本文首發于 vivo網際網路技術 微信公衆号
連結:
https://mp.weixin.qq.com/s/oAD25H0UKH4zujxFDRXu9Q 作者:wenbo zhang
【領域驅動設計實踐之路】往期精彩文章:
- 《 領域驅動設計(DDD)實踐之路(一) 》 主要講述了戰略層面的DDD原則
- 領域驅動設計(DDD)實踐之路(二):事件驅動與CQRS 》分析了如何應用事件來分離軟體核心複雜度。
這是“領域驅動設計實踐之路”系列的第三篇文章,分析了如何設計聚合。聚合這個概念看似很簡單,實際上有很多因素導緻我們建立不正确的聚合模型。本文對這些問題逐一進行剖析。
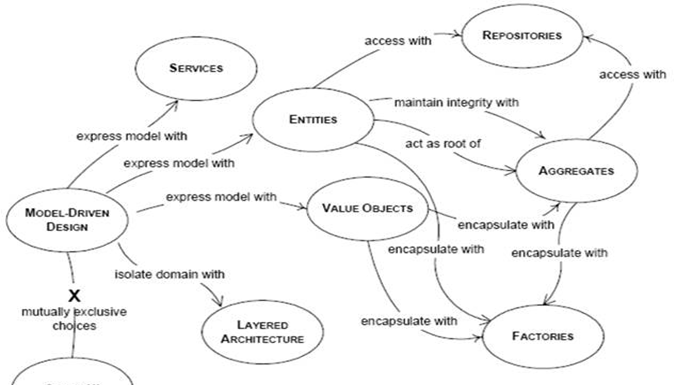
聚合這個概念看似很簡單,實際上有很多因素導緻我們建立不正确的聚合模型。一方面,我們可能為了使用上的一時便利将聚合設計得很大。另一方面,因為邊界、職責的模糊性将一些重要的方法放在了其他地方進而導緻業務規則的洩露,沒有達到聚合對業務邊界的保護目的。在開始聚合之前,我們要區厘清楚“實體Entity”“值對象Value Obj”的差別,并且要重視“值對象Value Obj”的真正價值。
(圖檔來源于網絡)
一、實體(Entity) OR 值對象(Value Obj)
領域驅動設計裡面有兩個重要的概念,“實體Entity”“值對象Value Obj”。很多人講解時候會舉類似這樣的例子:使用者在某電商平台下單,其收貨位址為“XX市YY街道ZZ園區”。現實場景中多個使用者的收貨位址有可能是同一個,是以會把位址模組化成Value Obj,借此把Value Obj簡單解釋成“描述性的、不變的東西,比如位址”。這樣的解釋似乎也能說明問題,但是我覺得還沒有深入到本質去探究、容易忽略Value Obj的真正要義。
1、實體Entity
一些對象不僅僅是由它們的屬性定義組成的,我們更關心其延續生命周期内經曆的不同狀态階段,這是我們業務域的核心。我們出于追蹤的目的,需要給每一個實體設定唯一辨別。通常的,我們也會将其持久化到資料庫中,實體即表裡的一行記錄。是以,當我們需要考慮一個對象的個性特征,或者需要區分不同的對象時,我們引入實體這個領域概念。一個實體是一個唯一的東西,并且可以在相當長的一段時間内持續地變化。我們可以對實體做多次修改,故一個實體對象可能和它先前的狀态大不相同。但是,由于它們擁有相同的身份辨別(identity),它們依然是同一個實體。對于某電商平台而言,一個個的使用者就是實體,我們要對他們加以差別并且持續的關注他們的行為。
實體有特殊的模組化和設計思路。它們具有生命周期,這期間它們的形式和内容可能發生根本改變,但必須保持一種内在的連續性,即全局唯一的id。它們的類定義、職責、屬性和關聯必須由其辨別來決定,而不依賴于其所具有的屬性。即使對于那些不發生根本變化或者生命周期不太複雜的實體,也可以在語義上把它們作為實體來對待,這樣可以得到更清晰的模型和更健壯的實作。當然,軟體系統中的大多數實體可以是任何事物,隻要滿足兩個條件即可,一是它在整個生命周期中具有連續性,二是它的差別并不是由那些對使用者非常重要的屬性決定的。根據業務場景的不同,實體可以是一個人、一座城市、一輛汽車、一張彩票或一次銀行交易。
