Hulu是美國領先的網際網路專業視訊服務平台,目前在美國擁有超過2000萬付費使用者。Hulu總部位于美國洛杉矶,北京辦公室是僅次于總部的第二大研發中心,也是從Hulu成立伊始就具有重要戰略地位的分支辦公室,獨立負責播放器開發,搜尋和推薦,廣告精準投放,大規模使用者資料處理,視訊内容基因分析,人臉識别,視訊編解碼等核心項目。
在視訊領域我們有大量的視訊轉碼任務;在廣告領域當我們需要驗證一個投放算法的效果時,我們需要為每種新的算法運作一個模拟的廣告系統來産出投放效果對比驗證;在AI領域我們需要對視訊提取幀,利用一些訓練架構産出模型用于線上服務。這一切都需要運作在一個計算平台上,Capos是Hulu内部的一個大規模分布式任務排程和運作平台。
Capos是一個容器運作平台,包含鏡像建構,任務送出管理,任務排程運作,日志收集檢視,Metrics收集,監控報警,垃圾清理各個元件。整個平台包含的各個子產品,如下圖所示:
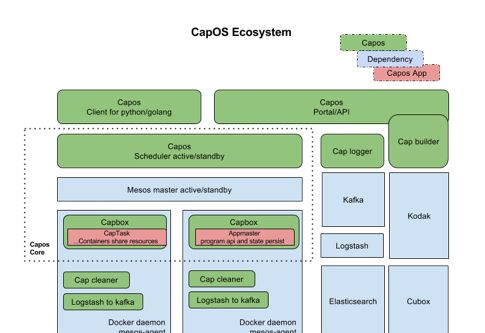
使用者可以在界面上建立鏡像描述符,綁定GitHub的repo,生成鏡像。之後在界面上建立作業描述符,填上鏡像位址,啟動參數,資源需求,選擇資源池,就可以運作作業,看作業運作日志等。這些所有操作也可以通過REST API來調用 ,對于一些進階的需求,Capos提供Golang和Python的SDK,可以讓使用者申請資源,然後啟動作業,廣告系統就是利用SDK,在Capos上面申請多個資源,靈活的控制這些資源的生命周期,一鍵啟動一個分布式的廣告系統來做模拟測試。
Capos大部分元件都是用Golang實作的,Capos的核心元件,任務排程運作CapScheduler是今天主要和大家分享和探讨的子產品。CapScheduler是一個基于Mesos的Scheduler,負責任務的接收,中繼資料的管理,任務排程。CapExecutor是Mesos的一個customized executor,實作Pod-like的邏輯,以及pure container resource的功能,在設計上允許Capos使用者利用Capos SDK複用計算資源做自定義排程。
Capos Scheduler的架構圖如下所示:

上圖淺藍色部分是Mesos的元件,包括Mesos master,Mesos agent,Mesos zookeeper。Mesos作用是把所有單體的主機的資源管理起來,抽象成一個CPU、Memory、Port、GPU等的資源池,供之上的Capos scheduler使用。
其中Capos scheduler是一個active-standy的HA模型,在scheduler中我們實作了一個raft based的k-v用來存儲Metadata,active的scheduler注冊成為Mesos之上的一個framework,可以收到資源,根據排程政策來啟動作業。
Capbox是一個定制實作的Mesos的executor,作為Mesos agent的資源的占位符,接收請求與Mesos agent上的Docker daemon通信啟動容器。其中也實作了POD-like的功能,同時可以啟動多個容器共享network,磁盤等。
Capos scheduler提供兩類作業運作,一個是簡單作業直接在Capbox運作,另一個是複雜帶有程式設計語義的作業,我們稱之為AppMaster,其本身運作占用一個CapBox,然後通過程式設計語義二次申請CapBox運作作業。
首先說明下簡單作業運作流程,這裡的簡單作業,送出的作業通過json描述,可以包含多個Container,然後scheduler收到請求之後,命中某個offer,向Mesos發送offer啟動請求,在請求中同時夾帶着作業json資訊,把作業啟動起來,scheduler根據Mesos狀态同步資訊來控制作業的生命周期。
如果是AppMaster Programmatically二次排程的作業,首先需要把AppMaster啟動,這部分和簡單作業運作是一緻的,然後AppMaster再申請一個到多個資源來啟動CapBox,運作作業。此時AppMaster申請的CapBox的生命周期完全由AppMaster決定,是以這裡AppMaster可以複用CapBox,或者批量申請CapBox完成自己特定的排程效果。多說一句,AppMaster可以支援client-mode和cluster-mode,client-mode是指AppMaster運作在叢集之外,這種情況适用于把AppMaster嵌入在使用者原先的程式之中,在某些場景更符合使用者的使用習慣。
說完Capos的使用方式後,我們可以聊下在Capos系統中一些設計的思考:
1、Scheduler的排程job和offer match政策,如下圖所示:
