頭疼的問題
MaxCompute 使用者一個常見的問題是:同一個周期任務,為什麼最近幾天比之前慢了很多?或者為什麼之前都能按時産出的作業最近經常破線?
通常來說,引起作業執行變慢的原因有:quota 組資源不足、輸入資料量變動、資料分布情況變動、平台硬體故障引發重跑等。本文主要針對資料變動引起的作業慢問題,介紹使用者如何通過 MaxCompute Studio 的作業執行圖及作業詳情功能來自助定位問題。
MaxCompute Studio 登場
我們舉個例子來說。 下面是同一個任務分别在5月7日,5月9日的執行情況,下面分别稱為作業一、作業二:
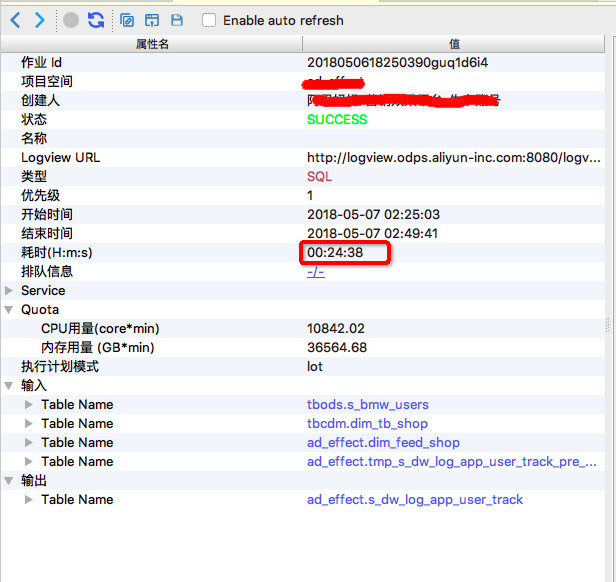
作業一,執行時長 24分38秒

作業二,執行時長 9分40秒
先來,對比下 SQL 和執行計劃
通常來說,進行兩次執行對比前,要先對比一下兩次執行的 SQL 腳本是否相同,如果在這之間使用者改動過作業腳本,就需要先分析改動的部分造成的影響。如果腳本内容一緻,随後還需要比較執行計劃是否一緻,可以通過 MaxCompute Studio 的作業執行計劃圖功能來分析(
參看文檔),可視化地看看兩次執行的計劃圖長得一樣不一樣。 (作業對比的功能正在開發中,下個版本的 Studio 中就可以一鍵對比兩個作業,标注出 SQL 腳本及其它部分的不同之處啦,敬請期待)
在上面這個例子中兩個作業的 SQL 腳本及執行計劃完全一緻,出于資料安全考慮,此處不粘貼具體 SQL 的内容。
再來,對比資料量
第二步要看一下作業輸入資料量有沒有明顯變化,有可能是某一天輸入表或分區的資料量暴漲導緻了作業執行變慢。作業輸入資料在 Detail 頁面左側,那裡列出了這個作業所有輸入的資料表和最終輸出的資料表。 展開 輸入->Table Name 可以檢視詳細資訊,包括是哪個 Fuxi 任務讀取了這個表,讀取了多少條記錄以及讀取的資料量大小。這些資訊,也标注在作業執行計劃圖 graph 上,友善檢視。如下圖所示,
作業一的輸入表及讀取資料
作業二的輸入表及讀取資料
也可以從graph上直接讀取輸入行數或者位元組數(預設展示行數,可在邊上右鍵切換為位元組數):
作業一 graph輸入行數
作業二 graph輸入行數
在這個例子中,從輸入資料量來看,兩次執行的輸入資料量差别不大。
作業回放是把利器
第三步,那到底作業運作情況是怎樣的呢?運作那麼長時間,或花費在哪兒了呢?不急,快快使用作業回放!