跟蹤實體的辨別是非常重要的,但為其他所有對象也加上辨別會影響系統性能并增加分析工作,而且會使模型變得混亂,因為所有對象看起來都是相同的。軟體設計要時刻與複雜性做鬥争,我們必須差別對待問題,僅在真正需要的地方進行特殊處理。比如在上面的例子中,我們把收貨位址“XX市YY街道ZZ園區”模組化成具有唯一辨別的實體,那麼三個使用者就會建立三個位址,這對于系統來說完全沒有必要甚至還會導緻性能或者資料一緻性問題。
2、值對象Value Obj
當我們隻關心一個模型元素的屬性時,應把它歸類為值對象。我們應該使這個模型元素能夠表示出其屬性的意義,并為它提供相關功能。值對象應該是不可變的;不要為它配置設定任何辨別,而且不要把它設計成像實體那麼複雜。即描述了領域中的一些屬性,比如使用者的名字、聯系方式。當然也會存在一些複雜的描述資訊,其本身可能就是一個對象,甚至是另一個實體概念。
在前述的電商例子中位址是一個值對象。但在國家的郵政系統中,國家可能組織為一個由省、城市、郵政區、街區以及最終的個人位址組成的層次結構。這些位址對象可以從它們在層次結構中的父對象擷取郵政編碼,而且如果郵政服務決定重新劃分郵政區,那麼所有位址都将随之改變。在這裡位址是一個實體。
在電力營運公司的軟體中,一個位址對應于公司線路和服務的一個目的地。如果幾個室友各自打電話申請電力服務,公司需要知道他們其實是住在同一個地方,因為我們真實服務的是使用者所在地方的電力資源,在這種情況下,我們會認為位址是一個實體。但是随着思考的深入,我們發現可以換種方式,抽象出一個電力服務模型并與位址關聯起來。通過這樣的設計以後,我們發現真正的實體是電力服務,位址不過是一個具有描述性的值對象而已。
在房屋設計軟體中,可以把每種窗戶樣式視為一個對象。我們可以将“窗戶樣式”連同它的高度、寬度以及修改群組合這些屬性的規則一起放到“窗戶”對象中。這些窗戶就是由其他值對象組成的複雜值對象,比如圓形天窗、1m規格平開窗、狹長的哥特式客廳窗戶等等。對于“牆”對象而言,所關聯的“窗戶”就是一個值對象,因為僅僅起到描述的作用,“牆”不會去關心這個窗子昨天是什麼樣,以至于當我們覺得這個窗戶不合适的時候直接用另外一個窗戶替換即可。
歸根結底,我們使用這個窗戶對象來描述牆的窗戶屬性。但是在該房屋設計軟體的素材系統中,它的主要職責就是管理窗戶這一類的附屬元件,那麼對它而言窗戶就是一個鮮活的實體。從這個例子中我們可以看出,所屬業務域很重要,這也就是我們之前所講述的上下文,即同一對象在不同上下文中是不一樣的。
當你決定一個領域概念是否是一個值對象時,你需要考慮它是否擁有以下特征:
- 它度量或者描述了領域中的某個概念屬性;
當你的模型中的确存在一個值對象時,不管你是否意識到,它都不應該成為你領域中的一件東西,而隻是用于度量或描述領域中某件東西的一個概念。一個人擁有年齡,這裡的年齡并不是一個實在的東西,而隻是作為你出生了多少年的一種度量。一個人擁有名字,同樣這裡的名字也不是一個實在的東西,而是描述了如何稱呼這個人。 - 它可以作為不變量;
值對象可能會被共享,是以具有不變性,即調用方不能對其執行set操作。 - 它将不同的相關的屬性組合成一個概念整體;
