/ 1 副本個數為1/ 結尾DEFAULT
* 表示 設為預設的政策
*/
public void createRetentionPolicy() {
String command = String.format("CREATE RETENTION POLICY \"%s\" ON \"%s\" DURATION %s REPLICATION %s DEFAULT",
"defalut", database, "30d", 1);
this.query(command);
}
/**
* 查詢
*
* @param command
* 查詢語句
* @return
*/
public QueryResult query(String command) {
return influxDB.query(new Query(command, database));
}
/**
* 插入
*
* @param measurement
* 表
* @param tags
* 标簽
* @param fields
* 字段
*/
public void insert(String measurement, Map<String, String> tags, Map<String, Object> fields) {
Builder builder = Point.measurement(measurement);
builder.time(((long)fields.get("currentTime"))*1000000, TimeUnit.NANOSECONDS);
builder.tag(tags);
builder.fields(fields);
//
influxDB.write(database, "", builder.build());
}
/**
* 删除
*
* @param command
* 删除語句
* @return 傳回錯誤資訊
*/
public String deleteMeasurementData(String command) {
QueryResult result = influxDB.query(new Query(command, database));
return result.getError();
}
/**
* 建立資料庫
*
* @param dbName
*/
public void createDB(String dbName) {
influxDB.createDatabase(dbName);
}
/**
* 删除資料庫
*
* @param dbName
*/
public void deleteDB(String dbName) {
influxDB.deleteDatabase(dbName);
}
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
public String getOpenurl() {
return openurl;
}
public void setOpenurl(String openurl) {
this.openurl = openurl;
}
public void setDatabase(String database) {
this.database = database;
}
} package application;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
*
* @author zyg
*
*/
@Configuration
public class InfluxDBConfiguration {
private String username = "admin";//使用者名
private String password = "admin";//密碼
private String openurl = "http://IP:8086";//InfluxDB連接配接位址
private String database = "test_db";//資料庫
@Bean
public InfluxDBConnect getInfluxDBConnect(){
InfluxDBConnect influxDB = new InfluxDBConnect(username, password, openurl, database);
influxDB.influxDbBuild();
influxDB.createRetentionPolicy();
return influxDB;
}
} package application;
import java.io.IOException;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import org.springframework.util.StringUtils;
import com.fasterxml.jackson.databind.ObjectMapper;
/**
*
* @author zyg
*
*/
@Component
public class Consumer {
protected final static Logger logger = LoggerFactory.getLogger(Consumer.class);
private ObjectMapper objectMapper = new ObjectMapper();
@Autowired
private InfluxDBConnect influxDB;
@RabbitListener(queues = RabbitMQConfig.QUEUE_NAME)
public void sendToSubject(org.springframework.amqp.core.Message message) {
String payload = new String(message.getBody());
logger.info(payload);
if (payload.startsWith("\"")) {
// Legacy payload from an Angel client
payload = payload.substring(1, payload.length() - 1);
payload = payload.replace("\\\"", "\"");
}
try {
if (payload.startsWith("[")) {
@SuppressWarnings("unchecked")
List<Map<String, Object>> list = this.objectMapper.readValue(payload, List.class);
for (Map<String, Object> map : list) {
sendMap(map);
}
} else {
@SuppressWarnings("unchecked")
Map<String, Object> map = this.objectMapper.readValue(payload, Map.class);
sendMap(map);
}
} catch (IOException ex) {
logger.error("Error receiving hystrix stream payload: " + payload, ex);
}
}
private void sendMap(Map<String, Object> map) {
Map<String, Object> data = getPayloadData(map);
data.remove("latencyExecute");
data.remove("latencyTotal");
Map<String, String> tags = new HashMap<String, String>();
tags.put("type", data.get("type").toString());
