本文由 網易雲 釋出。
Kudu是Cloudera開源的新型列式存儲系統,是Apache Hadoop生态圈的新成員之一(incuba ng),專門為了對快速變化的資料進行快速的分析,填補了以往Hadoop存儲層的空缺。本文主要對Kudu的動機、背景,以及架構進行簡單介紹。
背景——功能上的空白
Hadoop生态系統有很多元件,每一個元件有不同的功能。在現實場景中,使用者往往需要同時部署很多Hadoop工具來解決同一個問題,這種架構稱為混合架構 (hybrid architecture)。比如,使用者需要利用Hbase的快速插入、快讀 random access的特性來導入資料,HBase也允許使用者對資料進行修改,HBase對于大量小規模查詢也非常迅速。同時,使用者使用HDFS/Parquet + Impala/Hive來對超大的資料集進行查詢分析,對于這類場景, Parquet這種列式存儲檔案格式具有極大的優勢。
很多公司都成功地部署了HDFS/Parquet + HBase混合架構,然而這種架構較為複雜,而且在維護上也十分困難。首先,使用者用Flume或Ka a等資料Ingest工具将資料導入HBase,使用者可能在HBase上對資料做一些修改。然後每隔一段時間(每天或每周)将資料從Hbase中導入到Parquet檔案,作為一個新的par on放在HDFS上,後使用Impala等計算引擎進行查詢,生成最終報表。
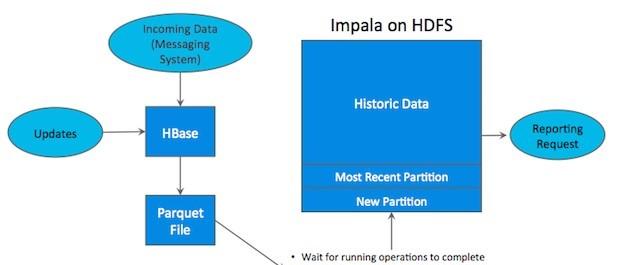
這樣一條工具鍊繁瑣而複雜,而且還存在很多問題,比如:
如何處理某一過程出現失敗?
從HBase将資料導出到檔案,多久的頻率比較合适?
當生成終報表時,最近的資料并無法展現在最終查詢結果上。
維護叢集時,如何保證關鍵任務不失敗?
Parquet是immutable,是以當HBase中删改某些曆史資料時,往往需要人工幹預進行同步。
這時候,使用者就希望能夠有一種優雅的存儲解決方案,來應付不同類型的工作流,并保持高性能的計算能力。Cloudera很早就意識到這個問題,在2012年就開始計劃開發Kudu這個存儲系統,終于在2015年釋出并開源出來。
Kudu是對HDFS和HBase功能上的補充,能提供快速的分析和實時計算能力,并且充分利用CPU和I/O資源,支援資料原地修改,支援簡單的、可擴充的資料模型。
背景——新的硬體裝置
RAM的技術發展非常快,它變得越來越便宜,容量也越來越大。Cloudera的客戶資料顯示,他們的客戶所部署的伺服器,2012年每個節點僅有32GB RAM,現如今增長到每個節點有128GB或256GB RAM。儲存設備上更新也非常快,在很多普通伺服器中部署SSD也是屢見不鮮。HBase、HDFS、以及其他的Hadoop工具都在不斷自我完善,進而适應硬體上的更新換代。然而,從根本上,HDFS基于03年GFS,HBase基于05年BigTable,在當時系統瓶頸主要取決于底層磁盤速度。當磁盤速度較慢時,CPU使用率不足的根本原因是磁盤速度導緻的瓶頸,當磁盤速度提高了之後,CPU使用率提高,這時候CPU往往成為系統的瓶頸。HBase、HDFS由于年代久遠,已經很難從基本架構上進行修改,而Kudu是基于全新的設計,是以可以更充分地利用RAM、I/O資源,并優化CPU使用率。我們可以了解為,Kudu相比與以往的系統,CPU使用降低了,I/O的使用提高了,RAM的利用更充分了。
簡介
Kudu設計之初,是為了解決一下問題:
對資料掃描(scan)和随機通路(random access)同時具有高性能,簡化使用者複雜的混合架構
高CPU效率,使使用者購買的先進處理器的的花費得到最大回報
支援資料的原地更新,避免額外的資料處理、資料移動
支援跨資料中心replica on
Kudu的很多特性跟HBase很像,它支援索引鍵的查詢和修改。Cloudera曾經想過基于Hbase進行修改,然而結論是對HBase的改動非常大,Kudu的資料模型和磁盤存儲都與Hbase不同。HBase本身成功的适用于大量的其它場景,是以修改HBase很可能吃力不讨好。 後Cloudera決定開發一個全新的存儲系統。

Kudu的定位是提供”fast analy cs on fast data”,也就是在快速更新的資料上進行快速的查詢。它定位OLAP和少量的OLTP工作流,如果有大量的randomaccesses,官方建議還是使用HBase為合适。
架構與設計
1.基本架構
Kudu是用于存儲結構化(structured)的表(Table)。表有預定義的帶類型的列(Columns),每張表有一個主鍵(primary key)。主鍵帶有唯一性(uniqueness)限制,可作為索引用來支援快速的random access。
類似于BigTable,Kudu的表是由很多資料子集構成的,表被水準拆分成多個Tablets. Kudu用以每個tablet為一個單元來實作資料的durability。Tablet有多個副本,同時在多個節點上進行持久化。
Kudu有兩種類型的元件,Master Server和TabletServer。Master負責管理中繼資料。這些中繼資料包括talbet的基本資訊,位置資訊。Master還作為負載均衡伺服器,監聽Tablet Server的健康狀态。對于副本數過低的Tablet,Master會在起replicaon任務來提高其副本數。Master的所有資訊都在記憶體中cache,是以速度非常快。每次查詢都在百毫秒級别。Kudu支援多個Master,不過隻有一個ac veMaster,其餘隻是作為災備,不提供服務。
