# 1)請求對象的定制
# 2)擷取網頁的源碼
# 3)下載下傳
# 需求 下載下傳的前十頁的圖檔
# https://sc.chinaz.com/tupian/qinglvtupian.html 1
# https://sc.chinaz.com/tupian/qinglvtupian_page.html
import urllib.request
from lxml import etree
# 請求對象定制,實作
def create_request(page):
# 判斷頁碼,定制url
if(page == 1):
url = 'https://sc.chinaz.com/tupian/qinglvtupian.html'
else: # 字元串拼接,兩邊都要是字元串類型
url = 'https://sc.chinaz.com/tupian/qinglvtupian_' + str(page) + '.html'
# 請求頭
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36',
}
# 請求對象的定制(url參數傳遞,headers參數傳遞)
request = urllib.request.Request(url = url, headers = headers)
return request
# 擷取網頁源碼,實作
def get_content(request):
# 模拟浏覽器B,向伺服器S,發送請求
response = urllib.request.urlopen(request)
# 擷取響應資料(read讀方法傳回位元組形式二進制資料.decode解碼)
content = response.read().decode('utf-8')
return content
def down_load(content):
# 解析伺服器響應的檔案。用來解析字元串格式的HTML文檔對象,将傳進去的字元串轉變成 element 對象
tree = etree.HTML(content)
# xpath解析,圖檔名字
name_list = tree.xpath('//div[@id="container"]//a/img/@alt')
# xpath解析,圖檔位址
# 一般設計圖檔的網站都會進行懶加載,隻有當顯示到圖檔的位置src2——>才會變成src。是以要變之前擷取資料
src_list = tree.xpath('//div[@id="container"]//a/img/@src2')
# 周遊資料
for i in range(len(name_list)):
# 使用下标擷取清單的元素
name = name_list[i]
src = src_list[i]
# url拼接
url = 'https:' + src
# print(name,url)
# 下載下傳圖檔
# urllib.request.urlretrieve('圖檔位址','檔案的名字')
urllib.request.urlretrieve(url=url,filename='./loveImg/' + name + '.jpg')
# 程式入口
if __name__ == '__main__':
# 注意強制類型轉換
start_page = int(input('請輸入起始頁碼'))
end_page = int(input('請輸入結束頁碼'))
# 周遊
for page in range(start_page,end_page+1):
# (1) 請求對象的定制
request = create_request(page)
# (2)擷取網頁的源碼
content = get_content(request)
# (3)下載下傳
down_load(content)
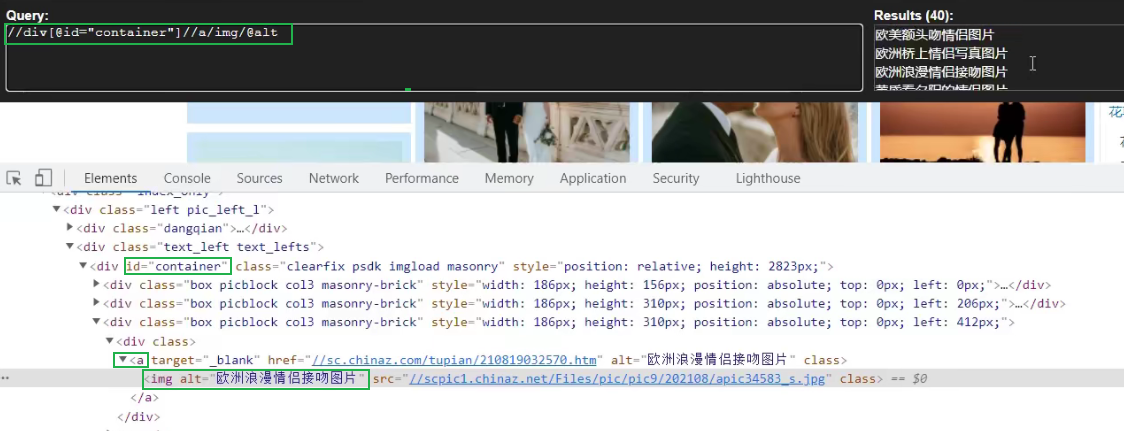 爬取-站長的圖檔素材
爬取-站長的圖檔素材 ![寶塔java項目部署日志路徑[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)