MySQL通常在人們眼中就是一個低端、開源、大衆化的資料庫産品,它的穩定性和可用性一直被人們所置疑,被認為難登大雅之堂,隻适用于網際網路應用,難于應用到可用性高的場景中,比如金融、證券等行業。然而時代的變化太快,MySQL也不能再以過去的眼光來看,從MySQL金融版的誕生開始,它已經不再是那個扶不起的阿鬥,它已經脫胎換骨,以一個嶄新的形象出現在資料庫的高端産品中。
這一切真的難以置信,在開源資料庫産品中,MySQL從來都是一枝獨秀,但在表面風光的同時,卻是DBA和資深使用者的滿心苦澀。由于硬體、網絡的可用性還難以達到理想的要求,無論出現任何故障,資料庫系統都必須保證其可用性。對于MySQL來說,大家所熟知的主備叢集是最常見的解決方案。由于MySQL的架構設計原因,主備叢集的解決方案雖然不完美,但也是其最好的解決方案了。但其中存在的可用性隐患,卻是DBA和資深使用者的内心無奈。
MySQL的主備叢集方案,對于大多數應用系統可以滿足基本的可用性要求了,如果要求更高的話,隻能去選擇商業資料庫,而商業資料庫的成本卻又難以承受。到底存在什麼問題呢?
熟悉MySQL的都知道,MySQL是采用binlog來搭建主備叢集的,主機上的事務送出時,通過兩階段事務将binlog寫入到磁盤,然後再将其發送給備機,備機收到後重放日志,以完成事務與主機的同步。如下圖所示
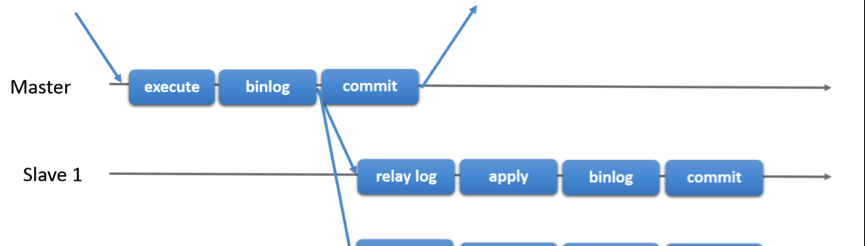
顯而易見,主備之間會存在一些延遲,當主機已經将事務送出後,備機也許還沒有收到這條事務的binlog,此時在備機上這條事務其實的缺失的。為了盡可能降低主備延遲,後來MySQL又設計了Semi-Sync,如下圖所示:

在Master送出之前,必須保證備機已經收到binlog,并記錄到本機的relay log中。這樣在主機上送出的事務就一定會在備機上送出,隻是可能會有些許延遲,如果應用容忍這些延遲的話,那麼一切就很完美了。
但這個看起來很完美的解決方案,在真正故障發生時,卻不一定那麼完美,隻是隐藏的很深。
即使使用semi-sync的同步解決方案,當主機發生故障後,系統需要切換到備機,将備機變成主機來繼續提供資料庫服務。如果原來的主機故障可以修複,可以做為備機,這一切看起來沒有什麼問題。但如果對MySQL有更深入研究的話,就會發現其實還有隐藏的更深的隐患。
MySQL的事務處理采用兩階段送出機制,以保證事務的可靠性。當事務準備送出時,首先将事務寫入binlog,然後再在存儲引擎層送出事務,比如InnoDB存儲引擎。正常情況下一切都沒有問題,但當系統意外down機,重新啟動時,MySQL首先會進入故障恢複階段,讀取redo日志,做事務恢複,但可能會發現部分事務并沒有送出,那麼這部分事務是應該復原嗎?MySQL的實作方法是先将這部分事務挂起,暫時既不送出也不復原,然後讀取binlog日志,如果在binlog中發現有此事務的記錄,就将事務送出,若未發現此事務的記錄,就将事務復原。
現在我們再回過頭來看之前的故障切換問題。若主機上有事務準備送出,然後事務記入binlog,但在傳送給備機之前主機崩潰了,那麼備機是沒有這些事務的,然後備機就切換成了主機。當原主機重新啟動後,通過之前所述的故障恢複過程,這些事務已經記錄到binlog,那麼應該送出。問題出現了,新的主機和即将成為備機的原主機資料不一緻了。有些事務在新主機上沒有,但在原主機上已經送出。
舉個栗子,使用者在原主機上插入10條資料,但在新主機上沒有發現,是以重新插入,但在原主機成為備機後,卻又接收到從主機傳來的插入10條資料的binlog,此時何去何從?該不該插入呢?