緩存offer。當scheduler從Mesos中擷取offer時候,Capos scheduler會把offer放入到cache,offer在TTL後,offer會被launch或者歸還給Mesos,這樣可以和作業和offer的置放政策解耦。
插件化的排程政策。Capos scheduler會提供一系列的可插拔的過濾函數和優先級函數,這些優先級函數對offer進行打分,作用于排程政策。使用者在送出作業的時候,可以組合過濾函數和優先級函數,來滿足不同workload的排程需求。
延遲排程。當一個作業標明好一個offer後,這個offer不會馬上被launch,scheduler會延遲排程,以期在一個offer中match更多作業後,再launch offer。擷取更高的作業排程吞吐。
2、Metadata的raft-base key value store
多個scheduler之間需要有一個分布式的kv store,來存儲作業的Metadata以及同步作業的狀态機。在scheduler downtime切換的時候,新的scheduler可以接管,做一些recovery工作後,繼續工作。
基于Raft實作的分布式一緻性存儲。Raft是目前業界最流行的分布式一緻性算法之一,Raft依靠leader和WAL(write ahead log)保證資料一緻性,利用Snapshot防止日志無限的增長,目前Raft各種語言均有開源實作,很多新興的資料庫都采用Raft作為其底層一緻性算法。Capos利用了etcd提供的raft lib, 實作了分布式的一緻性資料存儲方案。etcd為了增強lib的通用性,僅實作了Raft的核心算法,網絡及磁盤io需要由使用者自行實作。Capos中利用etcd提供的rafthttp包來完成網絡io,資料持久化方面利用channel并行化leader的本地資料寫入以及follower log同步過程,提高了吞吐率。
Capos大部分的子產品都是Golang開發,是以目前的實作是基于etcd的raft lib,底層的kv存儲可以用BoltDB,Badger和LevelDB。有些經驗可以分享下,在排程方面我們應該關注關鍵路徑上的消耗,我們起初有引入StormDB來自動的做一些key-value的index,來加速某些帶filter的查詢。後來benchmark之後發現,index特别在大規模meta存儲之後,性能下降明顯,是以目前用的純kv引擎。在追求高性能排程時候,寫會比讀更容器達到瓶頸,BoltDB這種b+ tree的實作是對讀友好的,是以排程系統中對于kv的選型應該着重考慮想LevelDB這種lsm tree的實作。如果更近一步,在lsm tree基礎上,考慮kv分離存儲,達到更高的性能,可以考慮用badger。不過最終選型,需要綜合考慮,是以我們底層存儲目前實作了BoltDB、Badger和LevelDB這三種引擎。
3、程式設計方式的AppMaster
簡單的作業可以直接把json描述通過REST API送出運作,我們這邊讨論的是,比較複雜場景的SaaS,可能使用者的workload是一種分布式小系統,需要多個Container資源的運作和配合。這樣需要Capos提供一種程式設計方式,申請資源,按照使用者需要先後在資源上運作子任務,最終完成複雜作業的運作。
我們提供的程式設計原語如下:
Capbox.go capbox是Capos中資源的描述:
AppMaster可以用這些API申請資源,釋放資源,擷取資源的狀态更新,在此基礎上可以實作靈活的排程。
Task.go task也就是可以在Capbox上運作的task,如下圖所示:
在資源基礎上,appmaster可以用api啟動/停止作業,appmaster也可以複用資源不斷的啟動新的作業。基于以上的api,我們可以把廣告模拟系統,AI架構tensorflow,xgboost等分布式系統運作在Capos之上。
4、Capos對比下Netflix開源的Titus和Kubernetes
Netflix在今年開源了容器排程架構Titus,Titus是一個Mesos framework,titus-master是基于fenso lib的Java based scheduler,meta存儲在cassandra中。titus-executor是Golang的Mesos customized executor。因為是Netflix的系統,是以和AWS的一些設施是綁定的,基本上在私有雲中不太适用。
Kubernetes是編排服務方面很出色,在擴充性方面有Operator,Multiple Scheduler,CRI等,把一切可以開放實作的都接口化,是衆人拾柴的好思路,但是在大規模排程短作業方面還是有提升空間。
Capos是基于Mesos之上的排程,主要focus在大規模叢集中達到作業的高吞吐排程運作。