tags.put("name", data.get("name").toString());
tags.put("instanceId", data.get("instanceId").toString());
//tags.put("group", data.get("group").toString());
influxDB.insert("testaaa", tags, data);
// for (String key : data.keySet()) {
// logger.info("{}:{}",key,data.get(key));
// }
}
public static Map<String, Object> getPayloadData(Map<String, Object> jsonMap) {
@SuppressWarnings("unchecked")
Map<String, Object> origin = (Map<String, Object>) jsonMap.get("origin");
String instanceId = null;
if (origin.containsKey("id")) {
instanceId = origin.get("host") + ":" + origin.get("id").toString();
}
if (!StringUtils.hasText(instanceId)) {
// TODO: instanceid template
instanceId = origin.get("serviceId") + ":" + origin.get("host") + ":" + origin.get("port");
}
@SuppressWarnings("unchecked")
Map<String, Object> data = (Map<String, Object>) jsonMap.get("data");
data.put("instanceId", instanceId);
return data;
}
} 這裡不多說,就是接收RabbitMQ資訊然後儲存到InfluxDB資料庫中。
三、JVM相關資料采集
JVM相關資料采集非常簡單主要思想就是定時輪訓被監控服務的接口位址然後把傳回資訊插入到InfluxDB中
服務引用的包不多說這個服務是需要注冊到注冊中心Eureka中的因為需要擷取所有服務的監控資訊。
插入InfluxDB代碼和上面基本類似隻不過多了一個批量插入方法
package com.zjs.collection;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.netflix.eureka.EnableEurekaClient;
/**
*
* @author zyg
*
*/
@EnableEurekaClient
@SpringBootApplication
public class ApplictionCollection
{
public static void main(String[] args) {
SpringApplication.run(ApplictionCollection.class, args);
}
} /**
* 批量插入
*
* @param measurement
* 表
* @param tags
* 标簽
* @param fields
* 字段
*/
public void batchinsert(String measurement, Map<String, String> tags, List<Map<String, Object>> fieldslist) {
org.influxdb.dto.BatchPoints.Builder batchbuilder=BatchPoints.database(database);
for (Map<String, Object> map : fieldslist) {
Builder builder = Point.measurement(measurement);
tags.put("instanceId", map.get("instanceId").toString());
builder.time((long)map.get("currentTime"), TimeUnit.NANOSECONDS);
builder.tag(tags);
builder.fields(map);
batchbuilder.point(builder.build());
}
System.out.println(batchbuilder.build().toString());
influxDB.write(batchbuilder.build());
} package com.zjs.collection;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.client.ServiceInstance;
import org.springframework.cloud.client.discovery.DiscoveryClient;
import org.springframework.context.annotation.Bean;
import org.springframework.http.client.SimpleClientHttpRequestFactory;
import org.springframework.scheduling.annotation.EnableScheduling;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component;
import org.springframework.web.client.RestTemplate;
/**
* 擷取微服務執行個體
*
* @author zyg
*
*/
@Component
@SpringBootApplication
@EnableScheduling
public class MicServerInstanceInfoHandle {
protected final static Logger logger = LoggerFactory.getLogger(MicServerInstanceInfoHandle.class);
final String pathtail = "/metrics/mem.*|heap.*|threads.*|gc.*|nonheap.*|classes.*";
Map<String, String> tags;
ThreadPoolExecutor threadpool;
@Autowired
DiscoveryClient dc;
@Autowired
RestTemplate restTemplate;
final static LinkedBlockingQueue<Map<String, Object>> jsonMetrics = new LinkedBlockingQueue<>(1000);
/**
* 初始化執行個體 可以吧相關參數設定到配置檔案
*/
public MicServerInstanceInfoHandle() {
tags = new HashMap<String, String>();
threadpool = new ThreadPoolExecutor(4, 20, 60, TimeUnit.SECONDS, new ArrayBlockingQueue<>(100));
}
@Autowired
private InfluxDBConnect influxDB;
/**
* metrics資料擷取
*/
@Scheduled(fixedDelay = 2000)
public void metricsDataObtain() {