一個值對象可以隻處理單個屬性,也可以處理一組相關聯的屬性。在這組相關聯的屬性中,每一個屬性都是整體屬性所不可或缺的組成部分,這和簡單地将一組屬性組裝在對象中是不同的。如果一組屬性聯合起來并不能表達一個整體上的概念,那麼這種聯合并無多大用處。比如貨币與機關、币種應該是一個整體概念,否則很難明白12到底代表什麼意思?12美分還是12元RMB。 - 當度量和描述改變時,可以用另一個值對象予以替換;
比如随着時間推移,使用者年齡從21歲變成22歲,即22替換21。
二、聚合(Aggregate)
每個對象都有生命周期,對象自建立後可能會經曆各種不同的狀态,要麼被暫存、要麼删除直至最終消亡。當然,很多對象是簡單的臨時對象,僅通過調用構造函數來建立,用來做一些計算,而後由垃圾收集器回收。這類對象沒必要搞得那麼複雜。但有些對象具有更長的生命周期,其中一部分時間不是在活動記憶體中度過的。它們與其他對象具有複雜的互相依賴性。它們會經曆一些狀态變化,在變化時要遵守一些固定規則。管理這些對象時面臨諸多挑戰,稍有不慎就會把自己帶入一個大泥坑。
減少設計中的關聯有助于簡化對象之間的周遊,并在某種程度上限制關系的急劇增多。但大多數業務領域中的對象都具有十分複雜的聯系,以至于最終會形成很長、很深的對象引用路徑,我們不得不在這個路徑上追蹤對象。在某種程度上,這種混亂狀态反映了現實世界,因為現實世界中就很少有清晰的邊界。但這卻是軟體設計中的一個重要問題,幸而我們可以借助“聚合”來應對。

首先,我們需要用一個抽象來封裝模型中的引用。聚合就是一組相關對象的集合,我們把它作為資料修改的單元。每個都有一個根(root)和一個邊界(boundary)。邊界定義了聚合内部都有什麼。根則是聚合所包含的一個特定實體。對聚合而言,外部對象隻可以引用根,而邊界内部的對象之間則可以互相引用。除根以外的其他實體都有本地辨別,但這些辨別隻在聚合内部才需要加以差別,因為外部對象除了根之外看不到其他對象。
三、一些關于聚合的實踐
關于聚合、實體的概念已經描述清楚了,下面我打算借助一個例子來繼續深入探讨聚合的相關知識。
案例:汽車模型設計
限制:首先一輛汽車在車輛登記機構歸屬于唯一一個人或者企業主體(實際上企業也具有法人,是以即使是企業主體也可以找到對應的歸屬人);其次,正如大家所常見的,我們探讨是目前技術所能實作的、且普遍流行的車輛結構,一輛車具有4個輪子、一個引擎;
1、業務邊界
Car、Customer很自然的按照實體進行對待;發動機作為一個産品傳遞時候有唯一序列号,考慮到其可能的特性我們姑且也視其為實體;因為有4個輪子,可能需要進行區分是以也被視為實體。綜上可知,我們先把4個對象都當做實體。因為是模組化汽車相關業務,是以我們把Car視為根。至此,我們得到了一個強大的聚合,包含車輪、引擎以及所屬人資訊。
public class Car {
private Customer customer;
/**
* WheelPositionEnum枚舉辨別輪子狀态
* FR FL BR BL依次辨別前右、前左、後右、後左輪
* 在聚合内部保持獨立
*/
private Map<String, Wheel> wheels;
private Engine engine;
//其他屬性暫略
} 當我們分析出聚合以後,事情還沒有結束。聚合表達的是業務,那麼業務的規則、限制如何來保證呢?