Tablet Server上存了10~100個Tablets,每個Tablet有3(或5)個副本存放在不同的Tablet Server上,每個Tablet同時隻有一個leader副本,這個副本對使用者提供修改操作,然後将修改結果同步給follower。Follower隻提供讀服務,不提供修改服務。副本之間使用ra 協定來實作High Availability,當leader所在的節點發生故障時,followers會重新選舉 leader。根據官方的資料,其MTTR約為5秒,對client端幾乎沒有影響。Ra 協定的另一個作用是實作Consistency。
Client對leader的修改操作,需要同步到N/2+1個節點上,該操作才算成功。
Kudu采用了類似log-structured存儲系統的方式,增删改操作都放在記憶體中的buffer,然後才merge到持久化的列式存儲中。Kudu還是用了WALs來對記憶體中的buffer進行災備。
2.列式存儲
持久化的列式存儲存儲,與HBase完全不同,而是使用了類似Parquet的方式,同一個列在磁盤上是作為一個連續的塊進行存放的。例如,圖中左邊是twi er儲存推文的一張表,而圖中的右邊表示了表在磁盤中的的存儲方式,也就是将同一個列放在一起存放。這樣做的第一個好處是,對于一些聚合和join語句,我們可以盡可能地減少磁盤的通路。例如,我們要使用者名為newsycbot的推文數量,使用查詢語句:
SELECT COUNT(*) FROM tweets WHEREuser_name = ‘newsycbot’;
我們隻需要查詢User_name這個block即可。同一個列的資料是集中的,而且是相同格式的,Kudu可以對資料進行編碼,例如字典編碼,行長編碼,bitshuffle等。通過這種方式可以很大的減少資料在磁盤上的大小,提高吞吐率。除此之外,使用者可以選擇使用通用的壓縮格式對資料進行壓縮,如LZ4, gzip, 或bzip2。這是可選的,使用者可以根據業務場景,在資料大小和CPU效率上進行權衡。這一部分的實作上,Kudu很大部分借鑒了Parquet的代碼。
HBase支援snappy存儲,然而因為它的LSM的資料存儲方式,使得它很難對資料進行特殊編碼,這也是Kudu聲稱具有很快的scan速度的一個很重要的原因。不過,因為列式編碼後的資料很難再進行修改,是以當這寫資料寫入磁盤後,是不可變的,這部分資料稱之為base資料。Kudu用MVCC(多版本并發控制)來實作資料的删改功能。更新、删除操作需要記錄到特殊的資料結構裡,儲存在記憶體中的DeltaMemStore或磁盤上的DeltaFIle裡面。 DeltaMemStore是B-Tree實作的,是以速度快,而且可修改。磁盤上的DeltaFIle是二進制的列式的塊,和base資料一樣都是不可修改的。是以當資料頻繁删改的時候,磁盤上會有大量的DeltaFiles檔案,Kudu借鑒了Hbase的方式,會定期對這些檔案進行合并。
3.對外接口
Kudu提供C++和JAVA API,可以進行單條或批量的資料讀寫,schema的建立修改。除此之外,Kudu還将與hadoop生态圈的其它工具進行整合。目前,kudu beta版本對Impala支援較為完善,支援用Impala進行建立表、删改資料等大部分操作。Kudu還實作了KuduTableInputFormat和KuduTableOutputFormat,進而支援Mapreduce的讀寫操作。同時支援資料的locality。目前對spark的支援還不夠完善,spark隻能進行資料的讀操作。
使用案例——小米
小米是Hbase的重度使用者,他們每天有約50億條使用者記錄。小米目前使用的也是HDFS + HBase這樣的混合架構。可見該流水線相對比較複雜,其資料存儲分為SequenceFile,Hbase和Parquet。
在使用Kudu以後,Kudu作為統一的資料倉庫,可以同時支援離線分析和實時互動分析。
性能測試
1. 和parquet的比較
圖是官方給出的用Impala跑TPC-H的測試,對比Parquet和Kudu的計算速度。從圖中我們可以發現,Kudu的速度和parquet的速度差距不大,甚至有些Query比parquet還快。然而,由于這些資料都是在記憶體緩存過的,是以該測試結果不具備參考價值。
2.和Hbase的比較
圖是官方給出的另一組測試結果,從圖中我們可以看出,在scan和range查詢上,kudu和parquet比HBase快很多,而randomaccess則比HBase稍慢。然而資料集隻有60億行資料,是以很可能這些資料也是可以全部緩存在記憶體的。對于從記憶體查詢,除了random access比HBase慢之外,kudu的速度基本要優于HBase。
3.超大資料集的查詢性能
Kudu的定位不是in-memorydatabase。因為它希望HDFS/Parquet這種存儲,是以大量的資料都是存儲在磁盤上。如果我們想要拿它代替HDFS/Parquet + HBase,那麼超大資料集的查詢性能就至關重要,這也是Kudu的最初目的。然而,官方沒有給出這方面的相關資料。由于條件限制,網易暫時未能完成該測試。下一步,我們将計劃搭建10台Kudu + Impala伺服器,并用tpc-ds生成超大資料,來完成該對比測驗。
想要了解網易大資料,請戳這裡網易大資料|專業的私有化大資料平台
了解 網易雲 :
網易雲官網:https://www.163yun.com/
新使用者大禮包:https://www.163yun.com/gift
網易雲社群:https://sq.163yun.com/