摘要:使用Spark SQL進行ETL任務,在讀取某張表的時候報錯:“IOException: totalValueCount == 0”,但該表在寫入時,并沒有什麼異常。
本文分享自華為雲社群《你的Parquet該更新了:IOException: totalValueCount == 0問題定位之旅》,原文作者:wzhfy 。
1. 問題描述
使用Spark SQL進行ETL任務,在讀取某張表的時候報錯:“IOException: totalValueCount == 0”,但該表在寫入時,并沒有什麼異常。
2. 初步分析
該表的結果是由兩表join後生成。經分析,join的結果産生了資料傾斜,且傾斜key為null。Join後每個task寫一個檔案,是以partition key為null的那個task将大量的null值寫入了一個檔案,null值個數達到22億。
22億這個數字比較敏感,正好超過int最大值2147483647(21億多)。是以,初步懷疑parquet在寫入超過int.max個value時有問題。
【注】本文隻關注大量null值寫入同一個檔案導緻讀取時報錯的問題。至于該列資料産生如此大量的null是否合理,不在本文讨論範圍之内。
3. Deep dive into Parquet (version 1.8.3,部分内容可能需要結合Parquet源碼進行了解)
入口:Spark(Spark 2.3版本) -> Parquet
Parquet調用入口在Spark,是以從Spark開始挖掘調用棧。
InsertIntoHadoopFsRelationCommand.run()/SaveAsHiveFile.saveAsHiveFile() -> FileFormatWriter.write()
這裡分幾個步驟:
- 啟動作業前,建立outputWriterFactory: ParquetFileFormat.prepareWrite()。這裡會設定一系列與parquet寫檔案有關的配置資訊。其中主要的一個,是設定WriteSupport類:ParquetOutputFormat.setWriteSupportClass(job, classOf[ParquetWriteSupport]),ParquetWriteSupport是Spark自己定義的類。
- 在executeTask() -> writeTask.execute()中,先通過outputWriterFactory建立OutputWriter (ParquetOutputWriter):outputWriterFactory.newInstance()。
- 對于每行記錄,使用ParquetOutputWriter.write(InternalRow)方法依次寫入parquet檔案。
- Task結束前,調用ParquetOutputWriter.close()關閉資源。
3.1 Write過程
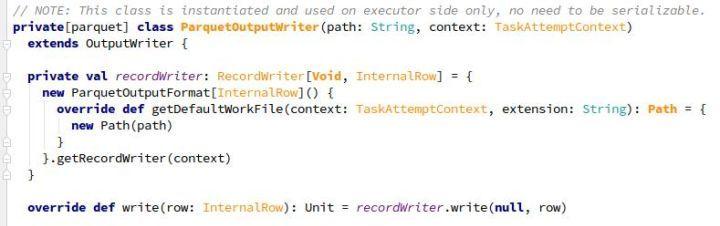
在ParquetOutputWriter中,通過ParquetOutputFormat.getRecordWriter構造一個RecordWriter(ParquetRecordWriter),其中包含了:
- prepareWrite()時設定的WriteSupport:負責轉換Spark record并寫入parquet結構
- ParquetFileWriter:負責寫入檔案
ParquetRecordWriter中,其實是把write操作委托給了一個internalWriter(InternalParquetRecordWriter,用WriteSupport和ParquetFileWriter構造)。
現在讓我們梳理一下,目前為止的大緻流程為:
SingleDirectoryWriteTask/DynamicPartitionWriteTask.execute
-> ParquetOutputWriter.write -> ParquetRecordWriter.write -> InternalParquetRecordWriter.write
接下來,InternalParquetRecordWriter.write裡面,就是三件事:

(1)writeSupport.write,即ParquetWriteSupport.write,裡面分三個步驟:
-
- MessageColumnIO.MessageColumnIORecordConsumer.startMessage;
- ParquetWriteSupport.writeFields:寫入一行中各個列的值,null值除外;
-
MessageColumnIO.MessageColumnIORecordConsumer.endMessage:針對第二步中的missing fields寫入null值。
ColumnWriterV1.writeNull -> accountForValueWritten:
1) 增加計數器valueCount (int類型)
2) 檢查空間是否已滿,需要writePage - 檢查點1
(2)增加計數器recordCount(long類型)
(3)檢查block size,是否需要flushRowGroupToStore - 檢查點2