- 根ENTITY即Car具有全局辨別,它最終負責檢查固定規則。
- 根ENTITY具有全局辨別。邊界内的ENTITY具有本地辨別,這些辨別隻在從聚合内部才是唯一的,比如上面的車輪集合。
- 删除操作必須一次删除AGGREGATE邊界之内的所有對象。(利用垃圾收集機制,這很容易做到。由于除根以外的其他對象都沒有外部引用,是以删除了根以後,其他對象均會被回收。)我們可以想象,當汽車不存在的時候,我們更不會去關心其車輪情況,“皮之不存毛将焉附”。
- AGGREGATE外部的對象不能引用除根ENTITY之外的任何内部對象。即我們不可能先擷取到車輪對象,然後去反向擷取Car對象,這樣就等于建立了Car、Wheel的雙向關聯并且對調用方而言會很困惑。我什麼情況下可以直接使用Wheel、何時可以直接使用Car,這是系統走向腐敗的第一步。
現在我們看下代碼實作,Car具有全局唯一id用以區分不同對象;且負責限制的檢查,比如是否具有4個輪子、是否有一個引擎,否則不能正常使用。也許我們日常開發中的做法是調用方擷取到一個Car執行個體以後,去校驗這些規則是否滿足,這樣做的問題就是業務規則的洩露。
public Car getCar(Long id) {
Car car = carRepostory.ofId(id);
if (car.getEngine() == null ||
car.getWheels().keySet().size() != SPECIFIC_WHEEL_SIZE) {
throw new CarStatusException(id);
}
return car;
}
/**
*上述代碼存在的問題,畢竟現實中有報廢、廢棄的Car
*1.命名getCar實際上進行了狀态檢查,命名與實際語義不符;
*2.Car的狀态限制洩露到調用方;
*3.雖然面向流程寫出的是可以工作的代碼,但我們更推薦
* 面向領域的封裝代碼;
**/
public Car getWorkableCar(Long id) {
Car car = carRepostory.ofId(id);
//業務限制由Car自己承擔
if (!car.workable()) {
throw new CarStatusException(id);
}
return car;
} 2、警惕性能問題
在具有複雜關聯的模型中,要保證對象更改的一緻性是很困難的。不僅互不關聯的對象需要遵守一些固定規則,而且緊密關聯的各組對象也要遵守一些固定規則。然而,過于謹慎的鎖定機制又會導緻多個使用者之間毫無意義地互相幹擾,進而使系統不可用。引用自《領域驅動設計》P82。
在上面的模型中,Engine被視為Car聚合内的一個實體,這就意味着要對Engine做修改必須先擁有Car所有權。現在我們遇到一個需求:發動機制造商突然發現其傳遞的産品存有安全隐患,需要跟蹤運作效果以及通過網絡進行更新檔安裝。
(1)如何解決争用問題?
Car對象自身對Engine存有一些寫的邏輯,比如更新發動機的使用情況;發動機制造商也要對Engine做一些更新。這裡面可能有一些業務限制,比如發動機更新期間不提供對外服務,這裡面為了規避并發可能要進行一些加鎖操作,這就會導緻性能問題。
(2)如何解決效率問題?
制造商不能直接擷取到Engine對象,因為對外部而言擁有Car執行個體才能有管道去獲得Engine執行個體。這就導緻了效率問題,因為制造商不得已隻能去周遊所有Car實體。
是以我們考慮把發動機作為一個單獨的業務域,Car聚合裡面隻需要記錄EngineId。無論是發動機的運作資料或者發動機的監控、更新等操作,都由發動機自己負責。同時因為Car聚合記錄了EngineId,必要的情況下我們可以友善的從EngineRepository中獲得Engine對象,這也算是做到了懶加載。可以想象,系統中假如存在千萬級别的Car執行個體,按照最初的方案就會有千萬級别的Engine對象,但是我相信并不是每一次對Car執行個體的調用都需要擷取其Engine資訊,這就造成了大量的記憶體消耗。相對于最初的方案,我們的聚合或更小,也更靈活。
public class Car {
private Customer customer;
private Map<String, Wheel> wheels;
//我們構造單獨的Engine聚合。
//此處隻記錄EngineId,需要時候再去擷取執行個體。懶加載。
//從實體轉為值對象
private String engineId;
//......
