大量複雜、亂序的圖檔依次标注效率極低,如果一次可以标注一大片的圖檔将極大地提升标注效率。
自動分組識别并提取圖像特征,通過ModelArts先進的聚類算法可以将所有圖檔分組:将特征相似的圖檔歸為一類,将特征差别大的圖檔群分離。
在花朵識别項目中,需對大量無标注的花朵圖檔進行标注,依次亂序标注蒲公英、郁金香、向日葵等将耗費大量寶貴時間
分組标注場景
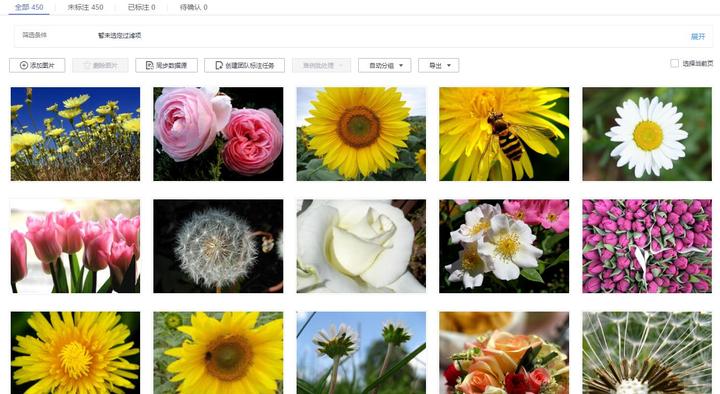
啟動自動分組,我們事先知道花朵資料集中存在5個類别,為他們分組6類(聚類算法不能保證一定将5類别完全區分出來,需更細化地分組,于是往往分組數需大于實際類别數):

過約3分鐘後,通過篩選條件,我們可以得到自動分組的結果,如第1類幾乎都是郁金香的圖檔,第3類幾乎都是蒲公英的圖檔。
第1類
第3類
于是選擇目前頁 -> 輸入蒲公英 ,即可直接對他們一次性進行标注。
當然并不是每個組都是完美的,如一個組中大多都是向日葵,但還夾雜着非洲菊 。此時選擇目前頁後,去掉相應非向日葵圖檔左上角的勾即可:
資料過濾場景
現實中的真實圖像資料量少,往往無法滿足深度學習網絡訓練資料量的要求,于是開發者們一般選擇網絡爬取需要的圖檔,但爬取下來的圖檔風格迥異、噪聲雜多,想要從中提取需要的圖檔工作量是巨大的。
ModelArts提供的自動分組算法除了在分組标注上功能強大,在資料過濾場景上也是奇技淫巧 。
在安全帽項目中,由于實際安全帽圖像過少,從谷歌爬取了大量安全帽相關圖像(約3000張):
但是這些并不全是我們想要的“安全帽”,我們需要工地為背景,且勞工類型的安全帽。
于是在自動分組中我們對這些圖像細分為10個組(越大的分組數對資料集分組越細,能分離出更多噪聲圖像),以下為部分組的展示:
第0組
第1組
第4組
第9組
顯然類似第1組和第9組的圖檔才是我們需要的結果,第1組和第4組浏覽大緻後可以全部删除,選擇目前頁并删除:
删掉噪聲圖像後,隻剩下約1600張,過濾了快50%的圖像:
當然如果還存在很多噪聲,我們繼續進行分組,對剩下的1640張圖再自動分組10個類
可以看到,依舊有許多與安全帽不相幹的圖像如:
再一次浏覽所有分組,對資料進行清洗,最終隻剩下1008張圖像,過濾了約65%的噪聲圖像,極大地降低了标注的壓力。
點選關注,第一時間了解華為雲新鮮技術~