logger.info("開始擷取metrics資料");
List<String> servicelist = dc.getServices();
for (String str : servicelist) {
List<ServiceInstance> silist = dc.getInstances(str);
for (ServiceInstance serviceInstance : silist) {
threadpool.execute(new MetricsHandle(serviceInstance));
}
}
}
/**
* 将資料插入到influxdb資料庫
*/
@Scheduled(fixedDelay = 5000)
public void metricsDataToInfluxDB() {
logger.info("開始批量将metrics資料insert-influxdb");
ArrayList<Map<String, Object>> metricslist = new ArrayList<>();
MicServerInstanceInfoHandle.jsonMetrics.drainTo(metricslist);
if (!metricslist.isEmpty()) {
logger.info("批量插入條數:{}", metricslist.size());
influxDB.batchinsert("metrics", tags, metricslist);
}
logger.info("結束批量metrics資料insert");
}
@Bean
public RestTemplate getRestTemplate() {
RestTemplate restTemplate = new RestTemplate();
SimpleClientHttpRequestFactory achrf = new SimpleClientHttpRequestFactory();
achrf.setConnectTimeout(10000);
achrf.setReadTimeout(10000);
restTemplate.setRequestFactory(achrf);
return restTemplate;
}
class MetricsHandle extends Thread {
private ServiceInstance serviceInstanc;
public MetricsHandle(ServiceInstance serviceInstance){
serviceInstanc=serviceInstance;
}
@Override
public void run() {
try {
logger.info("擷取 {}:{}:{} 應用metrics資料",serviceInstanc.getServiceId(),serviceInstanc.getHost(),serviceInstanc.getPort());
@SuppressWarnings("unchecked")
Map<String, Object> mapdata = restTemplate
.getForObject(serviceInstanc.getUri().toString() + pathtail, Map.class);
mapdata.put("instanceId", serviceInstanc.getServiceId() + ":" + serviceInstanc.getHost() + ":"
+ serviceInstanc.getPort());
mapdata.put("type", "metrics");
mapdata.put("currentTime", System.currentTimeMillis() * 1000000);
MicServerInstanceInfoHandle.jsonMetrics.add(mapdata);
} catch (Exception e) {
logger.error("instanceId:{},host:{},port:{},path:{},exception:{}", serviceInstanc.getServiceId(),
serviceInstanc.getHost(), serviceInstanc.getPort(), serviceInstanc.getUri(),
e.getMessage());
}
}
}
} 這裡簡單解釋一下這句代碼 final String pathtail = "/metrics/mem.*|heap.*|threads.*|gc.*|nonheap.*|classes.*"; ,metrics這個路徑下的資訊很多但是我們不是都需要是以我們需要有選擇的擷取這樣節省流量和時間。上面關鍵類MicServerInstanceInfoHandle做了一個多線程通路主要應對注冊中心有成百上千個服務的時候單線程可能輪序不過來,同時做了一個隊列緩沖,批量插入到InfluxDB。
四、結果展示
如果你資料采內建功了就可以繪制出來上面的圖形下面是對應的sql
SELECT mean("rollingCountFallbackSuccess"), mean("rollingCountSuccess") FROM "testaaa" WHERE ("instanceId" = 'IP:spring-cloud-server1-test:8082' AND "type" = 'HystrixCommand') AND $timeFilter GROUP BY time($__interval) fill(null)
SELECT mean("currentPoolSize") FROM "testaaa" WHERE ("type" = 'HystrixThreadPool' AND "instanceId" = '10.10.12.51:spring-cloud-server1-test:8082') AND $timeFilter GROUP BY time($__interval) fill(null) SELECT "heap", "heap.committed", "heap.used", "mem", "mem.free", "nonheap", "nonheap.committed", "nonheap.used" FROM "metrics" WHERE ("instanceId" = 'SPRING-CLOUD-SERVER1-TEST:10.10.12.51:8082') AND $timeFilter 好了到這裡就基本結束了。
五、優化及設想
上面的基礎服務肯定都是需要高可用的,毋庸置疑都是需要學習的。如果有時間我也會向大家一一介紹,大家亦可以去搜尋相關資料檢視!
可能有人問有一個叫telegraf的小插件直接就能收集相關資料進行聚合結果監控,
其實我之前也是使用的telegraf這個小工具但是發現一個問題,
就是每次被監控的應用重新開機的時候相關字段名就會變,
因為他采集使用的是類執行個體的名字作為字段名,這應我們會很不友善,每次重新開機應用我們都要重新設定sql語句這樣非常不友好,
再次感覺收集資料編碼難度不大是以自己就寫了收集資料的代碼!如果有哪位大神對telegraf比較了解可以解決上面我說的問題記得給我留言哦!在這裡先感謝!
有些地方是需要優化的,比如一些IP端口什麼的都是可以放到配置檔案裡面的。
還有一種想法就是我可不可以像收集性能資訊一樣直接應用來收集JVM資訊讓JVM相關資訊直接發送到MQ當中然後再插入InfluxDB中
六、總結
從spring boot到現在短短的2、3年時間就迅速變得火爆,知識體系也變得完善,開發成本越來越低,
是以普及程度就越來越高,微服務雖然很好但是我們也要很好的善于運用,監控就是重要的一環,
試想一下你的機房運作着成千上萬的服務,穩定運作和及時發現有問題的服務是多麼重要的一件事情!
希望以上對大家有所幫助