} 在聚合中,如果你認為有些被包含的部分應該模組化成一個實體,此時你該怎麼辦呢?首先,思考一下,這個部分是否會随着時間而改變,或者該部分是否能被全部替換。如果可以全部替換,那麼請将其模組化成值對象,而非實體。有時,模組化成實體也是有必要的。但是很多情況下,許多模組化成實體的概念都可以重構成值對象。聚合的内部模組化成值對象有很多好處的。根據你所選用的持久化機制,值對象可以随着根實體而序列化,比如我們可以把EngineId和Car一起存放;而實體則需要單獨的存儲區域予以跟蹤,此外實體還會帶來某些不必要的操作,比如我們需要對多張表進行聯合查詢。但是對單張表進行讀取要快得多,而使用值對象也更加友善與安全。再者由于值對象是不變的,測試起來也相對簡單。
在實際項目中,即使沒有并發鎖、沒有大事務,我們依然還會遇到寫操作性能問題。Car被廢棄處理以後,我們可能不僅僅是更新對應資料庫記錄資訊。我們還需要在車輛登記機構進行銷戶操作;對應的車輪、發動機相關的資料記錄如何處理等等。如果你指望一個方法體裡面處理完這些邏輯,我敢保證你的代碼響應時間會非常之久,甚至導緻“汽車報廢”業務不可用。是以我們要去思考這個過程,哪些是核心邏輯,哪些允許一定的時延,對複雜的邏輯進行異步處理。比如:我們釋出CarAbandonedEvent進而由相應的handler去處理後續的業務規則。
3、值對象-無副作用
值對象的方法應該被設計成一個無副作用函數,即隻用于生成輸出而不會修改對象的狀态。對于不變的值對象而言,所有的方法都必須是無作用的函數,因為它們不能破壞值對象的屬性值才能安全的被共享。我們要意識到值對象絕不僅僅是一個屬性容器,其真正的強大特性“無副作用函數”。比如上面的窗戶對象,當其被執行個體化出來以後各個屬性就不能被肆意修改了,我們通用的做法是在構造方法裡面進行指派或者基于工廠方法獲得,總之千萬拒絕提供public的set方法,因為你不知道哪個小夥伴在你不知情的情況setBomb。當管理窗戶的附屬資源系統進行更新,可能導緻某低版本的窗戶對象不可用時候隻需要對系統發送一個WindowsUpgradedEvent,進而由各個業務方去檢查是否替換使用新的窗戶對象。
一個值對象允許對傳入的實體對象進行修改嗎?如果值對象中的确有方法會修改實體對象,那麼該方法還是無副作用的嗎?該方法容易測試嗎?是以,如果一個值對象方法将一個實體對象作為參數時,最好的方式是,讓實體對象使用該方法的傳回結果來修改其自身的狀态。
比如某車輛養護機構提供噴繪功能,使用者基于三原色自由組合自己喜愛的顔料。我們定義了Paint對象,其顔色由red、yellow、blue構成。在這裡“顔色”是一個非常重要的概念。你可以想象某種網紅流行顔色必然會被大家追捧,在這段期間頻繁地被系統建立出來。通過前面的論述,我們試着顯示定義PigmentColor專門用于三原色的管理。其本身也會作為一個值對象被Paint使用。
public class Paint {
private PigmentColor pigmentColor;
private Double volume;
//一定量的顔料A可以與其他顔料混合配比使用,那麼我們可能定義一個mixedWith方法
//還有一個疑問就是混合後的Paint對象到底是不是原來的?
public void mixedWith(Paint anotherPaint){
//1.add volume
//2.顔料混合
//3.then, but...who am I
}
} 把PigmentColor分離出來之後,确實比先前表達了更多資訊,但混合計算的邏輯該怎麼實作也是一個頭疼的事情。當把顔色資料移出來後,與這些資料有關的行為也應該一起移出來。但是在做這件事之前,要注意PigmentColor是一個值對象,是以應該是不可變的。當我們混合調配時,Paint對象本身被改變了,它是一個具有生命周期的實體。相反,表示基個色調(棕色、黑色、白色)的PigmentColor則一直表示那種顔色。Paint的結果是産生一個新的PigmentColor對象,用于表示新的顔色。
public class PigmentColor {
//mixedwith作為值對象的無副作用方法,傳回一個新的對象由調用方決定是否使用。