由于寫入的值全是null,在1、2兩個檢查點的memSize都為0,是以不會重新整理page和row group。導緻的結果就是,一直在往同一個page裡增加null值。而ColumnWriterV1的計數器valueCount是int類型,當超過int.max時,溢出,變為了一個負數。
是以,隻有當調用close()方法時(task結束時),才會執行flushRowGroupToStore:
ParquetOutputWriter.close -> ParquetRecordWriter.close
-> InternalParquetRecordWriter.close -> flushRowGroupToStore
-> ColumnWriteStoreV1.flush -> for each column ColumnWriterV1.flush
由于valueCount溢出為負,此處也不會寫page。
因為未調用過writePage,是以此處的totalValueCount一直為0。
ColumnWriterV1.writePage -> ColumnChunkPageWriter.writePage -> 累計totalValueCount
在write結束時,InternalParquetRecordWriter.close -> flushRowGroupToStore -> ColumnChunkPageWriteStore.flushToFileWriter -> for each column ColumnChunkPageWriter.writeToFileWriter:
- ParquetFileWriter.startColumn:totalValueCount指派給currentChunkValueCount
- ParquetFileWriter.writeDataPages
- ParquetFileWriter.endColumn:currentChunkValueCount(為0)和其他中繼資料資訊構造出一個ColumnChunkMetaData,相關資訊最終會被寫入檔案。
3.2 Read過程
同樣以Spark為入口,進行檢視。
初始化階段:ParquetFileFormat.BuildReaderWithPartitionValues -> VectorizedParquetRecordReader.initialize -> ParquetFileReader.readFooter -> ParquetMetadataConverter.readParquetMetadata -> fromParquetMetadata -> ColumnChunkMetaData.get,其中包含valueCount(為0)。
讀取時:VectorizedParquetRecordReader.nextBatch -> checkEndOfRowGroup:
1) ParquetFileReader.readNextRowGroup -> for each chunk, currentRowGroup.addColumn(chunk.descriptor.col, chunk.readAllPages())
由于getValueCount為0,是以pagesInChunk為空。
2)構造ColumnChunkPageReader:
由于page清單為空,是以totalValueCount為0,導緻在構造VectorizedColumnReader時報了問題中的錯誤。
4. 解決方法:Parquet更新(version 1.11.1)
在新版本中,ParquetWriteSupport.write ->
MessageColumnIO.MessageColumnIORecordConsumer.endMessage ->
ColumnWriteStoreV1(ColumnWriteStoreBase).endRecord:
在endRecord中增加了每個page最大記錄條數(預設2w條)的屬性和檢查邏輯,超出限制時會writePage,使得ColumnWriterV1的valueCount不會溢出(每次writePage後會清零)。
而對比老版本1.8.3中,ColumnWriteStoreV1.endRecord為空函數。
附:Parquet中的一個小trick
Parquet中為了節約空間,當一個long類型的值,在一定範圍内時,會使用int來存儲,其方法如下:
- 判斷是否可以用int存儲:
- 如果可以,用IntColumnChunkMetaData代替LongColumnChunkMetaData,構造時轉換:
- 使用時,再轉回來,IntColumnChunkMetaData.getValueCount -> intToPositiveLong():
普通的int範圍是 -2^31 ~ (2^31 - 1),由于中繼資料資訊(如valueCount等)都是非負整數,那麼實際隻能存儲0 ~ (2^31 - 1) 範圍的數。而用這種方法,可以表示0 ~ (2^32 - 1) 範圍的數,表達範圍也大了一倍。
附件:可用于複現的測試用例代碼(依賴Spark部分類,可置于Spark工程中運作)