在分布式排程編排領域,有諸多工業界和學術界的作品,比如開源産品Mesos,Kubernetes,YARN,排程算法Flow based的Quincy,Firmament。在long run service,short term workload以及function call需求方面有Service Mesh,微服務,CaaS,FaaS等解決思路,私有雲和公有雲的百家争鳴的解決方案和角度,整個生态還是很有意思的。絕技源于江湖、将軍發于卒伍,希望這次分享可以給大家帶來一些啟發,最後感謝Capos的individual contributor(字母序):chenyu.zheng、fei.liu、guiyong.wu、huahui.yang、shangyan.zhou、wei.shao。
Q&A
Q:Capos如何處理健康檢查?之前了解到,Mesos内置的健康檢查不是特别完善。
A:目前Capos focus的作業大部分都是短作業類型,是以我們目前就是通過容器的退出碼來判斷success或者fail,如果你說的健康檢查是針對服務的,一般實作是支援多種健康檢查的方式,bash,http等,然後為了大規模容器運作情況下的可用性,建議這種健康檢查的發起client和服務instance是在一台機器上,或者是一個Pod中,發現不健康通過某種機制上報,或者退出Container,但是需要控制Threshold以免整個服務downtime。這樣可以探測instance的健康,整個服務的健康,可以在通過外部的一些子系統去check。
Q:關于排程方面,分享中隻提到了使用了一系列的可插拔的過濾函數和優先級函數,我想問下能否具體描述下如何被排程的?和yarn裡使用的Fair Schedule或者DRF算法的異同有哪些?因為對于多種資源次元的排程是一個很複雜的問題,希望知道Hulu這方面有什麼心得和思考?
A:目前實作是,會針對一個請求,首先根據過濾函數比如一些constraints進行offer過濾,然後剩下的offer apply所有的優先級打分函數,進行打分,打分的時候,會根據一個請求和offer的資源,算CPU和mem的比例,選取出dominate的resource進行主要評分,然後選取最優的offer進行bind,bind之後不會馬上排程,而是會delay scheduler,這樣一般在比較繁忙的情況下,一次offer launch可以啟動多個tasks,這是對于大規模吞吐的考慮。 以上這些實作還是queue-base的排程,借鑒了一些Fair Schedule和drf的思路,具體差别你了解了Capos scheduler政策後,應該就會有自己的想法了。多種資源次元,目前我們是根據dominate resource作為主要評分标準的,當然你也可以看下我最後分享提到的一些flow-base的scheduler算法,比如firmament。希望可以回答你的問題。
Q:Capos是否支援,資料中心之間的備份/切換。比如Zone - A的資料中心出現網絡故障,把服務遷移到另一個指定的區域 Zone - B(仍然考慮恢複以後優先部署到 Zone - A)。之前考慮是類似一個Mask的機制,如果故障就加一定的Mask值(比如Opcacity)在某個叢集上,然後排程的時候去參考這個Mask值,不知道Hulu有沒有類似的需求或者考慮過這樣的機制?
A:Capos是on Mesos,Mesos是根據zk做選主,而且Capos scheduler中還有一個raft base key value store,是以這些條件,使得Capos是一個datacenter的解決方案。目前Hulu是有多個DataCenter的,是以看架構元件圖,你可以看到,我們有一個Capos portal,在這個元件下,是可以選擇不同DataCenter去run workload。是以我們目前對于資料中心的備份和切換,主要是依賴Capos portal這個元件,在Gateway的位置做的控制。
Q:想請問下Capos的鑒權是怎麼做的,有沒有使用者權限認證系統?此外,針對每個使用者有沒有容器資源使用量的限制?
A:可以翻到之前share的架構元件圖,我們有一個Capos portal元件,這個元件是提供Restful API和Portal,我們在這邊內建Hulu SSO,然後關聯Hulu yellowpages(Hulu的服務權限控制系統),做的使用者的認證,我們分成自己的Capos APP, team的APP,别的組無法操作不屬于自己的Capos APP。對于Quota的管理,我們做了Queue/Label機制,每個服務會建一個辨別,然後在辨別底下配置總的資源使用量,以及可以用的機器清單(通配符),用這樣的機制控制Capos的使用者資源使用。
原文釋出時間為:2018-07-20
本文作者:楊華輝
本文來自雲栖社群合作夥伴“
Golang語言社群”,了解相關資訊可以關注“
”