public PigmentColor mixedwith(PigmentColor otherPigment, Double ratio) {
//混合的邏輯
return 新的PigmentColor對象;
}
}
/**
*
* 如果一個操作把邏輯或計算與狀态改變混合在一起,那麼我們
* 就應該把這個操作重構為兩個獨立的操作。
* 邏輯計算可以視為指令,我們對于結果的擷取視為查詢。這也
* 符合指令查詢分離的原則。
*/
public class Paint {
public void mixedwith(Paint other) {
this.volume += other.getVolume();
Double ratio = other.getVolume() / this.volume;
//用新傳回的顔料對象替換目前的顔料對象,
//通過可以替換的值對象維護Paint實體的完整性。
this.pigmentColor =
this.pigmentColor.mixedwith(other.getPigmentColor(), ratio);
}
} 4、聚合的構造與儲存
當建立一個對象或建立整個AGGREGATE時,如果建立工作很複雜,或者暴露了過多的内部結構,則可以使用FACTORY進行封裝。就好比我們不可能讓調用方來構造我們的Car聚合,因為調用方并不知道我們WheelPositionEnum與Wheel的映射關系,不知道如何去構造Wheel資訊。複雜的對象建立是領域層的職責,無論是實體、值對象,其建立過程本身就是一個主要操作,有時候被建立的對象自身并不适合承擔複雜的裝配操作。将這些職責混在一起可能産生難以了解的拙劣設計,好比我們的Car必然不是自己生産出來的,而是産自于某個“工廠”。
我們應該将建立複雜對象的執行個體和AGGREGATE的職責轉移給單獨的對象,提供一個封裝所有複雜裝配操作的接口。在建立AGGREGATE時要把它作為一個整體,并確定它滿足固定規則。我們可以視其為“工廠FACTORY”。FACTORY有很多種設計方式,包括FACTORY METHOD(工廠方法)、ABSTRACT FACTORY(抽象工廠)和BUILDER(建構器)。
這裡要強調的是,BUILDER(建構器)也是我們常用的一種工廠方法。我們可以對Car聚合設計一個工廠方法buildWheels,其接受必須要的參數進而轉換為滿足業務規則的映射關系。這裡面更重要的是業務限制的檢查,每個建立方法都是原子的,而且要保證被建立對象或AGGREGATE的所有固定規則。在生成ENTITY時,這意味着建立滿足所有固定規則的整個AGGREGATE,但在建立完成後可以向聚合添加可選元素。在建立不變的VALUE OBJECT時,這意味着所有屬性必須被初始化為正确的最終狀态。如果FACTORY通過其接口收到了一個建立對象的請求,而它又無法正确地建立出這個對象,那麼它應該抛出一個異常,或者采用其他機制,以確定不會傳回錯誤的值。
很多場景中,聚合被建立出來以後其生命周期會持續一段時間。我們在稍後的代碼裡面仍舊需要使用,考慮到複雜聚合的生成過程比較繁瑣,是以我們有必要找到一個地方将這些還需要使用的聚合“暫存”起來。否則我們就需要時刻把這些聚合當做參數進行傳遞。為每種需要全局通路的對象類型建立一個“容器”即REPOSITORY,并通過一個衆所周知的全局接口來提供通路。提供添加和删除對象的方法,用這些方法來封裝在資料存儲中實際插入或删除資料的操作。提供根據具體條件來挑選對象的方法,并傳回屬性值滿足查詢條件的對象或對象集合,進而将實際的存儲和查詢技術封裝起來。隻為那些确實需要直接通路的AGGREGATE根提供REPOSITORY。讓客戶始終聚焦于模型,而将所有對象的存儲和通路操作交給REPOSITORY來完成。
5、展示聚合
首先我們應該明确DDD裡面有清晰嚴格的“層”概念,通常情況下展示層需要的資訊會分散在多個聚合裡面,但是每個聚合裡面也有一些本次展現所不需要的資訊;而每一個聚合可能又是有幾個資料庫實體記錄構成的。這就導緻了一個展示對象涉及了多次資料庫查詢且存在多次資料對象的轉換。這也許會成為你的吐槽點。