從理論上來講,原主機上的事務雖然已經記錄到binlog,但其實尚未在存儲引擎層送出,也沒有傳回給應用系統事務送出成功的資訊,使用者是不知道此條事務成功還是失敗,當然多數情況下可能認為此條事務是執行失敗的。如果要确切的知道這條事務的狀态,必須在資料庫中查詢一下,是否已執行成功。這在任何資料庫系統中都是這樣的。比如你執行一個事務,資料庫已經執行成功,日志也已經記錄,但在傳回資料時,網絡出現故障,應用系統是無法得知此事務是成功還是失敗,但資料庫系統中其實是已經送出成功的。
為了解決MySQL更高可用性的問題,我們重新設計了MySQL的複制解決方案,汲取最新分布式理論成果,采用多副本投票選主及分布式故障恢複的機制來提高MySQL的可用性,進而達到RPO為0的目标,重磅釋出了MySQL金融版。同時3節點可以容忍1個節點故障,5節點可以容忍2個節點故障。相比傳統的主備叢集為什麼會有這麼神奇的改變呢,下面我們對新的架構做詳細的闡述,尤其在改進可用性方面做的創新。
新的金融版架構要求至少有3個節點,可以由3個及3個以上節點組成高可用叢集。為簡單起見,我們以3個節點為例,下圖是一個簡單的3節點金融版架構示意圖:
其中Leader節點等同于傳統主備叢集中的master節點,而follower節點等同于slave節點。在MySQL金融版叢集架構中,系統會自動選舉一個節點做為主節點,而其它2個節點自動成為備節點。主節點可以接受客戶的讀寫事務,而備節點隻能接受客戶的讀事務,讀寫事務的分離可以通過proxy來自動完成。
當事務在主節點即leader節點上準備送出時,必須先寫到本機的binlog中,并且傳送給2個follower節點,當至少一個follower節點回複收到後,leader節點方可在存儲引擎層送出事務,然後傳回給使用者事務執行成功。這樣就保證當事務送出後,肯定在其中一個follower上已經接收到此事務的binlog,可以重放binlog,實作與leader的事務同步。
從這裡來看,貌似和主備叢集沒有什麼太大差別,其實差別主要在故障發生後的處理過程中。前文已經分析過主備叢集在故障切換時可能存在的問題,那麼對于MySQL金融版來說,首先就要解決故障切換後可能存在的資料不一緻問題。
當3節點叢集中有1個節點故障後,這裡與2節點的主備叢集也有很大差別,2節點叢集是不可能自己檢測出來某些故障的,比如主備間的網絡中斷,它無法正确識别出是網絡中斷,還是主機down機,自然也無法做出正确的決擇。是以2節點主備叢集的切換都依賴于第3方管理監控軟體來識别故障和發起主備切換。與此不同,3節點是可以自己正确識别故障,并進行主動切換,原因在于,故障需要多數派确認,然後再進行相應的切換操作。
當leader發生故障後,其它2個節點很快就能發現leader失去聯系,然後會自發的進入選舉leader階段,與正常主備切換不同的是,3節點的主備切換多了一個leader選舉過程,因為有2個備庫,是以必須就哪個備庫切為主庫達成一緻,防止多主的出現。
新主選擇的最重要的條件之一就是其擁有更多的binlog,系統總是選擇擁有更多binlog的備庫做為新的主庫,這也防止新的主庫上會有缺失的事務。
如果原主上有更多的binlog該怎麼辦?這也是之前分析的主備叢集難以解決的問題。其實在3節點叢集中,這個問題也同樣可能發生,隻是3節點很好的解決了這個問題。如前所述,當主庫準備送出事務之後,先将事務寫入本機binlog,然後在将其傳送給備庫之前,此時主庫故障或網絡故障,主庫上就會有更多的binlog。
我們注意到,此時這些事務并未在存儲引擎層送出,也尚未傳回給客戶事務成功或失敗的消息。那麼當新leader,即新主選舉出來之後,新主上沒有這些事務也是正常的,客戶可以重做或取消這個事務,但原主庫的故障恢複後必須保證和新主庫相同的狀态,即事務一緻性,以保證主備的資料一緻性。是以在原主庫/網絡的故障消除後,重新加入叢集時,首先就要防止事務的不一緻。
我們在新架構的故障進行中引入分布式故障處理機制,在原主庫加入叢集對外服務之前,復原那些未傳送到其它節點的事務,進而確定其恢複到與新主庫被選舉出來的那個時刻。新主庫被選舉出來的時刻就是一個同步點,每個節點都将恢複或同步到那個同步點。新主從同步點開始之後就可以接收客戶的事務,并将其同步給新的備庫,當然也包括重新加入叢集的原主庫,隻是其角色變成了備庫。
如下圖所示:
另外,若是為了提升資料庫的吞吐能力,使用者通常會增加隻讀節點,那麼同樣的場景,若主庫的部分事務寫入本機的binlog,但尚未同步到備庫,更糟糕的是,這些事務已經同步到隻讀節點,此時若發生了主庫down機,備庫切換為主庫,悲劇發生了。一是隻讀庫可能會讀到髒資料,二是隻讀庫無法建立與新主庫的複制關系,因為他們之間的事務不一緻。幸運的是,MySQL金融版也完美的解決了這個問題,保證隻讀節點隻能複制并讀取被确認送出的事務。
傳統的主備叢集架構還存在了另一個隐患,通常我們會對主庫做備份,在異常情況下或業務擴充遷移時,可能需要恢複到指定時間點,而當主備庫切換後,可能會存在無法恢複到正确的時間點。
除此之外,基于新架構的高可用叢集還有更高的故障容忍性,并且可以将其中的備機開放出來,提供隻讀服務,提升系統整體的事務吞吐量。
這樣,MySQL以草根的資料庫形象,提供了企業級資料庫的可用性、可靠性和性能,為各類更高可用性要求的使用者提供了一個新的選擇,MySQL 金融版,你值的擁有。