本文由 網易雲 釋出。
1 概述
本文主要介紹kudu底層存儲引擎的資料組織方式,先看整體結構如下:
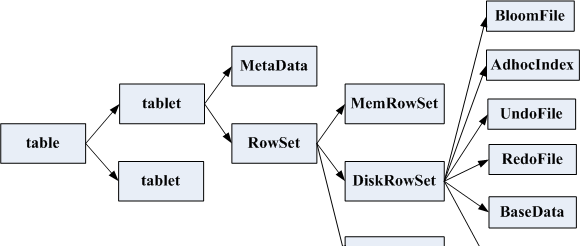
一張表會分成若幹個tablet , 每個tablet 包括MetaData 元資訊及若幹個RowSet , RowSet 包含一個MemRowSet 及若幹個DiskRowSet , DiskRowSet 中 包 含 一 個 BloomFile 、 Ad_hoc Index 、 BaseData 、 DeltaMem 及 若 幹 個 RedoFile 和UndoFile(UndoFile一般情況下隻有一個)。
MemRowSet用于新資料insert及已在MemRowSet中的資料的更新,一個MemRowSet寫滿後會将資料刷到磁盤形成若幹個DiskRowSet。
DiskRowSet用于老資料的mutation,背景定期對DiskRowSet做compaction,以删除沒用的資料及合并曆史資料,減少查詢過程中的IO開銷。
BloomFile根據一個DiskRowSet中的key生成一個bloom filter,用于快速模糊定位某個key是否在DiskRowSet中存在。Ad_hoc Index是主鍵的索引,用于定位key在DiskRowSet中的具體哪個偏移位置。
BaseData 是 MemRowSet flush 下 來 的 數 據 , 按 列 存 儲 , 按 主 鍵 有 序 。UndoFile是基于BaseData之前時間的曆史資料,通過在BaseData上apply UndoFile中的記錄,可以獲得曆史資料。RedoFile是基于BaseData之後時間的mutation記錄,通過在BaseData上apply RedoFile中的記錄,可獲得較新的資料。DeltaMem用于DiskRowSet中資料的mutation,先寫到記憶體中,寫滿後flush到磁盤形成RedoFile。
2 MemRowSet
MemRowSet的資料組織形式是一顆B+Tree,結構如下:

這顆B+樹實作的比較簡單,因為它沒有update跟delete操作,kudu在MemRowSet中中資料的mutation采用類似append log 方式,在base資料上有個mutation指針,所有的後續mutation操作都挂在這個指針上了。
雖然隻有插入,但是也會出現節點滿時需要做split,同時可能有讀操作也在同步進行,kudu使用AtomicVersion(原子變量+位移)實作了一個鎖。樹的度跟cpu的CACHELINE_SIZE有關,是為了讓一個節點僅讀取一次cpu cache。
樹的檢索是先找到key所在的LeafNode,然後在LeafNode内部進行二分查找,LeafNode間有指針進行串聯,為了友善scan,掃整個MemRowSet一般通過一個空串的key找到第一個LeafNode,然後依次讀資料。
3 DiskRowSet
這部分是kudu存儲部分最複雜的東西,分為兩個部分來講,DiskRowSet間的組織,DiskRowSet内資料組織,先看DiskRowSet 間怎麼組織的。
3.1 DiskRowSet間組織
一個tablet随這資料的不斷寫入會包含很多個DiskRowSet,每個DiskRowSet上有min_key、max_key标明key的範圍,如果要查找一個key在哪個DiskRowSet上依次周遊每個DiskRowSet效率是很低的,這種情況線段樹這種資料結構是很适合做range索引的,将所有的DiskRowSet形成一顆線段樹,結構如下:
其實就是一個二叉平衡樹,每次從所有range(最小的min_key跟最大的max_key)的中間key做split,将range跨域左右子樹的
DiskRowSet(即split point落在DiskRowSet的min_key與max_key之間)放到overlap rowsets中去。這顆樹實作的也很簡單, 因為它隻做查詢用,生成後就不會變動,若遇到MemRowSet flush或DiskRowSet Merge Compaction就直接重新生成一顆新樹。
這個樹主要用于在讀或寫的時候定位某個或若幹個key 在哪些DiskRowSet 的range 範圍内, 隻能通過DiskRowSet 的min_key/max_key做一層模糊過濾,是否正在存在需要做進一步檢查。
3.2 DiskRowSet内資料組織
一個DiskRowSet大體資料組織上面概述中已介紹過,其中DeltaMem跟MemRowSet在記憶體中的組織方式是一樣的,都是B+Tree,而在磁盤上的存儲都是放在CFile中的,下面我們看看CFile的檔案格式:
CFile包含Header、Data、Index、Footer幾塊,其中Data部分起始部分是為空值的條目建立的bitmap,僅針對可為null的
column,對于主鍵是沒有這個的,bitmap就是以那些值為null的RowId建立起來的位圖,這樣Data中就不用存這些空值。data部分不同的column類型檔案會有不同的編碼方式:
對于ad_hoc檔案使用的是prefix,delta file使用的是plain,bloomfile使用的是plain。每種BlockBuilder在處理一定量資料後就會append到Data中。
Index有兩種,posidx_index是根據RowId找到在Data中的偏移,validx index是根據key的值找到在Data中的偏移,validx隻針對隻有一個column為key的情況,這個時候DiskRowSet沒有Ad_hoc索引,使用validex來代替。這兩個index内部實作是一個B- Tree,index不一定是連續的,在達到一定長度後就會刷盤,而内部可以區分是中間節點還是葉子節點及其孩子節點的位置。
Footer是記錄了CFile的元資訊,包括posidx_index、validx_index兩棵樹根節點所在位置,資料條目、編碼、壓縮方式等。下面看看DiskRowSet資料在磁盤上的分布:
在磁盤上每個DiskRowSet有若幹個***.metadata及***.data檔案,metadata檔案記錄的是DiskRowSet的元資訊,主要包括哪些block及block在data中的位置,上圖為block與DiskRowSet中各部分的映射關系,在寫磁盤是通過container來寫,每個container 可以寫很大一塊連續的磁盤空間, 用于給某個CFile寫資料, 當一個CFile寫完後會将container歸還給BlockManager, 這時container就可以用于下個CFile寫資料了,當BlockManager中沒有container可用時會建立一個container給新來的CFile使用。
對于建立block先看看有無container可用,若沒有目前預設是在所有配置中的data_dir中随機選取一個dir中建一個新的metadata 及data檔案。先寫data,block落盤後再寫metadata。
對于kudu底層資料存儲就介紹到這裡,希望對大家有所幫助。
想要了解網易大資料,請戳這裡網易大資料|專業的私有化大資料平台
了解 網易雲 :
網易雲官網:https://www.163yun.com/
新使用者大禮包:https://www.163yun.com/gift
網易雲社群:https://sq.163yun.com/