但可能有些讀者會選擇直接在資料結構中使用業務實體對象(即在展示層、資料庫設計時候也使用領域層聚合)。畢竟,業務實體與請求/響應模型之間有很多相同的資料。但請一定不要這樣做!這兩個對象存在的意義是非常不一樣的。随着時間的推移,這兩個對象會以不同的原因、不同的速率發生變更。是以将它們以任何方式整合在一起都是對共同閉包原則(CCP)和單一職責原則(SRP)的違反。總有一天,當你想要重新設計底層存儲時候會導緻展示層的問題;或者迫于展示層的需求去修改底層的表結構。
針對一開始的吐槽,我們可以借助懶加載去避免不必要的查詢以及轉換;還可以把一些常用的資料緩存起來。但如果使用redis一類的記憶體資料庫時候,要考慮對象的序列化消耗。因為如果把一個層級較深、比較複雜的大聚合緩存在redis中,在高頻讀取的情況下序列化也會令你抓狂。在這樣的情況下,我們可能需要重新設計緩存結構,盡可能接近于viewObj.setAttribute(redis.getXXX())。很大程度上,對象之間的轉換可能不能完全避免,是以我們要綜合考慮以上幾種因素去權衡實踐。
6、不要抛棄領域服務
很多人認為DDD中的聚合就是在與貧血模型做抗争,是以在領域層是不能出現“service”的,這等于是破壞了聚合的操作性。但有些重要的領域操作無法放到實體或值對象中,這當中有些操作從本質上講是一些活動或動作,而不是對象。比如我們的身份認證、支付轉賬業務,我們很難去抽象一個金融對象去協調轉賬、收付款等業務邏輯;有時候我們也不太可能讓對象自己執行auth邏輯。因為這些操作從概念上來講不屬于任何業務對象,是以我們考慮将其實作成一個service,然後注入到業務領域或者說是業務域委托這些service去實作某些功能。
//AuthenticationService注冊到了DomainRegistry
UserDescriptor userDescriptor = DomainRegistry
.authenticationService()
.authenticate(userId, password); 以上方式是簡單的,也是優雅的。用戶端隻需
要擷取到一個無狀态的AuthenticationService,然後調用它的authenticate()方法即可。這種方式将所有的認證細節放在領域服務中,而不是應用服務。在需要的情況下,領域服務 可以使用在何領域對象來完成操作,包括對密碼的加密過程。用戶端不需要知道任何認證細節。此時,通用語言也得到了滿足,因為我們将所有的領域術語都放在了身份管理這個領域中,而不是一部分放在領域模型中,另一部分 放在用戶端中。
AuthenticationService和那些與使用者身份相關的業務定義在相同的package中,但對于該接口的實作類,我們可以選擇性地将其存放在不同的地方。如果你正使用依賴倒置原則或六邊形架構,那麼你可能會将這個多少有些技術性的實作類放置在領域模型之外的某個設施層。
那麼我們來總結一下,以下幾種情況我們可以使用領域服務來實作:
- 執行一個顯著的業務操作過程;
- 對領域對象進行轉換;
- 以多個領域對象作為輸入進行計算,結果産生一個值對象;
7、再談命名
類以及函數的命名一直以來都是令人困惑的話題,根因在于它說起來很簡單,但要做好确實太難了。試想一下如果開發人員為了使用一個元件而必須要去研究它的實作,那麼就失去了封裝的價值。當某個人開發的對象或操作被别人使用時,如果使用這個元件的新的開發者不得不根據其實作來推測其用途,那麼他推測出來的可能并不是那個操作或類的主要用途。如果這不是那個元件的用途,雖然代碼暫時可以工作,但設計的概念基礎已經被誤用了,兩位開發人員的意圖也是背道而馳。當我們把概念顯式地模組化為類或方法時,為了真正從中擷取價值,必須為這些程式元素賦予一個能夠反映出其概念的名字。類和方法的名稱為開發人員之間的溝通創造了很好的機會,也能夠改善系統的抽象。
是以在命名類和操作時要描述它們的效果和目的,而不要表露它們是通過何種方式達到目的的。這樣可以使客戶開發人員不必去了解内部細節。在建立一個行為之前先為它編寫一個測試,這樣可以促使你站在客戶開發人員的角度上來思考它。測試驅動的另一個價值就是要求我們寫出易于(測試)使用的代碼。試想一下,我們自己編寫測試都很困難的時候,别人又如何明白呢?