在 Studio 中作業執行計劃圖底部提供的作業回放工具條,允許使用者在 30 秒内快速回放作業執行進度的全過程!這樣我們就可以迅速地了解到底是哪個 Task 耗時最多,或者處理得資料最多,或者輸出的資料最多等等。
通過回放重制作業執行過程,Studio 提供進度圖以及熱度圖友善從不同次元進行作業分析。
作業一 進度圖回放
作業二 進度圖回放
從回放中可以看出
(1)J6_2_4_5 task是整個作業瓶頸,時間消耗最多,從task熱度圖中也能發現該節點明顯熱于其它節點。(時間熱度圖上越紅代表運作時間越長,資料熱度圖上越紅代表處理資料越多)
(2)同時對比兩個作業的回放過程,能夠比較明顯地發現作業一在J6_2_4_5運作時長要大于作業二,說明作業一在J6_2_4_5階段變慢了,初步懷疑有長尾節點産生。
接下來切換到時序圖tab,比較兩個作業的執行timeline:
作業一 執行timeline
作業二 執行timeline
雖然兩個作業timeline的時間尺度不同,但是可以明顯看出,作業一中J6_2_4_5 占了更長的比例,由此可以斷定是J6_2_4_5 在05-07執行(也就是作業一)發生可能長尾,導緻整個作業執行變慢。
進入深水區
第四步,通過graph或detail tab 對比J6_2_4_5 的輸入資料量
作業一 detail tab
作業二 detail tab
關注上圖中J6_2_4_5 輸入資料量和統計資訊,通過比較可看出,兩次執行的J6_2_4_5 輸入資料量基本相同,1.58萬億位元組 vs 1.7萬億位元組,從統計資訊來看,累計執行時間及平均時間也基本相同:292398 vs 307628, 72s vs 76s 但作業一 fuxi instances中的最長執行時間為710s, 由此可以認定是某幾個fuxi instance長尾導緻了J6_2_4_5 這個fuxi task的長尾。
第五步,對兩個 J6_2_4_5 fuxi instance 清單按照latency 排序:
作業一
作業二
或者轉到分析tab下的長尾頁面查找長尾節點:注意這個圖中的比例尺是以等比而不是等差方式标定的,是以,上面突出的比較長的毛刺就很可能是長尾的執行個體了。可以通過浮動視窗中的具體資訊來判斷。 另外 Studio 也提供了診斷的頁面,來自動找出超過平均執行個體執行時間兩倍的長尾執行個體。
從上面fuxi instance 輸入資料對比可以确定,因為J6_2_4_5#1912_0 這個instance 資料傾斜導緻整個作業一長尾。即J6_2_4_5#1912_0 是latency排第二的輸入資料量的7倍!
漸入佳境,刨根問底
第六步,檢視單個instance的執行日志,并通過job graph分析J6_2_4_5的具體執行計劃,找到導緻長尾的資料來源。
打開J6_2_4_5的operator graph, 可以看到有兩個join:Merge Join2和Merge Join3,這裡以Merge Join2為例展示如何查找資料來源。
從Merge Join2中可看到join key:_col13, user_id。 其中_col13 來自于J5, 點開J5後發現_col13來自IF(ISNULL(HOT_SELLER_MAP(sellerid)),sellerid,CONCAT(seller,TOSTRING(RAND()))) 說明_col13由seller決定,該seller來自于M4和M3。
J5 operator詳細資訊
分别打開M4和M3的Operator詳細資訊,可以看到seller 分别來自tmp_s_dw_log_app_user_track_pre_1_20180508 和dim_feed_shop。
M4 Operator詳細資訊
M3 Operator詳細資訊
同理可以分析出Merge Join2 的user_id 來自于dim_tb_shop。
最後,通過寫sql模拟産生對應的userid及_col13,比較這兩個字段的資料量大小,在針對sql腳本進行優化即可。sql腳本優化不在本文介紹範圍,是以不在此贅述。
回顧一下
有了 MaxCompute Studio 作業分析這樣趁手的工具,遇到各種 MaxCompute 作業的問題就不再束手無策了,甚至,咱們都沒有打開那 “讓人悲喜交加”的 Logview 不是?
聯系我們