通常的所有複雜的機制都應該封裝到抽象接口的後面, 接口隻表明意圖,而不表明方式。在領域的公共接口中,可以把關系和規則表述出來,但不要說明規則是如何實施的;可以把事件和動作描述出來,但不要描述它們是如何執行的。
8、領域核心能力
當我們對現實領域進行思考時候,很容易被“表象”所迷惑。比如我們的Car聚合内部會有一個導航服務,一般情況我們可能需要按照最短路徑導航、躲避擁堵、高速優先等情況。通過前面的學習,我們抽象一個“導航”服務并将其注入或者注冊到Car聚合。
随着導航要求的多樣化,不可避免的該類會變得臃腫繼而難以維護。是以我們借助政策模式,抽象一個導航政策,一切問題都變得更加清晰。
如上圖所示設計,我們得到了清晰明确的導航模型以及一個被明确提煉出來的導航政策。無論我們導航需求如何變化,我們隻需要去增加實作類即可,這就是我們架構原則所提倡的對擴充開放。這雖然是一個很小的例子,但是其背後的意義重大,讓我們學會區分什麼是行為、什麼是政策。因為行為是固定的,政策是變化的。當我們将二者區分以後,就能更加聚焦于領域的核心行為能力。
四、聚合與六邊形架構
在之前的系列文章中,我多次提到了六邊形架構。但更多的是理念上的解釋,現在講解了聚合以後我們就來看看六邊形架構的代碼風格是什麼樣的,其端口到底為何物。還是參照之前的做法,在一個DDD沒有完全普及的項目中,我們依然提供一個CarFacade供外部調用,以免花費很長時間去和他們争論到底該不該模組化一個充血的Car對象。
//通過RPC調用得到Car聚合資訊,進而轉換成前端展示所需要的ViewObject
CarData carData = carFacade.OfId(carId);
CarVO carVO = CarVOFactory.build(carData.getValue()); 通常應用服務被設計成了具有輸入和輸出的API,而傳入資料轉換器的目的即在于為用戶端生成特定的輸出類型。在六邊形架構中我們可能會使得服務傳回void類型,資料隐式的在端口流轉。通過這一點,我們可以看出六邊形架構更強調資料流轉而不像傳統開發方式那樣注重資料的傳回或加工。
public class CarFacadeImpl {
public void OfId(Long carId){
//領域層邏輯
Car car = this.carRepository.OfId(carId);
//應用層邏輯
//這裡的輸出端口是一個位于位于應用程式的邊緣特殊的端口;
//在使用Spring時,該端口類可以被注入到應用服務中;
//在本例中其職責是把Car聚合轉換成前端展示所需要的ViewObject;
//如果我們使用SpringMVC一類的架構,該端口還負責把資料傳回給HttpResponse;
this.carHttpOutputPort().write(car);
}
} 當然我們可能會有多個輸出端口,而各個端口的隔離實作又避免了邏輯的污染,為将來任意擴充端口場景提供了可能性。在write()方法執行後,每一個注冊的讀取器都會将端口的輸出作為自己的輸入。這裡最大的問題就是,不了解六邊形架構的人會抱怨“你的getXXX方法竟然沒有傳回值”。是以我們在方法命名時候盡可能避免使用get字樣,通常我會取而代之find/load,因為查找/裝載并不隐含需要傳回結果的意思。無論如何我們都要明白,任何一種架構都同時存在正面的和負面的影響。
五、演進的聚合
提到“重構”,我們頭腦中就會出現這樣一幅場景:幾位開發人員坐在鍵盤前面,發現一些代碼可以改進,然後立即動手修改代碼(當然還要用單元測試來驗證結果)。當然這個過程應該一直進行下去,但它并不是重構過程的全部。與傳統重構觀點不同的是,即使在代碼看上去很整潔的時候也可能需要重構,原因是模型是否與真實的業務一緻,或者現有模型導緻新需求不能被自然的實作完成。重構的原因也可能來自學習:當開發人員通過學習獲得了更深刻的了解,進而發現了一個得到更清晰或更有用的模型。綜合起來以下幾點的出現就說明你應該重新審視你的聚合了,當然我們重構也好、演進也罷,也還是要基于實際項目的情況。
- 設計沒有表達出團隊對領域的最新了解;
- 重要的概念被隐藏在設計中了(而且你已經發現了把它們呈現出來的方法);
- 發現了一個能令某個重要的設計部分變得更靈活的機會;
最後還是延續前面文章的一貫風格,本文講述了很多有關聚合的細節,即使在非DDD的項目中,這些有效實踐依然大有裨益。我們希望設計的聚合具有柔性特征,但這往往很難。能夠清楚地表明它的意圖;使人們很容易看出代碼的運作效果,是以也很容易預計修改代碼的結果。柔性設計主要通過減少依賴性和副作用來減輕人們的思考負擔。這樣的設計是以深層次的領域模型為基礎的,在模型中,隻有那些對使用者最重要的部分才具有較細的粒度。在這樣的模型中,那些經常需要修改的地方能夠保持很高的靈活性,而其他地方則相對比較簡單。這也就是我一再強調的“行為”“政策”的差別。當我們這樣去思考問題以後,編碼以及設計思路會有很大變化,從原來那樣的流程代碼中脫離出來,進而站在一個更高的抽象層次上去實作系統。
參考文獻:
- 《領域驅動設計:軟體核心複雜性應對之道》
- 《實作領域驅動設計》